def build(
inputs: Union[schedule.Schedule, PrimFunc, IRModule, Mapping[str, IRModule]],
args: Optional[List[Union[Buffer, tensor.Tensor, Var]]] = None,
target: Optional[Union[str, Target]] = None,
target_host: Optional[Union[str, Target]] = None,
name: Optional[str] = "default_function",
binds: Optional[Mapping[tensor.Tensor, Buffer]] = None,
):
"""Build a function with arguments as signature. Code will be generated
for devices coupled with target information.
Parameters
----------
inputs : Union[tvm.te.schedule.Schedule, tvm.tir.PrimFunc, IRModule, Mapping[str, IRModule]]
The input to be built
args : Optional[List[Union[tvm.tir.Buffer, tensor.Tensor, Var]]]
The argument lists to the function.
target : Optional[Union[str, Target]]
The target and option of the compilation.
target_host : Optional[Union[str, Target]]
Host compilation target, if target is device.
When TVM compiles device specific program such as CUDA,
we also need host(CPU) side code to interact with the driver
setup the dimensions and parameters correctly.
target_host is used to specify the host side codegen target.
By default, llvm is used if it is enabled,
otherwise a stackvm intepreter is used.
name : Optional[str]
The name of result function.
binds : Optional[Mapping[tensor.Tensor, tvm.tir.Buffer]]
Dictionary that maps the binding of symbolic buffer to Tensor.
By default, a new buffer is created for each tensor in the argument.
Returns
-------
ret : tvm.module
A module that combines both host and device code.
Examples
________
There are two typical example uses of this function depending on the type
of the argument `inputs`:
1. it is an IRModule.
.. code-block:: python
n = 2
A = te.placeholder((n,), name='A')
B = te.placeholder((n,), name='B')
C = te.compute(A.shape, lambda *i: A(*i) + B(*i), name='C')
s = tvm.te.create_schedule(C.op)
m = tvm.lower(s, [A, B, C], name="test_add")
rt_mod = tvm.build(m, target="llvm")
2. it is a dict of compilation target to IRModule.
.. code-block:: python
n = 2
A = te.placeholder((n,), name='A')
B = te.placeholder((n,), name='B')
C = te.compute(A.shape, lambda *i: A(*i) + B(*i), name='C')
s1 = tvm.te.create_schedule(C.op)
with tvm.target.cuda() as cuda_tgt:
s2 = topi.cuda.schedule_injective(cuda_tgt, [C])
m1 = tvm.lower(s1, [A, B, C], name="test_add1")
m2 = tvm.lower(s2, [A, B, C], name="test_add2")
rt_mod = tvm.build({"llvm": m1, "cuda": m2}, target_host="llvm")
Note
----
See the note on :any:`tvm.target` on target string format.
"""
if isinstance(inputs, schedule.Schedule):
if args is None:
raise ValueError("args must be given for build from schedule")
input_mod = lower(inputs, args, name=name, binds=binds)
elif isinstance(inputs, (list, tuple, container.Array)):
merged_mod = tvm.IRModule({})
for x in inputs:
merged_mod.update(lower(x))
input_mod = merged_mod
elif isinstance(inputs, (tvm.IRModule, PrimFunc)):
input_mod = lower(inputs)
elif not isinstance(inputs, (dict, container.Map)):
raise ValueError(
f"Inputs must be Schedule, IRModule or dict of target to IRModule, "
f"but got {type(inputs)}."
)
if not isinstance(inputs, (dict, container.Map)):
target = Target.current() if target is None else target
target = target if target else "llvm"
target_input_mod = {target: input_mod}
else:
target_input_mod = inputs
for tar, mod in target_input_mod.items():
if not isinstance(tar, (str, Target)):
raise ValueError("The key of inputs must be str or " "Target when inputs is dict.")
if not isinstance(mod, tvm.IRModule):
raise ValueError("inputs must be Schedule, IRModule," "or dict of str to IRModule.")
target_input_mod, target_host = Target.check_and_update_host_consist(
target_input_mod, target_host
)
if not target_host:
for tar, mod in target_input_mod.items():
tar = Target(tar)
device_type = ndarray.device(tar.kind.name, 0).device_type
if device_type == ndarray.cpu(0).device_type:
target_host = tar
break
if not target_host:
target_host = "llvm" if tvm.runtime.enabled("llvm") else "stackvm"
target_input_mod, target_host = Target.check_and_update_host_consist(
target_input_mod, target_host
)
mod_host_all = tvm.IRModule({})
device_modules = []
for tar, input_mod in target_input_mod.items():
mod_host, mdev = _build_for_device(input_mod, tar, target_host)
mod_host_all.update(mod_host)
device_modules.append(mdev)
# Generate a unified host module.
rt_mod_host = codegen.build_module(mod_host_all, target_host)
# Import all modules.
for mdev in device_modules:
if mdev:
rt_mod_host.import_module(mdev)
if not isinstance(target_host, Target):
target_host = Target(target_host)
if (
target_host.attrs.get("runtime", tvm.runtime.String("c++")) == "c"
and target_host.attrs.get("system-lib", 0) == 1
):
if target_host.kind.name == "c":
create_csource_crt_metadata_module = tvm._ffi.get_global_func(
"runtime.CreateCSourceCrtMetadataModule"
)
to_return = create_csource_crt_metadata_module([rt_mod_host], target_host)
elif target_host.kind.name == "llvm":
create_llvm_crt_metadata_module = tvm._ffi.get_global_func(
"runtime.CreateLLVMCrtMetadataModule"
)
to_return = create_llvm_crt_metadata_module([rt_mod_host], target_host)
else:
to_return = rt_mod_host
return OperatorModule.from_module(to_return, ir_module_by_target=target_input_mod, name=name)wasm_memory_init_with_pool(void *mem, unsigned int bytes)
{
mem_allocator_t _allocator = mem_allocator_create(mem, bytes);
if (_allocator) {
memory_mode = MEMORY_MODE_POOL;
pool_allocator = _allocator;
global_pool_size = bytes;
return true;
}
LOG_ERROR("Init memory with pool (%p, %u) failed.\n", mem, bytes);
return false;
}mem_allocator_t mem_allocator_create(void *mem, uint32_t size)
{
return gc_init_with_pool((char *) mem, size);
}gc_init_with_pool
The previous function invokes this one:
gc_handle_t
gc_init_with_pool(char *buf, gc_size_t buf_size)
{
char *buf_end = buf + buf_size;
char *buf_aligned = (char*)(((uintptr_t) buf + 7) & (uintptr_t)~7);
char *base_addr = buf_aligned + sizeof(gc_heap_t);
gc_heap_t *heap = (gc_heap_t*)buf_aligned;
gc_size_t heap_max_size;
if (buf_size < APP_HEAP_SIZE_MIN) {
os_printf("[GC_ERROR]heap init buf size (%u) < %u\n",
buf_size, APP_HEAP_SIZE_MIN);
return NULL;
}
base_addr = (char*) (((uintptr_t) base_addr + 7) & (uintptr_t)~7) + GC_HEAD_PADDING;
heap_max_size = (uint32)(buf_end - base_addr) & (uint32)~7;
return gc_init_internal(heap, base_addr, heap_max_size);
}and invokes the internal implementation:
static gc_handle_t
gc_init_internal(gc_heap_t *heap, char *base_addr, gc_size_t heap_max_size)
{
hmu_tree_node_t *root = NULL, *q = NULL;
int ret;
memset(heap, 0, sizeof *heap);
memset(base_addr, 0, heap_max_size);
ret = os_mutex_init(&heap->lock);
if (ret != BHT_OK) {
os_printf("[GC_ERROR]failed to init lock\n");
return NULL;
}
/* init all data structures*/
heap->current_size = heap_max_size;
heap->base_addr = (gc_uint8*)base_addr;
heap->heap_id = (gc_handle_t)heap;
heap->total_free_size = heap->current_size;
heap->highmark_size = 0;
root = &heap->kfc_tree_root;
memset(root, 0, sizeof *root);
root->size = sizeof *root;
hmu_set_ut(&root->hmu_header, HMU_FC);
hmu_set_size(&root->hmu_header, sizeof *root);
q = (hmu_tree_node_t *) heap->base_addr;
memset(q, 0, sizeof *q);
hmu_set_ut(&q->hmu_header, HMU_FC);
hmu_set_size(&q->hmu_header, heap->current_size);
hmu_mark_pinuse(&q->hmu_header);
root->right = q;
q->parent = root;
q->size = heap->current_size;
bh_assert(root->size <= HMU_FC_NORMAL_MAX_SIZE);
#if WASM_ENABLE_MEMORY_TRACING != 0
os_printf("Heap created, total size: %u\n", buf_size);
os_printf(" heap struct size: %u\n", sizeof(gc_heap_t));
os_printf(" actual heap size: %u\n", heap_max_size);
os_printf(" padding bytes: %u\n",
buf_size - sizeof(gc_heap_t) - heap_max_size);
#endif
return heap;
}PLDI'16
Hardware support for isolated execution (such as Intel SGX) enables development of applications that keep their code and data confidential even while running in a hostile or compromised host. However, automatically verifying that such applications satisfy confidentiality remains challenging. We present a methodology for designing such applications in a way that enables certifying their confidentiality. Our methodology consists of forcing the application to communicate with the external world through a narrow interface, compiling it with runtime checks that aid verification, and linking it with a small runtime that implements the narrow interface. The runtime includes services such as secure communication channels and memory management. We formalize this restriction on the application as Information Release Confinement (IRC), and we show that it allows us to decompose the task of proving confidentiality into (a) one-time, human-assisted functional verification of the runtime to ensure that it does not leak secrets, (b) automatic verification of the application's machine code to ensure that it satisfies IRC and does not directly read or corrupt the runtime's internal state. We present /CONFIDENTIAL: a verifier for IRC that is modular, automatic, and keeps our compiler out of the trusted computing base. Our evaluation suggests that the methodology scales to real-world applications.
Purpose
- Protect IRC: to prevent info leakage
- WCFI-RW: weak form of control-flow integrity, and along with restrictions on reads and writes
- Formally verify a set of checks to enforce WCFI-RW in SIRs
- Not to depend on a specific compiler, which is not in the TCB
Threat model
- Application U (in SIR) is not malicious but may contain bugs
- U may also use third-party libraries
- The system other than SIR is hostile/compromised
Design
- U and libraries(L) are verified separately
- U can only use L to
sendandrecvdata outside of SIR
Method
- Establish a formal model of U's syntax
- Define what an adversary can do under this threat model, formally
- Define the target (confidentiality)
- Deduce the properties required for WCFI-RW, both for applications and libraries
- Derive and instrument checks in code
- Verify the properties still hold.
Notice that
- These checks derived from the properties ensures WCFI-RW
- The verification may scale
Insights
- The library may also compromise the app
- No check of jump into the middle of instrumentation(s)
- Assumes the page permissions can be changed
- Only needs SP is in U???
Abstract
Recent proposals for trusted hardware platforms, such as Intel SGX and the MIT Sanctum processor, offer compelling security features but lack formal guarantees. We introduce a verification methodology based on a trusted abstract platform (TAP), a formalization of idealized enclave platforms along with a parameterized adversary. We also formalize the notion of secure remote execution and present machine-checked proofs showing that the TAP satisfies the three key security properties that entail secure remote execution: integrity, confidentiality and secure measurement. We then present machine-checked proofs showing that SGX and Sanctum are refinements of the TAP under certain parameterizations of the adversary, demonstrating that these systems implement secure enclaves for the stated adversary models.
Methodology
The enclave is formally modeled, including the program, state (e.g., memory, cache, registers), I/O, execution, and adversaries. The adversaries with privilege, cache access, and memory access are modeled differently.
A trusted abstract platform (TAP) is built for modeling secure remote execution (SRE), which is defined formally and can be meet by satisfying three properties at the same time: Secure Measurement, Integrity, Confidentiality.
Then, to prove that Sanctum and SGX satisfies SRE, the authors prove these architectures refine TAP in Boogie, and therefore meets SRE.
Strength
- Side-channel and Side-channel attackers are modeled
- TAP is a general model for various TEEs
- Formal proof
Weakness
- The refinement is not accurate enough, i.e., remote attestation seems missing
- Source code?
Abstract
In this paper we present a novel solution that combines the capabilities of Large Language Models (LLMs) with Formal Verification strategies to verify and automatically repair software vulnerabilities. Initially, we employ Bounded Model Checking (BMC) to locate the software vulnerability and derive a counterexample. The counterexample provides evidence that the system behaves incorrectly or contains a vulnerability. The counterexample that has been detected, along with the source code, are provided to the LLM engine. Our approach involves establishing a specialized prompt language for conducting code debugging and generation to understand the vulnerability's root cause and repair the code. Finally, we use BMC to verify the corrected version of the code generated by the LLM. As a proof of concept, we create ESBMC-AI based on the Efficient SMT-based Context-Bounded Model Checker (ESBMC) and a pre-trained Transformer model, specifically gpt-3.5-turbo, to detect and fix errors in C programs. Our experimentation involved generating a dataset comprising 1000 C code samples, each consisting of 20 to 50 lines of code. Notably, our proposed method achieved an impressive success rate of up to 80% in repairing vulnerable code encompassing buffer overflow and pointer dereference failures. We assert that this automated approach can effectively incorporate into the software development lifecycle's continuous integration and deployment (CI/CD) process.
Summarize
This paper interface LLM with BMC (Bounded model checking) to conform bugs in C code. BMC (based on SMT solver) improves the arithmetic performance, which is not good in LLM. However, I tested the cases which said to fail in LLM on GPT 4 (Ver Aug. 3) whereas it could find the vulnerability, and this is inconsistent with the paper.
The evaluation uses 1000 cases generated by LLM. It's still unclear if such methodology is applicable to very large code base/functions or on real world code base.
EuroSys'16 Best Paper
This paper supports the author's following work, graphene(-SGX).
Targeted Interfaces (APIs)
- System Calls
- Proc Filesystem
Method
- Measured the download and dependency data of packages in Ubuntu 15.04.
- Statically analyzed what syscalls will be invoked in a package and what path will be accessed by a binary (hardcoded string)
Measurement
- API Importance: A Metric for Individual APIs
- Weighted Completeness: A System-Wide Metric (combined with #downloads)
Questions Answered
- Which syscalls are more important than others?
- Which syscalls can be deprecated? (some are rarely used)
- Which syscalls should be supported for compatibility?




