
从零开始搓一个编译器
今年手痒痒选了一个Implementation of PL的课,需要徒手搓编译器。这里来小记一下这个过程,感觉这可能是我校CS最硬核的课之一了。
其实老师给了Racket和Python两种语言的选择,奈何我实在是不习惯那长到姥姥家的Racket括号,于是选择了Python。幸好在最新的Python 3.10中引入了match case的新特性,这直接使得代码量减少了非常多!它太好用了!!!(感觉Rust的compiler实现起来可能会更有趣一些)
源码目前放在这个repo里。里面将阶段性的进展都打上了tag。如若有人有兴趣的话可以去看看代码!我觉得我的代码质量还算凑合?
这个坑先开着,慢慢填!期末复习,可以开始填坑了。
这门课程主要focus在编译的过程(pass)上,而编译之前的一些处理,例如生成AST并没有cover,因为有自动化的工具可以在拥有语法定义的情况下自动生成AST。
开坑日期:2021-10-16
最近更新:2021-12-12
Overview
罗马不是一天建成的。 – 匿名
造轮子可真是太有趣了。 – 我
Features
这句话同样适用于编程语言,我们需要一步一步地为其增加新的Feature。
- $L_{Int}$: 整型及其计算和输出(
print) - $L_{Var}$: 引入变量及其赋值,同时可以接受输入(
input_int) - $L_{If}$: 引入
bool和ifstatement - $L_{While}$: 引入
while循环。这里没有涉及for,但是后者可以通过前者实现 - $L_{Tup}$: 引入
tuple,list可以通过前者实现 - $L_{Fun}$: 引入
function,同时支持尾调用优化 - $L_{Lambda}$: 引入
Lambda,支持了closure - $L_{Dyn}$: 支持动态类型
最终支持的语法如下:
Concrete Syntax

Abstract Syntax

虽然只是一个小的Python的子集,不过这货也就一课程作业了。
Passes
我们小学二年级就学过,compiler是由一堆pass组成的。在我的实现里面并没有对其做高于函数这个level的优化,所以每一个函数的编译都是independent的。这样就可以从更高层次对compile进行更好的控制。
class Compiler:
"""compile the whole program, and for each function, call methods in `CompileFunction`"""
# TODO: How to ref CompileFunction.arg_passing?
# num_arg_passing_regs = len(CompileFunction.arg_passing)
num_arg_passing_regs = 6
def __init__(self):
self.functions = []
# function -> CompileFunction instance
self.function_compilers = {}
# function -> {original_name: new_name}
self.function_limit_renames = {}
self.num_uniquified_counter = 0
class CompileFunction:
"""compile a single function"""
temp_count: int = 0
tup_temp_count: int = 0
# used for tracking static stack usage
normal_stack_count: int = 0
shadow_stack_count: int = 0
tuple_vars = []
# `calllq`: include first `arg_num` registers in its read-set R
arg_passing = [Reg(x) for x in arg_passing]
# `callq`: include all caller_saved registers in write-set W
caller_saved = [Reg(x) for x in caller_saved]
callee_saved = [Reg(x) for x in callee_saved]
builtin_functions = ['input_int', 'print', 'len']
builtin_functions = [Name(i) for i in builtin_functions]
def __init__(self, name: str):
self.name = name
self.basic_blocks = {}
# mappings from a single instruction to a set
self.read_set_dict = {}
self.write_set_dict = {}
self.live_before_set_dict = {}
self.live_after_set_dict = {}
# this list can be changed for testing spilling
self.allocatable = [Reg(x) for x in allocatable]
all_reg = [Reg('r11'), Reg('r15'), Reg('rsp'), Reg(
'rbp'), Reg('rax')] + self.allocatable
self.int_graph = UndirectedAdjList()
self.move_graph = UndirectedAdjList()
self.control_flow_graph = DirectedAdjList()
self.live_before_block = {}
self.prelude_label = self.name
# assign this when iterating CFG
self.conclusion_label = self.name + 'conclusion'
self.basic_blocks[self.conclusion_label] = []