Abstract
Hardware-assisted memory encryption offers strong confidentiality guarantees for trusted execution environments like Intel SGX and AMD SEV. However, a recent study by Li et al. presented at USENIX Security 2021 has demonstrated the CipherLeaks attack, which monitors ciphertext changes in the special VMSA page. By leaking register values saved by the VM during context switches, they broke state-of-the-art constant-time cryptographic implementations, including RSA and ECDSA in the OpenSSL. In this paper, we perform a comprehensive study on the ciphertext side channels. Our work suggests that while the CipherLeaks attack targets only the VMSA page, a generic ciphertext side-channel attack may exploit the ciphertext leakage from any memory pages, including those for kernel data structures, stacks and heaps. As such, AMD’s existing countermeasures to the CipherLeaks attack, a firmware patch that introduces randomness into the ciphertext of the VMSA page, is clearly insufficient. The root cause of the leakage in AMD SEV’s memory encryption—the use of a stateless yet unauthenticated encryption mode and the unrestricted read accesses to the ciphertext of the encrypted memory—remains unfixed. Given the challenges faced by AMD to eradicate the vulnerability from the hardware design, we propose a set of software countermeasures to the ciphertext side channels, including patches to the OS kernel and cryptographic libraries. We are working closely with AMD to merge these changes into affected open-source projects.
Background
- CipherLeak: ciphertext can be accessed by the hypervisor
- In SEV, XEX encryption mode is applied => for a fixed address, same plaintext yields same ciphertext
- Controlled side-channel: NPT (nested page table) present bit clear => PF
- Before SEV-ES, the registers are saved without encryption
- SNP: hypervisor cannot modify or remap guest VM pages (integrity protection)
Attack
- Nginx SSL key generation -> 384bit ECDSA key recovery
This exploits constant time swap algorithm. A decision bit encryption pattern is observed, and therefore the nonce could be derived by observing the mask in 384 iterations.
This paper analyzes the vulnerability space arising in Trusted Execution Environments (TEEs) when interfacing a trusted enclave application with untrusted, potentially malicious code. Considerable research and industry effort has gone into developing TEE runtime libraries with the purpose of transparently shielding enclave application code from an adversarial environment. However, our analysis reveals that shielding requirements are generally not well-understood in real-world TEE runtime implementations. We expose several sanitization vulnerabilities at the level of the Application Binary Interface (ABI) and the Application Programming Interface (API) that can lead to exploitable memory safety and side-channel vulnerabilities in the compiled enclave. Mitigation of these vulnerabilities is not as simple as ensuring that pointers are outside enclave memory. In fact, we demonstrate that state-of-the-art mitigation techniques such as Intel's edger8r, Microsoft's "deep copy marshalling", or even memory-safe languages like Rust fail to fully eliminate this attack surface. Our analysis reveals 35 enclave interface sanitization vulnerabilities in 8 major open-source shielding frameworks for Intel SGX, RISC-V, and Sancus TEEs. We practically exploit these vulnerabilities in several attack scenarios to leak secret keys from the enclave or enable remote code reuse. We have responsibly disclosed our findings, leading to 5 designated CVE records and numerous security patches in the vulnerable open-source projects, including the Intel SGX-SDK, Microsoft Open Enclave, Google Asylo, and the Rust compiler.
ABI vulnerabilities
- Entry status flags sanitization
- Entry stack pointer restore
- Exit register leakage
API vulnerabilities
- Missing pointer range check
- Null-terminated string handling
- Integer overflow in range check
- Incorrect pointer range check
- Double fetch untrusted pointer
- Ocall return value not checked
- Uninitialized padding leakage
Targets
- SGX-SDK
- OpenEnclave
- Graphene
- SGX-LKL
- Rust-EDP
- Asylo
- Keystone
- Sancus
that legacy applications may also make implicit assumptions on the validity of argv and envp pointers, which are not the result of system calls.
WebAssembly in SGX
Remote computation has numerous use cases such as cloud computing, client-side web applications or volunteer computing. Typically, these computations are executed inside a sandboxed environment for two reasons: first, to isolate the execution in order to protect the host environment from unauthorised access, and second to control and restrict resource usage. Often, there is mutual distrust between entities providing the code and the ones executing it, owing to concerns over three potential problems: (i) loss of control over code and data by the providing entity, (ii) uncertainty of the integrity of the execution environment for customers, and (iii) a missing mutually trusted accounting of resource usage.
In this paper we present AccTEE, a two-way sandbox that offers remote computation with resource accounting trusted by consumers and providers. AccTEE leverages two recent technologies: hardware-protected trusted execution environments, and Web-Assembly, a novel platform independent byte-code format. We show how AccTEE uses automated code instrumentation for fine-grained resource accounting while maintaining confidentiality and integrity of code and data. Our evaluation of AccTEE in three scenarios – volunteer computing, serverless computing, and pay-by-computation for the web – shows a maximum accounting overhead of 10%.
sec'20
Abstract
Content Delivery Networks (CDNs) serve a large and increasing portion of today’s web content. Beyond caching, CDNs provide their customers with a variety of services, including protection against DDoS and targeted attacks. As the web shifts from HTTP to HTTPS, CDNs continue to provide such services by also assuming control of their customers’ private keys, thereby breaking a fundamental security principle: private keys must only be known by their owner.
We present the design and implementation of Phoenix, the first truly “keyless CDN”. Phoenix uses secure enclaves (in particular Intel SGX) to host web content, store sensitive key material, apply web application firewalls, and more on otherwise untrusted machines. To support scalability and multitenancy, Phoenix is built around a new architectural primitive which we call conclaves: containers of enclaves. Conclaves make it straightforward to deploy multi-process, scalable, legacy applications. We also develop a filesystem to extend the enclave’s security guarantees to untrusted storage. In its strongest configuration, Phoenix reduces the knowledge of the edge server to that of a traditional on-path HTTPS adversary. We evaluate the performance of Phoenix with a series of micro- and macro-benchmarks.
Challenges
- Support for multi-tenants
- Legacy App
- Bootstrapping trust
Comments
- Scalable
- Curious/Byzantine Threat Model
- All Goals achieved separately by previous work
chmod 600 ./id_rsa*
# or
chmod 644 ./id_rsa.pub
eval $(ssh-agent -s)
ssh-add ~/.ssh/id_rsaAbstract
Memory access bugs, including buffer overflows and uses of freed heap memory, remain a serious problem for programming languages like C and C++. Many memory error detectors exist, but most of them are either slow or detect a limited set of bugs, or both.
This paper presents AddressSanitizer, a new memory error detector. Our tool finds out-of-bounds accesses to heap, stack, and global objects, as well as use-after-free bugs. It employs a specialized memory allocator and code instrumentation that is simple enough to be implemented in any compiler, binary translation system, or even in hardware.
AddressSanitizer achieves efficiency without sacrificing comprehensiveness. Its average slowdown is just 73% yet it accurately detects bugs at the point of occurrence. It has found over 300 previously unknown bugs in the Chromium browser and many bugs in other software.

Goods
- Tracking of valid memory via shadow mapping
- Checks done via instrumentation
- Stack/heal object awareness
- No FP
Bads
- Still mild overhead
- Can miss some bugs (redzones might be skipped)
Questions
- Why this work is SO influential?
USENIX'20
Kernel-mode drivers are challenging to analyze for vulnerabilities, yet play a critical role in maintaining the security of OS kernels. Their wide attack surface, exposed via both the system call interface and the peripheral interface, is often found to be the most direct attack vector to compromise an OS kernel. Researchers therefore have proposed many fuzzing techniques to find vulnerabilities in kernel drivers. However, the performance of kernel fuzzers is still lacking, for reasons such as prolonged execution of kernel code, interference between test inputs, and kernel crashes.
This paper proposes lightweight virtual machine checkpointing as a new primitive that enables high-throughput kernel driver fuzzing. Our key insight is that kernel driver fuzzers frequently execute similar test cases in a row, and that their performance can be improved by dynamically creating multiple checkpoints while executing test cases and skipping parts of test cases using the created checkpoints. We built a system, dubbed Agamotto, around the virtual machine checkpointing primitive and evaluated it by fuzzing the peripheral attack surface of USB and PCI drivers in Linux. The results are convincing. Agamotto improved the performance of the state-of-the-art kernel fuzzer, Syzkaller, by 66.6% on average in fuzzing 8 USB drivers, and an AFL-based PCI fuzzer by 21.6% in fuzzing 4 PCI drivers, without modifying their underlying input generation algorithm.
Design
- Using checkpoints to store state and restore the state => accelerate fuzzing


Papers
Confidential Computing within an AI Accelerator
We present IPU Trusted Extensions (ITX), a set of hardware extensions that enables trusted execution environments in Graphcore’s AI accelerators. ITX enables the execution of AI workloads with strong confidentiality and integrity guarantees at low performance overheads. ITX isolates workloads from untrusted hosts, and ensures their data and models remain encrypted at all times except within the accelerator’s chip. ITX includes a hardware root-of-trust that provides attestation capabilities and orchestrates trusted execution, and on-chip programmable cryptographic engines for authenticated encryption of code/data at PCIe bandwidth.
We also present software for ITX in the form of compiler and runtime extensions that support multi-party training without requiring a CPU-based TEE.
We included experimental support for ITX in Graphcore’s GC200 IPU taped out at TSMC’s 7nm node. Its evaluation on a development board using standard DNN training workloads suggests that ITX adds < 5% performance overhead and delivers up to 17x better performance compared to CPU-based confidential computing systems based on AMD SEV-SNP.
Attack: Function (Call) sequence can be modified by an untrusted attacker.
Solution: hash chain built by trusted functions, which can be verified by the user.
Not a very interesting paper.

Abstract
Recent advances of Large Language Models (LLMs), e.g., ChatGPT, exhibited strong capabilities of comprehending and responding to questions across a variety of domains. Surprisingly, ChatGPT even possesses a strong understanding of program code. In this paper, we investigate where and how LLMs can assist static analysis by asking appropriate questions. In particular, we target a specific bug-finding tool, which produces many false positives from the static analysis. In our evaluation, we find that these false positives can be effectively pruned by asking carefully constructed questions about function-level behaviors or function summaries. Specifically, with a pilot study of 20 false positives, we can successfully prune 8 out of 20 based on GPT-3.5, whereas GPT-4 had a near-perfect result of 16 out of 20, where the four failed ones are not currently considered/supported by our questions, e.g., involving concurrency. Additionally, it also identified one false negative case (a missed bug). We find LLMs a promising tool that can enable a more effective and efficient program analysis.
Noticeable Points
Prompt Design
- Chain of Thought: Step-by-step result
- Task decomposition: breaking down the huge tasks into smaller pieces
- Progressive prompt: interactively feed information
Challenges in traditional code analysis
- Inherent Knowledge Boundaries.
Static analysis requires domain knowledge to model special functions which cannot be analyzed. E.g., assembly code, hardware behaviors, concurrency, and compiler built-ins.
- Exhaustive Path Exploration.
Research Papers
Attacks
- A New Era in LLM Security: Exploring Security Concerns in Real-World LLM-based Systems
- A First Look at GPT Apps: Landscape and Vulnerability steals system prompt/files
- LLM Platform Security: Applying a Systematic Evaluation Framework to OpenAI’s ChatGPT Plugins
- Demystifying RCE Vulnerabilities in LLM-Integrated Apps RCE based on prompts
Defense