# make the initial conclusion non-empty to avoid errors
# TODO: come up with a more elegant solution, maybe from `live_before_block`
# self.basic_blocks[self.conclusion_label] = [Expr(Call(Name('input_int'), []))]
# why need this?
self.sorted_control_flow_graph = []
self.used_callee = set()
self.stack_frame_size: int
self.shadow_stack_size: int
# Reserved registers
self.color_reg_map = {}
color_from = -5
for reg in all_reg:
self.color_reg_map[color_from] = reg
color_from += 1
shrink
把离散在源文件中不属于任何函数的语句汇集起来搓出一个main。
def shrink(self, p: Module) -> Module:
"""create main function, making the module body a series of function definitions"""
assert(isinstance(p, Module))
# main_args = arguments([], [], [], [], [])
main = FunctionDef('main', args=[], body=[],
decorator_list=[], returns=int)
new_module = []
for c in p.body:
match c:
case FunctionDef(name, _args, _body, _deco_list, _rv_type):
new_module.append(c)
self.functions.append(name)
# print("DEBUG, function: ", name, "args: ", args.args, body, _deco_list, _rv_type)
case stmt():
main.body.append(c)
main.body.append(Return(Constant(0)))
new_module.append(main)
print("DEBUG, new module: ", new_module)
return Module(new_module)
当前的实现没有支持global var,但是感觉应该不会太难。这里其实可以把离散在源文件中的变量定义都放在heap上面,使其能够被其他函数access。
uniquify
在函数中会存在variable shadowing的情况。为了使其更加清楚,我们对每一个variable在需要的时候重命名即可。
def uniquify(self, p: Module) -> Module:
class Uniquify(NodeTransformer):
def __init__(self, outer: Compiler, mapping: dict):
self.outer_instance = outer
self.uniquify_mapping = mapping
super().__init__()
def visit_Lambda(self, node):
self.generic_visit(node)
match node:
case Lambda(args, body_expr):
new_mapping = self.uniquify_mapping.copy()
new_args = []
for v in args:
new_v = v + "_" + str(self.outer_instance.num_uniquified_counter)
# find the new name in the previous mapping
new_mapping[new_mapping[v]] = new_v
# delete the old mapping
del new_mapping[v]
new_args.append(new_v)
self.outer_instance.num_uniquified_counter += 1
new_uniquifier = Uniquify(self.outer_instance, new_mapping)
new_body_expr = new_uniquifier.visit(body_expr)
return Lambda(new_args, new_body_expr)
case _:
return node
def visit_Name(self, node):
self.generic_visit(node)
match node:
case Name(id):
if id in self.uniquify_mapping:
return Name(self.uniquify_mapping[id])
else:
return node
case _:
return node
def do_uniquify(stmts: list, uniquify_mapping: dict) -> list:
"""change the variable names of statements in place according to the uniquify_mapping"""
uniquifier = Uniquify(self, uniquify_mapping)
new_body = []
for s in stmts:
new_body.append(uniquifier.visit(s))
return new_body
assert(isinstance(p, Module))
for f in p.body:
assert(isinstance(f, FunctionDef))
uniquify_mapping = {}
new_args = []
for v in f.args:
print("DEBUG, v: ", v[0], "type: ", type(v[0]))
new_arg_name = v[0] + "_" + str(self.num_uniquified_counter)
uniquify_mapping[v[0]] = new_arg_name
new_args.append((new_arg_name, v[1], ))
self.num_uniquified_counter += 1
f.args = new_args
f.body = do_uniquify(f.body, uniquify_mapping)
return p
reveal functions
Python里面的function是first class citizen,可以被当做变量来使用。故而在AST level它们是无法区别的。但是由于我们将函数赋值给一个变量时的语义和将其他东西(e.g. 数值,另一个变量的值)赋值给一个变量的语义是有区别的:前者实际上在获取函数的地而非函数体。因此需要将这两者区别开来,把所有在源码内定义的函数的引用从Name(XXX)转换为FunRef(XXX)。(FunRef是老师自己搓的一个AST node)。
def reveal_functions(self, p: Module) -> Module:
"""change `Name(f)` to `FunRef(f)` for functions defined in the module"""
class RevealFunction(NodeTransformer):
def __init__(self, outer: Compiler):
self.outer_instance = outer
super().__init__()
def visit_Call(self, node):
self.generic_visit(node)
match node:
case Call(Name(f), args) if f in self.outer_instance.functions:
# what if f is a builtin function? guard needed
return Call(FunRef(f), args)
case _:
return node
assert(isinstance(p, Module))