MISC
Previous Attack
Jailbreak
Images


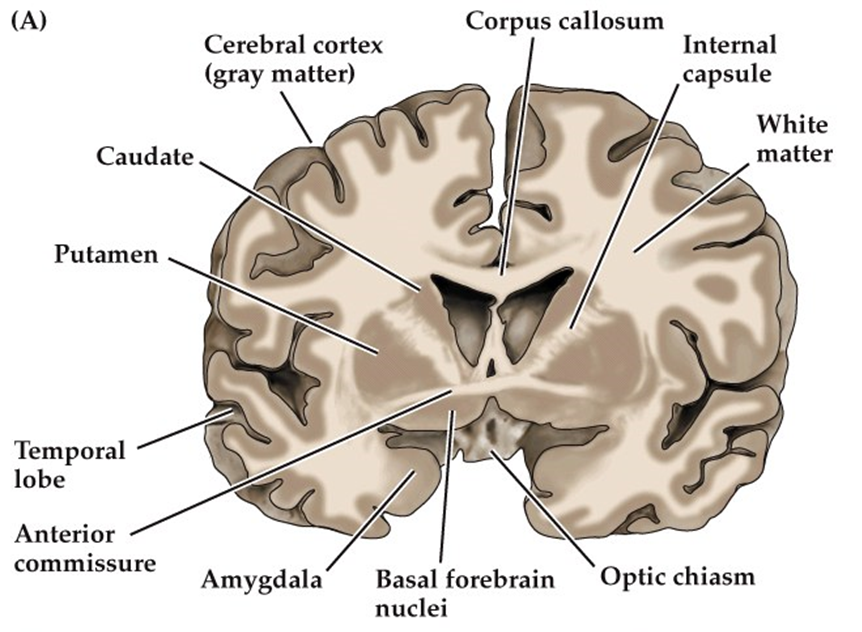
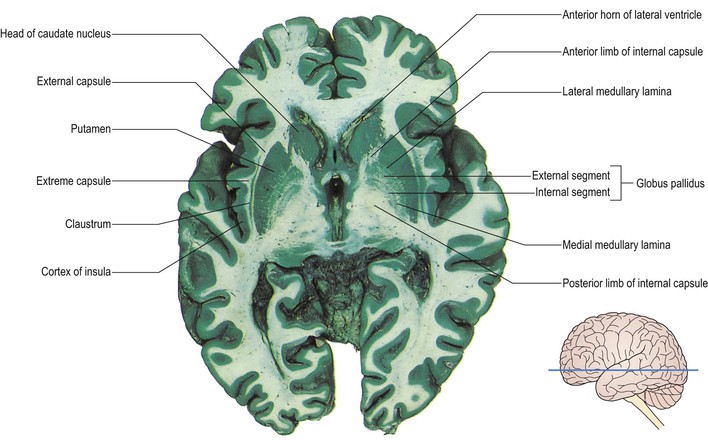
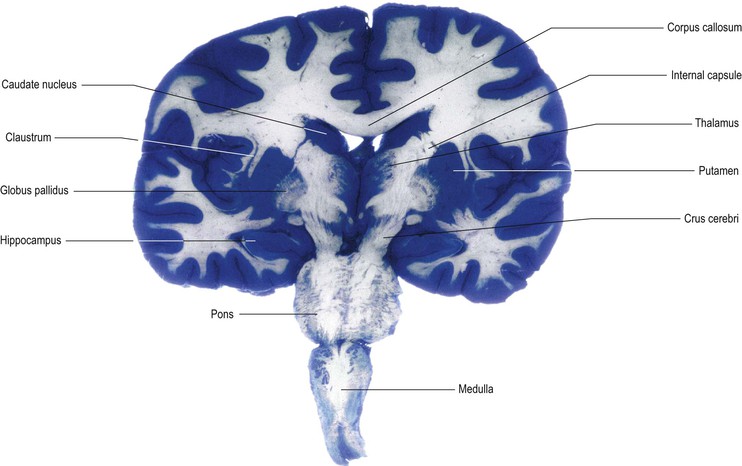

Functions of Caudate
Visual
- Anterior portion of caudate connected with lateral and medial prefrontal cortices and involved with working memory and executive function (cognitive and emotional portion)
- Tail of caudate interacts with inferior temporal lobe to process visual information and movement control (lesions can impair visual discrimination of objects).
- Receives topographic visual input from cortex, integrates it and inhibits substantia nigra, which disinhibits the superior colliculus to enable coordinated eye movements.
Associative learning
- Connecting visual stimuli with motor responses and learning with feedback
- Body and tail are associated with learning acquisition, while to head is involved with processing feedback on learning trials.
- Right caudate has numerous connections with hippocampus that correlates with memory competitions
- Medial dorsal striatum involved with working memory, and formation of certain memories.
Clinical Significance
- Degree of dementia and performance in PD correlates with loss of dopaminergic neurons projecting to caudate.
- Early deficits in working memory in PD associated with caudate dysfunction.
- Decreases in caudate bloodflow associated with cognitive impairment seen in HIV.
- Volume of caudate decreased in several forms of dementia (less in AD than other types of dementia)
- Impulse control and hyperactivity roles: activity increased in manic state of bipolar; left caudate volume correlates with severity of obsessive-compulsive disorder. Volumetric differences in those with ADHD compared with controls.
- Schizophrenia: volumes are reduced, and increase with drug threrapy.
Putamen
- Learning and motor control, including speech articulation, reward, addiction
- Susceptible to infarction because of vasculature
- Dopamine depletion results in many symptoms of PD
- Changes in volume linked to bipolar, Tourette syndrome, ADHD, ASD, schizophrenia.
- Greater volume in bilinguals than monolinguals
- Volume inversely correlated with emotion recognition in faces
- Involved with mother’s recognition of own infant.
Substantia Nigra
- Midbrain dopaminergic nucleus
- Modulates motor function and reward
- Projections from SN to putamen (the nigrostriatal pathway) is highly implicated in PD
- SN divided into two subsections: the pars compacta (SNpc) and the pars reticulata (SNpr)
- SNpc contains dominergic neurons: dark in color because of high amount of neuromelanin which forms the precursor to dopamine (L-dopa).
- SNpr contains inhibitory GABA neurons
Direct and Indirect pathways of the Basal Ganglia


- SNpc has Dopaminergic projections to striatum, these synapse on D1 DA receptors and D2 DA receptors.
- The D1 receptors in striatum synapse on internal Globus Pallidus forming the direct pathway of the basal ganglia.
- The D2 neurons project to external GP which inhibit the stimulatory subthalamic nuclei that synapse on the GPi: the indirect pathway.
- Indirect pathway indirectly stimulates the Gpi, whereas the direct pathway directly inhibits the Gpi.
Filesystem + Formal Method + SGX
New trusted computing primitives such as Intel SGX have shown the feasibility of running user-level applications in enclaves on a commodity trusted processor without trusting a large OS. However, the OS can still compromise the integrity of an enclave by tampering with the system call return values. In fact, it has been shown that a subclass of these attacks, called Iago attacks, enables arbitrary logic execution in enclave programs. Existing enclave systems have very large TCB and they implement ad-hoc checks at the system call interface which are hard to verify for completeness. To this end, we present BesFS—the first filesystem interface which provably protects the enclave integrity against a completely malicious OS. We prove 167 lemmas and 2 key theorems in 4625 lines of Coq proof scripts, which directly proves the safety properties of the BesFS specification. BesFS comprises of 15 APIs with compositional safety and is expressive enough to support 31 real applications we test. BesFS integrates into existing SGX-enabled applications with minimal impact to TCB. BesFS can serve as a reference implementation for hand-coded API checks.

SGX to protect GPU then prevent cheating
Abstract
Online gaming, with a reported 152 billion US dollar market, is immensely popular today. One of the critical issues in multiplayer online games is cheating, in which a player uses an illegal methodology to create an advantage beyond honest game play. For example, wallhacks, the main focus of this work, animate enemy objects on a cheating player's screen, despite being actually hidden behind walls (or other occluding objects). Since such cheats discourage honest players and cause game companies to lose revenue, gaming companies deploy mitigation solutions alongside game applications on the player's machine. However, their solutions are fundamentally flawed since they are deployed on a machine where the attacker has absolute control.


Images
Cerebellum

1. Vermis. 2. Superior cerebellar peduncle (red). 3. Middle cerebellar peduncle (blue). 4. Inferior cerebellar peduncle (green). 5. Nodulus. 6. Flocculus. 7. Posterolateral fissure. 8. Cerebellar tonsils.

Medulla



Midbrain


Pons


References:
Build
Dependencies
sudo apt install build-essential libncurses-dev bison flex libssl-dev libelf-dev
sudo apt install dwarves zstdConfig
# Using current config
cp -v /boot/config-$(uname -r) .config
make menuconfigNote that CONFIG_SYSTEM_TRUSTED_KEYS= and CONFIG_SYSTEM_REVOCATION_KEYS may need to be set into "" in .config file, and CONFIG_X86_X32 may not be supported.
Build & Install
make -j32
sudo make modules_install
sudo make install
sudo update-grubUninstall
Delete what have been installed in several places:
- image:
/boot/*[kernel_ver] - modules:
/lib/modules/[kernel_ver]
SoCC'23
System
- Trust TPM & Secure Boot
- Security Monitor implemented at VMX-root level, and the model(with implementation) are formally verified.
- Enforce access control by trapping instrcuctions


Covered Attacks Surfaces
- DMA buffer
- MMIO mapping
- GPU context
Attack vectors targeting these surfaces:
- Malicious peripherals
- Concurrent CPU Access (specific to GEVisor)
Question
- How to ensure the integrity of Hypercalls? (i.e., protect the ring buffer)
- How to prove active attackers would be detected by GEVisor? (and how to define active attackers?)
- Why does the formal verification pass for GEVisor with flaws? (or what does pass mean for GEVisor?)
After Reboot
# On Host
sudo modprobe vfio-pci
sudo sh -c "echo 10de 2331 > /sys/bus/pci/drivers/vfio-pci/new_id"
# Optionally
sudo python3 ./nvidia_gpu_tools.py --gpu-name=H100 --set-cc-mode=devtools --reset-after-cc-mode-switch
# Launch VM; In VM
sudo nvidia-smi conf-compute -srs 1NDSS'21
Abstract
Intel SGX aims to provide the confidentiality of user data on untrusted cloud machines. However, applications that process confidential user data may contain bugs that leak information or be programmed maliciously to collect user data. Existing research that attempts to solve this problem does not consider multi-client isolation in a single enclave. We show that by not supporting such isolation, they incur considerable slowdown when concurrently processing multiple clients in different processes, due to the limitations of SGX.
This paper proposes CHANCEL, a sandbox designed for multi-client isolation within a single SGX enclave. In particular, CHANCEL allows a program’s threads to access both a per-thread memory region and a shared read-only memory region while servicing requests. Each thread handles requests from a single client at a time and is isolated from other threads, using a Multi-Client Software Fault Isolation (MCSFI) scheme. Furthermore, CHANCEL supports various in-enclave services such as an in-memory file system and shielded client communication to ensure complete mediation of the program’s interactions with the outside world. We implemented CHANCEL and evaluated it on SGX hardware using both micro-benchmarks and realistic target scenarios, including private information retrieval and product recommendation services. Our results show that CHANCEL outperforms a baseline multi-process sandbox between 4.06−53.70× on micro-benchmarks and 0.02 − 21.18× on realistic workloads while providing strong security guarantees.
Motivation & Target & Model
- Potentially malicious binary
- Binary/clients cannot leak confidential data
- Clients cannot compromise others' threads
- Multi-client isolation in a single enclave
Design & Method


- In-memory FS, client communication, memory management
- No additional hardware requirements (such as MPX/SGX2)
- Reserves two registers:
r14,r15 - Provide a toolchain to generate instrumented binary
Protections