# Why this does't work?
# new_body = RevealFunction(self).visit_Call(p)
# p.body = new_body
for f in p.body:
new_body = []
for s in f.body:
new_line = RevealFunction(self).visit_Call(s)
new_body.append(new_line)
# print("DEBUG, new node: ", ast.dump(n))
f.body = new_body
return p
Convert Assignments
TODO
Convert to Closure
TODO
Limit Function
在一些函数的参数多余六个时,多出来的那些参数无法通过寄存器传递。通常的做法是放在stack上面,但是为了进行尾调用优化,我们可以将这些参数放在shadow stack(实际上是heap)上面。具体的做法是:为第六个和多余的参数创建一个tuple,并将这个tuple作为第六个参数传递。
def limit_functions(self, p: Module) -> Module:
"""limit functions to 6 arguments, anything more gets put into a 6th tuple-type argument"""
class LimitFunction(NodeTransformer):
# limit call sites & convert name of args
def __init__(self, outer: Compiler, mapping: dict = {}):
self.outer_instance = outer
self.mapping = mapping
super().__init__()
def visit_Name(self, node):
# substitute the >5th arguments with subscript of a tuple
self.generic_visit(node)
match node:
case Name(n) if n in self.mapping.keys():
return self.mapping[n]
case _:
return node
def visit_Call(self, node):
self.generic_visit(node)
match node:
case Call(FunRef(f), args) if len(args) > Compiler.num_arg_passing_regs:
# print("DEBUG, HIT in visit_FunRef: ", ast.dump(node))
new_args = args[:Compiler.num_arg_passing_regs - 1]
new_args.append(
Tuple(args[Compiler.num_arg_passing_regs - 1:], Load()))
return Call(FunRef(f), new_args)
case _:
return node
def args_need_limit(args):
if isinstance(args, list):
# print("DEBUG, args: ", args, type(args))
# print("DEBUG, argsAST: ", args[1][0])
return len(args) > Compiler.num_arg_passing_regs
# else:
# print("DEBUG, args: ", ast.dump(args))
return False
assert(isinstance(p, Module))
# limit defines
for f in p.body:
match f:
case FunctionDef(_name, args, _body, _deco_list, _rv_type) if args_need_limit(args):
# args = args.args
new_args = args[:5]
arg_tup = ('tup_arg', TupleType([a[1] for a in args[5:]]))
alias_mapping = {}
for i in range(5, len(args)):
alias_mapping[args[i][0]] = Subscript(
Name('tup_arg'), Constant(i - 5), Load())
print("DEBUG, alias_mapping: ", alias_mapping)
new_args.append(arg_tup)
print("DEBUG, new_args: ", new_args)
f.args = new_args
new_body = []
for s in f.body:
# new_line is new node
new_line = LimitFunction(
self, alias_mapping).visit_Name(s)
print("DEBUG, new_line: ", new_line)
new_body.append(new_line)
print("DEBUG, new_body: ", new_body)
f.body = new_body
case _:
assert(isinstance(f, FunctionDef))
new_body = []
for s in f.body:
new_line = LimitFunction(self).visit_Call(s)
new_body.append(new_line)
f.body = new_body
return p
因为tail call优化会抹掉当前function的stack frame,所以参数不再能够通过stack传递给callee。因此将多余的参数丢在shadow stack上面。
不过其实我感觉似乎也可以抹掉当前stack之后为callee准备参数,然后直接jump到callee里面(跳过stack initialization的部分)。但是老师提到说准备参数的时候可能会用到当前stack frame上面的东西,有mess up的可能性。不过似乎总是有解决思路的:例如可以先拓展一下当前的stack frame把callee的参数生成在一个干净的地方,然后再准备callee的stack frame:把自己的frame pop掉之后把callee的参数复制上去。不知道production compiler是怎么做的,说不定有更高效的办法。
Expose Allocation
我们选择将tuple存储在Heap上面,而将指向其的指针存储在一个shadow stack (root stack)上。这是为了在garbage collector更方便地去工作(之后细说)。这个pass只对tuple有效:将tuple的初始化变成一系列的statement,进而在最后用一个expression来为其赋值。
def expose_allocation_hide(self, t: Tuple) -> Begin:
# Autograder call `expose_allocation` in a wrong way, so this is hidden from the autograder
"""convert a tuple creation into a begin"""
assert(isinstance(t, Tuple))
content = t.elts
body = []
for i in range(len(content)):
if not CompileFunction.is_atm(content[i]):
print("DEBUG: ???")