- Chancel includes comprehensive evaluations on real-world tasks and benchmarks
- ASPLOS 2020
- Paper
- Soruce Code
Intel SGX is a hardware-based trusted execution environment (TEE), which enables an application to compute on confidential data in a secure enclave. SGX assumes a powerful threat model, in which only the CPU itself is trusted; anything else is untrusted, including the memory, firmware, system software, etc. An enclave interacts with its host application through an exposed, enclave-specific, (usually) bi-directional interface. This interface is the main attack surface of the enclave. The attacker can invoke the interface in any order and inputs. It is thus imperative to secure it through careful design and defensive programming.
In this work, we systematically analyze the attack models against the enclave untrusted interfaces and summarized them into the COIN attacks -- Concurrent, Order, Inputs, and Nested. Together, these four models allow the attacker to invoke the enclave interface in any order with arbitrary inputs, including from multiple threads. We then build an extensible framework to test an enclave in the presence of COIN attacks with instruction emulation and concolic execution. We evaluated ten popular open-source SGX projects using eight vulnerability detection policies that cover information leaks, control-flow hijackings, and memory vulnerabilities. We found 52 vulnerabilities. In one case, we discovered an information leak that could reliably dump the entire enclave memory by manipulating the inputs. Our evaluation highlights the necessity of extensively testing an enclave before its deployment.
Target
To find vulnerabilities of SGX applications in four models:
- Concurrent calls: multithread, race condition, improper lock...
- Order: assumes the calling sequence
- Input manipulation: bad OCALL return val & ECALL arguments
- Nested calls: calling OCALL that invokes ECALL, not implemented
Design & Method
The design of COIN:
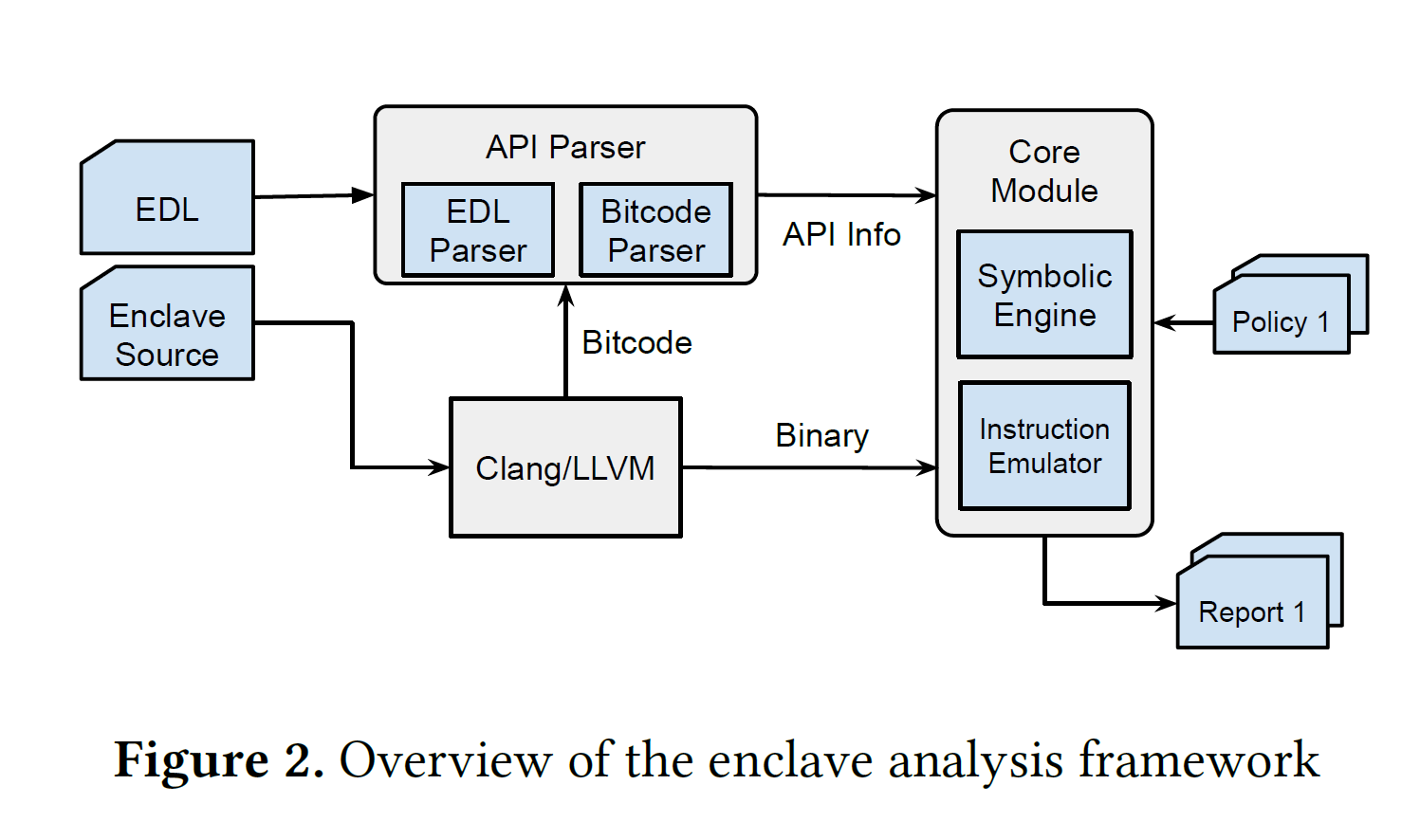
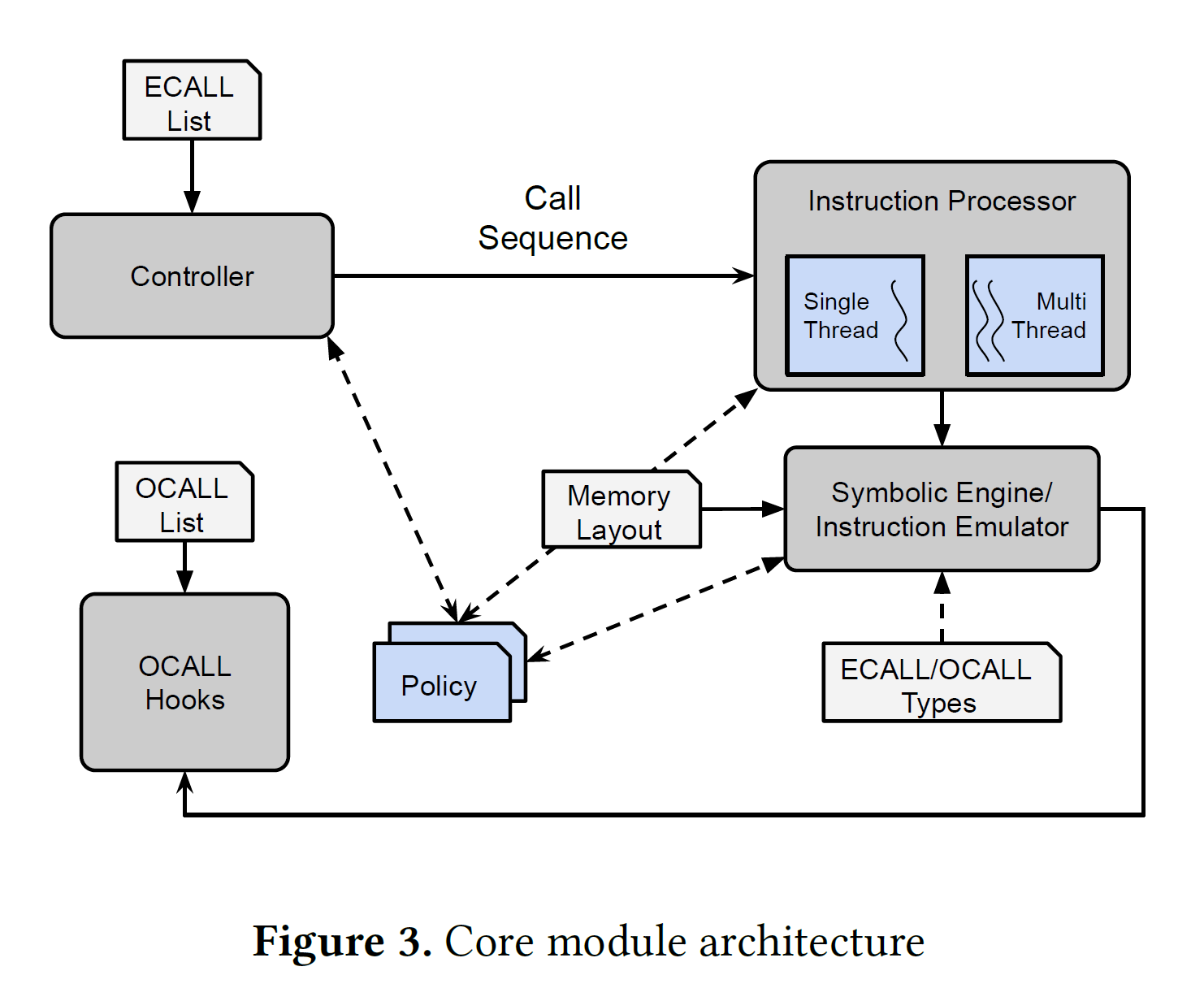
- Emulation: QEMU
- Symbolic execution: Triton (backed by z3)
- Policy-based vulnerability discovery
Results
COIN uses 8 policies to find the potential vulnerabilities:
- Heap info leak
- Stack info leak
- Ineffectual condition
- Use after free
- Double free
- Stack overflow
- Heap overflow
- Null pointer dereference
COIN Attack
- ASPLOS 2020
- Paper
- Soruce Code
Target
- Emulate TrustZone OSes(TZOS) and Trusted Applications (TAs)
- Abstract and reimplement a subset of hardware/software interfaces
- Fuzz these components
- TZOSes: QSEE, Huawei, OPTEE, Kinibi, TEEGRIS(Samsung) & TAs
Results
COIN uses 8 policies to find the potential vulnerabilities:
- Heap info leak
- Stack info leak
- Ineffectual condition
- Use after free
- Double free
- Stack overflow
- Heap overflow
- Null pointer dereference
Review
Strength
- Symbolic execution + emulation
- Policies can be configurable
- Real world problems
- Solid work
- Efforts taken to run TZOS and TA in emulation environment
- Acceptable performance
Weakness
- nested call left unimplemented
- May not be powerful enough to deal with complicate situations
- Policies are mainly at relatively low-level
- Low coverage
- Crashes -X-> vulnerabilities
PartEmu
- USENIX Security 2020
- Paper
- Source code unavailable
Traditional TrustZone OSes and Applications is not easy to fuzz because they cannot be instrumented or modified easily in the original hardware environment. So to emulate them for fuzzing purpose.
Design & Method
- Re-host the TZOS frimware
- Choose the components to reuse/emulate carefully
- Bootloader
- Secure Monitor
- TEE driver and TEE userspace
- MMIO registers (easy to emulate)
Tools
- TriforceAFL + QEMU
- Manually written Interfaces
Results
Emulations works well. For upgraded TZOSes, only a few efforts are needed for compatibility.
TAs
Challenges
- Identifying the fuzzed target
- Result stability (migrate to hardware, reproducibility)
- Randomness
| Class | Vulnerability Types | Crashes |
|---|---|---|
| Availability | Null-pointer dereferences | 9 |
| Insufficient shared memory crashes | 10 | |
| Other | 8 | |
| Confidentiality | Read from attacker-controlled pointer to shared memory | 8 |
| Read from attacker-controlled | 0 | |
| OOB buffer length to shared memory | ||
| Integrity | Write to secure memory using attacker-controlled pointer | 11 |
| Write to secure memory using | 2 | |
| attacker-controlled OOB buffer length |
Just like the previous paper, the main causes of the crashes can be attributed to:
- Assumptions of Normal-World Call Sequence
- Unvalidated Pointers from Normal World
- Unvalidated Types
TZOSes
- Normal-World Checks
- Assumptions of Normal-World Call Sequence
Abstract
We present a compiler-based scheme to protect the confidentiality of sensitive data in low-level applications (e.g. those written in C) in the presence of an active adversary. In our scheme, the programmer marks sensitive data by lightweight annotations on the top-level definitions in the source code. The compiler then uses a combination of static dataflow analysis, runtime instrumentation, and a novel taint-aware form of control-flow integrity to prevent data leaks even in the presence of low-level attacks. To reduce runtime overheads, the compiler uses a novel memory layout.
We implement our scheme within the LLVM framework and evaluate it on the standard SPEC-CPU benchmarks, and on larger, real-world applications, including the NGINX webserver and the OpenLDAP directory server. We find that the performance overheads introduced by our instrumentation are moderate (average 12% on SPEC), and the programmer effort to port the applications is minimal.
Methodology
Key insight: complete memory safety and perfect control-flow integrity (CFI) are neither sufficient nor necessary for preventing data leaks.
- Compiler performs dataflow analysis: analyzer infer expected type of taint
- Different types are placed into two separate regions
- Not requiring alias analysis
- Exclude the compiler from the TCB via a tiny verifier
Abstract
The constant-time discipline is a software-based countermeasure used for protecting high assurance cryptographic implementations against timing side-channel attacks. Constant-time is effective (it protects against many known attacks), rigorous (it can be formalized using program semantics), and amenable to automated verification. Yet, the advent of micro-architectural attacks makes constant-time as it exists today far less useful.
This paper lays foundations for constant-time programming in the presence of speculative and out-of-order execution. We present an operational semantics and a formal definition of constant-time programs in this extended setting. Our semantics eschews formalization of microarchitectural features (that are instead assumed under adversary control), and yields a notion of constant-time that retains the elegance and tractability of the usual notion. We demonstrate the relevance of our semantics in two ways: First, by contrasting existing Spectre-like attacks with our definition of constant-time. Second, by implementing a static analysis tool, Pitchfork, which detects violations of our extended constant-time property in real world cryptographic libraries.
Methodology
- A model to incorporate speculative execution.
- Abstract machine: fetch, execute, retire.
- Reorder buffer => out-of-order and speculative execution
- Directives can be initiated to model the detailed schedule of the reordered micro-ops
- Observations are also modeled in such process to mimic the leakage visible to the attacker
- Modeled instructions:
op,fence,load,store,br,call,ret
Artifact
- Symbolic execution based on angr
- Schedule the worst case reorder buffer => maximize potential leakage
- Can indeed found threat
Comments
- Are the threats confirmed by the developers?
- Is the model formalized in a proof checker?
- Execution time of instructions is not modeled? (or need not to be modeled?)
The presence of large numbers of security vulnerabilities in popular feature-rich commodity operating systems has inspired a long line of work on excluding these operating systems from the trusted computing base of applications, while retaining many of their benefits. Legacy applications continue to run on the untrusted operating system, while a small hyper visor or trusted hardware prevents the operating system from accessing the applications' memory. In this paper, we introduce controlled-channel attacks, a new type of side-channel attack that allows an untrusted operating system to extract large amounts of sensitive information from protected applications on systems like Overshadow, Ink Tag or Haven. We implement the attacks on Haven and Ink Tag and demonstrate their power by extracting complete text documents and outlines of JPEG images from widely deployed application libraries. Given these attacks, it is unclear if Over shadow's vision of protecting unmodified legacy applications from legacy operating systems running on off-the-shelf hardware is still tenable.
The key intuition is to exploit the fact that a regular applicationusually shows different patterns in control transfers or data accesses when the sensitive data it is processing are different.
- Induce Page Fault
- Recognize page access -> control/data flow
- Recover sensitive info
Mitigation


Source: Wikipedia
Images

Table from Wiki
| 编号 | 名称 | 性质 | 连脑部位 | 进出颅腔部位 | 核团 | 功能 |
|---|---|---|---|---|---|---|
| 0 | 终末神经 | ? | 終板 | 篩板 | 中隔內核(Septal nuclei) | 和費洛蒙的感測有關 |
| I | 嗅神经 | 感觉性 | 端脑 | 篩板 | 嗅前核(Anterior olfactory nucleus) | 传递嗅觉信息 |
| II | 視神經 | 感觉性 | 间脑 | 視神經管(Optic canal) | 视网膜神经节细胞[5] | 向大脑传递视觉信息 |
| III | 动眼神经 | 运动性 | 中脑前部 | 眶上裂(Superior orbital fissure) | 动眼神经核(Oculomotor nucleus) | 支配上瞼舉肌(英语:Levator palpebrae superioris),上直肌、内直肌、下直肌和下斜肌,来协同完成眼球的运动;支配瞳孔括约肌和睫状体的收缩。 |
| IV | 滑车神经 | 运动性 | 中脑后部 | 眶上裂 | 滑车神经核(Trochlear nucleus) | 支配上斜肌(Superior oblique muscle),来控制眼球的水平或者汇聚运动 |
| V | 三叉神经 | 混合性 | 橋腦 | 眶上裂(眼神经),圆孔(上颌神经),卵圆孔(下颌神经) | 三叉神经核感觉主核,三叉神经脊束核,中脑三叉神经核,三叉神经运动核 | 接受面部的感觉输入;支配咀嚼肌的收缩 |
| VI | 外旋神經 | 运动性 | 橋腦前缘 | 眶上裂 | 外展神经核 | 支配外直肌 |
| VII | 顏面神經 | 混合性 | 橋腦(橄榄核之上桥小脑角部位) | 内耳道、莖乳突孔(Stylomastoid foramen) | 面神经核、孤束核、上涎神经核 | 接收舌肌前三分之二部位的感觉输入;支配面部表情肌、二腹肌、镫骨肌;支配唾液腺和泪腺的分泌。 |
| VIII | 前庭耳蝸神經 | 感觉性 | 橋腦 | 内耳道 | 前庭神经核、耳蜗核 | 接受声音、旋转、重力(对保持平衡和运动非常重要)的感觉输入。前庭分支和耳蜗分支主要传递听觉。 |
| IX | 舌咽神经 | 混合性 | 延腦 | 頸靜脈孔(Jugular foramen) | 疑核、下涎核、孤束核 | 接受舌部后三分之一的感觉输入;部分感觉经腭扁桃体传递到脑;支配腮腺的分泌;支配茎突的运动。 |
| X | 迷走神经 | 混合性 | 延腦 | 頸靜脈孔 | 疑核、背运动迷走神经核、孤束核 | 接受来自会咽的特殊味觉输入;支配喉部肌肉和咽肌(有舌咽神经支配的茎突除外);提供了几乎所有的胸、腹部和内臟的副交感神经纤维。主要功能:控制发声肌肉、软腭和共振。损害症状:吞咽困难與腭咽闭合不全。 |
| XI | 副神经 | 运动性 | 延腦 | 頸靜脈孔 | 孤束核、脊髓副神经核 | 支配胸锁乳突肌与斜方肌,与迷走神经(CN X)功能有部分重叠。损害症状:不能耸肩,头部运动变弱。 |
| XII | 舌下神经 | 混合性 | 延腦 | 舌下神经管(Hypoglossal foramen) | 舌下神经核 | 支配舌部肌肉的运动(由迷走神经支配的舌腭肌除外);对吞咽和语音清晰度非常重要。舌部的肌肉的感覺。 |
Gyri and Sulci

As control-flow hijacking defenses gain adoption, it is important to understand the remaining capabilities of adversaries via memory exploits. Non-control data exploits are used to mount information leakage attacks or privilege escalation attacks program memory. Compared to control-flow hijacking attacks, such non-control data exploits have limited expressiveness, however, the question is: what is the real expressive power of non-control data attacks? In this paper we show that such attacks are Turing-complete. We present a systematic technique called data-oriented programming (DOP) to construct expressive non-control data exploits for arbitrary x86 programs. In the experimental evaluation using 9 programs, we identified 7518 data-oriented x86 gadgets and 5052 gadget dispatchers, which are the building blocks for DOP. 8 out of 9 real-world programs have gadgets to simulate arbitrary computations and 2 of them are confirmed to be able to build Turing-complete attacks. We build 3 end-to-end attacks to bypass randomization defenses without leaking addresses, to run a network bot which takes commands from the attacker, and to alter the memory permissions. All the attacks work in the presence of ASLR and DEP, demonstrating how the expressiveness offered by DOP significantly empowers the attacker.
There are no function call gadgets in data-oriented programming, as it does not change the control data.
- Operate on data to achieve arbitrary computation
AAAI'21, PDF
Abstract
Natural language comments convey key aspects of source code such as implementation, usage, and pre- and postconditions. Failure to update comments accordingly when the corresponding code is modified introduces inconsistencies, which is known to lead to confusion and software bugs. In this paper, we aim to detect whether a comment becomes inconsistent as a result of changes to the corresponding body of code, in order to catch potential inconsistencies just-in-time, i.e., before they are committed to a code base. To achieve this, we develop a deep-learning approach that learns to correlate a comment with code changes. By evaluating on a large corpus of comment/code pairs spanning various comment types, we show that our model outperforms multiple baselines by significant margins. For extrinsic evaluation, we show the usefulness of our approach by combining it with a comment update model to build a more comprehensive automatic comment maintenance system which can both detect and resolve inconsistent comments based on code changes.

- Learn on AST code edit (GGNN, gated graph neural networks)
- BiGRU encoding
- Use in post hoc and just-in-time from commit
We introduce a new concept called brokered delegation. Brokered delegation allows users to flexibly delegate credentials and rights for a range of service providers to other users and third parties. We explore how brokered delegation can be implemented using novel trusted execution environments (TEEs). We introduce a system called DelegaTEE that enables users (Delegatees) to log into different online services using the credentials of other users (Owners). Credentials in DelegaTEE are never revealed to Delegatees and Owners can restrict access to their accounts using a range of rich, contextually dependent delegation policies.
DelegaTEE fundamentally shifts existing access control models for centralized online services. It does so by using TEEs to permit access delegation at the user's discretion. DelegaTEE thus effectively reduces mandatory access control (MAC) in this context to discretionary access control (DAC). The system demonstrates the significant potential for TEEs to create new forms of resource sharing around online services without the direct support from those services.
We present a full implementation of DelegaTEE using Intel SGX and demonstrate its use in four real-world applications: email access (SMTP/IMAP), restricted website access using a HTTPS proxy, e-banking/credit card, and a third-party payment system (PayPal).
- Account sharing: delegate the credentials to other users securely
- Centrally and P2P


Semantic Inconsistency
- Bugs as Deviant Behavior: A General Approach to Inferring Errors in Systems Code
This is a very interesting paper, maybe the earliest work in this area. The idea is simple: some operations are based on implicit assumptions. For example, dereference implies a valid pointer.
- Detecting Missing-Check Bugs via Semantic- and Context-Aware Criticalness and Constraints Inferences PDF
Solely focus on missing checks in Linux kernel.
- APISAN: Sanitizing API Usages through Semantic Cross-checking PDF
To find API usage errors, APISAN automatically infers semantic correctness, called semantic beliefs, by analyzing the source code of different uses of the API.
the more API patterns developers use in similar contexts, the more confidence we have about the correct API usage.
This is a probabilistic approach. Symbolic execution can help to construct a "semantic belief" of the outcome (and pre- and post- conditions) of executing an API, and such construction will be more and more precise as there are more samples in the dataset.
This work is based mainly on relaxed symbolic execution.
- Scalable and systematic detection of buggy inconsistencies in source code Paper
Analysis of bugs on cloned code. Searching: hash of code snippet, AST level.
- Gap between theory and practice: an empirical study of security patches in solidity
- Which bugs are missed in code reviews: An empirical study on SmartSHARK dataset
Semantic bugs are mostly missed (51.34%) from the review process, 7 out of 96 are typos.
- VarCLR: Variable Semantic Representation Pre-training via Contrastive Learning
- Bug characteristics in open source software
Careless programming causes many bugs in the evaluated software. For example, simple bugs such as typos account for 7.8–15.0 % of semantic bugs in Mozilla, Apache, and the Linux kernel
- Automating Code Review Activities by Large-Scale Pre-training