temp_name = 'temp_tup' + \
str(self.tup_temp_count) + 'X' + str(i)
body.append(Assign([Name(temp_name)], content[i]))
tup_bytes = (len(content) + 1) * 8
if_cond = Compare(BinOp(GlobalValue('free_ptr'), Add(), Constant(tup_bytes)), [
Lt()], [GlobalValue('fromspace_end')])
# TODO: Expr(Constant(0)) OK here?
body.append(If(if_cond, [], [Collect(tup_bytes)]))
var = Name("pyc_temp_tup_" + str(self.tup_temp_count))
body.append(Assign([var], Allocate(len(content), t.has_type)))
for i in range(len(content)):
if not CompileFunction.is_atm(content[i]):
body.append(Assign([Subscript(var, Constant(i), Store())], Name(
'temp_tup' + str(self.tup_temp_count) + 'X' + str(i))))
else:
body.append(
Assign([Subscript(var, Constant(i), Store())], content[i]))
self.tup_temp_count += 1
return Begin(body, var)
这里需要注意的是,分配内存直到创建完这个tuple的过程需要是atomic的,因为分配的内存没有经过初始化,如果中间被插入了别的操作(which也进行了allocation)的话会出现memory corruption,具体应该是因为一些全局指针会跳飞。
Remove Complex Op*
这个pass将复杂的operation和oprand转换成若干更加简单的操作。例如加法的oprand需要是一个atom(e.g. 常数/变量)。
由于这个函数代码过长,可以参见repo。
def rco_exp(self, e: expr, need_atomic: bool) -> typing.Tuple[expr, Temporaries]:
temps = []
# tail must be assigned in the match cases
if CompileFunction.is_atm(e):
"""nothing need to do if it's already an `atm`"""
return (e, temps)
match e:
case XXX:
tail = YYY
return (tail, temps)
def rco_stmt(self, s: stmt) -> List[stmt]:
result = []
temps = []
match s:
case XXX:
self.rco_exp(XXX)
# late binding
for binding in temps:
# print("DEBUG, binding: ", binding)
result.append(Assign([binding[0]], binding[1]))
省下了每个case里面的一行return罢。这里需要递归地进行调用。
总而言之代码还是有不少优化的空间,也有一些冗余,但是相对而言还是尽可能在 readability 和 simplicity 上尽可能地区平衡了,至少我觉得我写的这些代码还是相当牛逼的。
Explicate Control
在这里就需要河里地编排程序的control flow了。我们小学三年级就学过,在一个函数有了不同的控制流之后,需要一些basic block来分摊具体的分支和循环,而 explicate control 就是做这个的。这个pass也是十分臃肿,代码就不贴了。但是 high level 来讲可以分解为五个主要的部分:
explicate_pred: 处理if和whileloop。这里还需要考虑if嵌套explicate_assign: 处理赋值。explicate_tail: 处理return。这里可以进行尾调用优化。explicate_effect: 处理其他只有 side-effect 的 expression,例如print(),未复制给某一个变量的input()(后者通常用来pause一个程序)。explicate_stmt: 将一个statement dispatch到以上的这些case中。
除此之外我还实现了 lazy evaluation 的优化:这样可以减少一些 trivial basic block,which只包含了单向的jmp。
Select Instruction
大多数都是brute force的操作:为每一个expression找到合适的X86_64指令。码长不贴。
在这里我有一个骚操作,但是我也不知道这种东西在compiler领域有没有专门的叫法,不过倒是可以借用late binding这个名字:即所有Assign statement 的 rhs 都先在select_expr()绑定到一个 Unnamed_Pyc_Var 上,然后再通过bound_unamed()根据 lhs 在rco_stmt()中进行绑定。这样做可以极大减少冗余代码(我觉得老师的代码太复杂了,看得人头大= =)。
我希望AST能够设计的再简单一些,现在还是有些太复杂了。
Register Allocation
Liveness Analysis
Interference Graph
Graph Coloring
Patch Instruction
Prelude and Conclusion
Something Interesting
这里是一些其他用到的技术,不知道有没有时间细表,不过可以先把坑挖上。
Dynamic Typing
Garbage Collection
因为使用 heap 来存放tuple,所以需要GC。为此设置了一个 root stack(shadow stack),用来存放所有的 tuple pointers。
内存的形状是这样的:
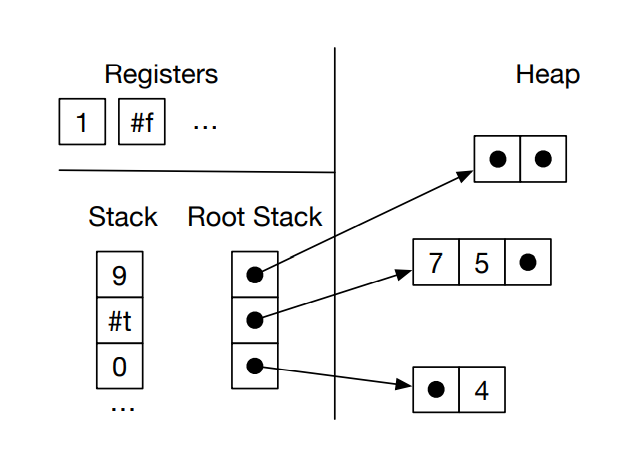
把 tuple 都丢到shadow stack上面的原因是:GC需要一个 starting point 来捡垃圾,这个 shadow stack就是所谓 starting point。确切地说应该所有需要 garbage collection 的玩意都应该丢在那里。
GC会寻找所有能够通过 shadow stack索引到的元素来保证它们不会被 collect,而那些找不到的就命途多舛了。能够被索引到的元素包括:root stack 中 pointer 指向的元素,以及 recursively 这些被指向元素中的 pointer 能够指向的元素。那么这就带来了一些问题:如果有一些元素被指向两次怎么办?如果有一些指针指成环儿了怎么办?
所以实际上 tuple 在内存中的形状是这样的:
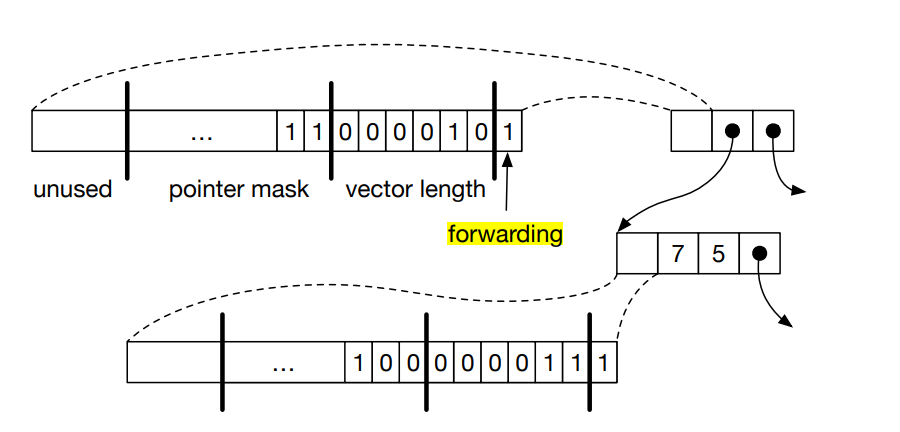
tuple中的第一个 double word 来存储一些元数据,包括:
- pointer mask: 表示 tuple 当中的那些是 pointer
- vector length: 表示 tuple 的长度
- forwarding: 在GC工作的时候来标记有没有被处理过
具体的GC算法 Two-Space Copying。从字面意思上而言还是很好理解的,这里不多赘述了。详情可以参考 Wiki。我读了一下这玩意的C实现,可以说是十分蛋痛了。虽然写的不算复杂,但是我如果不懂这个算法是啥的话还真的很难看出来这是个GC(可能是没经验吧)。
由于GC的引入,需要做一些额外的事情:在程序开始执行时初始化 shadow stack;reserve 一个寄存器(r15)来用作 shadow stack 的指针;再 reserve 一个寄存器(r11)作为 tuple access 的指针(因为X86要求memory write 通过寄存器实现,而rax之前用在了 instruction patching 中来避免两个 oprand 都是内存的情况,故而无法复用在 tuple 这里);在分配空间前检查够不够用,不够的话还需要 allocate。

留下评论