ICSE'19
Side-channel attacks allow an adversary to uncover secret program data by observing the behavior of a program with respect to a resource, such as execution time, consumed memory or response size. Side-channel vulnerabilities are difficult to reason about as they involve analyzing the correlations between resource usage over multiple program paths. We present DifFuzz, a fuzzing-based approach for detecting side-channel vulnerabilities related to time and space. DifFuzz automatically detects these vulnerabilities by analyzing two versions of the program and using resource-guided heuristics to find inputs that maximize the difference in resource consumption between secret-dependent paths. The methodology of DifFuzz is general and can be applied to programs written in any language. For this paper, we present an implementation that targets analysis of Java programs, and uses and extends the Kelinci and AFL fuzzers. We evaluate DifFuzz on a large number of Java programs and demonstrate that it can reveal unknown side-channel vulnerabilities in popular applications. We also show that DifFuzz compares favorably against Blazer and Themis, two state-of-the-art analysis tools for finding side-channels in Java programs.
- How can a untrusted hypervisor load the disk/image of a CVM in a trustworthy way?
- How to pass the keys from the trusted user to the VM in a secure way?
This document (Confidential Computing secrets) specifies that:
Confidential Computing (coco) hardware such as AMD SEV (Secure Encrypted Virtualization) allows guest owners to inject secrets into the VMs memory without the host/hypervisor being able to read them. In SEV, secret injection is performed early in the VM launch process, before the guest starts running.
However, it's still not clear to me how the secrets are passed to the VM securely. I guess this can be a bit different for SEV and TDX.
Fortunately, Linux provides a good documentation explaining the details here for SEV.
Notably, there is a command called KVM_SEV_LAUNCH_SECRET, documented like this:
KVM_SEV_LAUNCH_SECRETThe KVM_SEV_LAUNCH_SECRET command can be used by the hypervisor to inject secret data after the measurement has been validated by the guest owner.Parameters (in): struct kvm_sev_launch_secretReturns: 0 on success, -negative on error
The structure looks like this:
struct kvm_sev_launch_secret {
__u64 hdr_uaddr; /* userspace address containing the packet header */
__u32 hdr_len;
__u64 guest_uaddr; /* the guest memory region where the secret should be injected */
__u32 guest_len;
__u64 trans_uaddr; /* the hypervisor memory region which contains the secret */
__u32 trans_len;
};It seems like there is a mechanism for the CVM to take secrets from the host memory region.
- Interactive shell
docker run -it <image name> [shell] - Show current containers
docker container ls - Commit changes
docker commit <container id> [name] - Attach a running container
docker attach <container id>
- Run with SGX
docker run -it -v /var/run/aesmd:/var/run/aesmd --device=/dev/isgx [image name]
Other Commands
- show network configs of containers
docker network inspect bridge
Abstract
Dune is a system that provides applications with direct but safe access to hardware features such as ring protection, page tables, and tagged TLBs, while preserving the existing OS interfaces for processes. Dune uses the virtualization hardware in modern processors to provide a process, rather than a machine abstraction. It consists of a small kernel module that initializes virtualization hardware and mediates interactions with the kernel, and a user-level library that helps applications manage privileged hardware features. We present the implementation of Dune for 64bit x86 Linux. We use Dune to implement three userlevel applications that can benefit from access to privileged hardware: a sandbox for untrusted code, a privilege separation facility, and a garbage collector. The use of Dune greatly simplifies the implementation of these applications and provides significant performance advantages.
Methodology
Turn user-level processes into a lightweight VM-abstraction. This achieves isolation while enhances performance dramatically on syscalls, interrupts and page table operations.
Such abstraction is done by Dune kernel module on the host (VMX root, ring 0), and a libDune in Dune-mode process (VMX non-root, ring 0),
Main complexity comes from exposing EPT, handling syscalls/interrupts, and state registers.
Overheads (compared to native Linux)
- getpid (syscall-vmcall) - page fault - page walk (TLB miss)
Why these two have overhead?
Enhancements
- ptrace (intercept VMCALL) - trap (in VM) - appel1 & appel2 (memory management performance measurement)
Old version: Binary Compatibility For SGX Enclaves
Yet another middleware to support unmodified binary to run in SGX enclave. This is done through dynamically rewrite binary inside the encalve.
Enclaves, such as those enabled by Intel SGX, offer a hardware primitive for shielding user-level applications from the OS. While enclaves are a useful starting point, code running in the enclave requires additional checks whenever control or data is transferred to/from the untrusted OS. The enclave-OS interface on SGX, however, can be extremely large if we wish to run existing unmodified binaries inside enclaves. This paper presents Ratel, a dynamic binary translation engine running inside SGX enclaves on Linux. Ratel offers complete interposition, the ability to interpose on all executed instructions in the enclave and monitor all interactions with the OS. Instruction-level interposition offers a general foundation for implementing a large variety of inline security monitors in the future.
We take a principled approach in explaining why complete interposition on SGX is challenging. We draw attention to 5 design decisions in SGX that create fundamental trade-offs between performance and ensuring complete interposition, and we explain how to resolve them in the favor of complete interposition. To illustrate the utility of the Ratel framework, we present the first attempt to offer binary compatibility with existing software on SGX. We report that Ratel offers binary compatibility with over 200 programs we tested, including micro-benchmarks and real applications such as Linux shell utilities. Runtimes for two programming languages, namely Python and R, tested with standard benchmarks work out-of-the-box on Ratel without any specialized handling.
Abstract
There has been interest in mechanisms that enable the secure use of legacy code to implement trusted code in a Trusted Execution Environment (TEE), such as Intel SGX. However, because legacy code generally assumes the presence of an operating system, this naturally raises the spectre of Iago attacks on the legacy code. We observe that not all legacy code is vulnerable to Iago attacks and that legacy code must use return values from system calls in an unsafe way to have Iago vulnerabilities.
Based on this observation, we develop Emilia, which automatically detects Iago vulnerabilities in legacy applications by fuzzing applications using system call return values. We use Emilia to discover 51 Iago vulnerabilities in 17 applications, and find that Iago vulnerabilities are widespread and common. We conduct an in-depth analysis of the vulnerabilities we found and conclude that while common, the majority (82.4%) can be mitigated with simple, stateless checks in the system call forwarding layer, while the rest are best fixed by finding and patching them in the legacy code. Finally, we study and evaluate different trade-offs in the design of Emilia.
- Target: SGX Applications running inside a middleware
- Method: Fuzzing
- Tool:
strace(to intercept syscall return value)
Fuzzing Strategies
- Target selection (syscalls)
- Extract branch conditions depending on the return value from syscalls
- Random/valid/invalid return values
- Different return fields
Evaluation
to be continued
Abstract
Formal verification can provide the highest degree of software assurance. Demand for it is growing, but there are still few projects that have successfully applied it to sizeable, real-world systems. This lack of experience makes it hard to predict the size, effort and duration of verification projects. In this paper, we aim to better understand possible leading indicators of proof size. We present an empirical analysis of proofs from the landmark formal verification of the seL4 microkernel and the two largest software verification proof developments in the Archive of Formal Proofs. Together, these comprise 15,018 individual lemmas and approximately 215,000 lines of proof script. We find a consistent quadratic relationship between the size of the formal statement of a property, and the final size of its formal proof in the interactive theorem prover Isabelle. Combined with our prior work, which has indicated that there is a strong linear relationship between proof effort and proof size, these results pave the way for effort estimation models to support the management of large-scale formal verification projects.
Abstract
Security inspection and testing require experts in security who think like an attacker. Security experts need to know code locations on which to focus their testing and inspection efforts. Since vulnerabilities are rare occurrences, locating vulnerable code locations can be a challenging task. We investigated whether software metrics obtained from source code and development history are discriminative and predictive of vulnerable code locations. If so, security experts can use this prediction to prioritize security inspection and testing efforts. The metrics we investigated fall into three categories: complexity, code churn, and developer activity metrics. We performed two empirical case studies on large, widely used open-source projects: the Mozilla Firefox web browser and the Red Hat Enterprise Linux kernel. The results indicate that 24 of the 28 metrics collected are discriminative of vulnerabilities for both projects. The models using all three types of metrics together predicted over 80 percent of the known vulnerable files with less than 25 percent false positives for both projects. Compared to a random selection of files for inspection and testing, these models would have reduced the number of files and the number of lines of code to inspect or test by over 71 and 28 percent, respectively, for both projects.
Discussion
This is an interesting work, analyzing factors which can be used as the indicator to predict which file(s) in a project may contain vulnerabilities. But there are still several questions:
- Can these conclusions/observations be applied to other projects/languages?
- Is there a universal threshold to predict if a source file contain a bug? Or these criteria are just project-wise.
- If single factors already do well for prediction, why do we (in practice) consider multiple factors?
Abstract
Fuzz testing has enjoyed great success at discovering security critical bugs in real software. Recently, researchers have devoted significant effort to devising new fuzzing techniques, strategies, and algorithms. Such new ideas are primarily evaluated experimentally so an important question is: What experimental setup is needed to produce trustworthy results? We surveyed the recent research literature and assessed the experimental evaluations carried out by 32 fuzzing papers. We found problems in every evaluation we considered. We then performed our own extensive experimental evaluation using an existing fuzzer. Our results showed that the general problems we found in existing experimental evaluations can indeed translate to actual wrong or misleading assessments. We conclude with some guidelines that we hope will help improve experimental evaluations of fuzz testing algorithms, making reported results more robust.
This is a very interesting paper. It points out some "unscientific" aspects in fuzzing, including:
- Not unified test suite and various fuzzing targets (also different versions)
- Important factors like execution time and seed selection
They suggest using more statistical methodology (e.g., statistical tests) to support one fuzzer beats another.
- Interestingly, there is a new SoK paper in 2024 discussing this similar topic: SoK: Prudent Evaluation Practices for Fuzzing.
Pros
- Extremely extensive evaluation
- Has (a little) explanation
- Evaluate off-the-shelf and self-trained LLMs
- Parameter Sweeping
Gadgets
We note that restricting our evaluation to short, localized patches does not necessarily harm the validity of our analysis, as prior work has found that security patches tend to be more localized, have fewer source code modifications, and tend to affect fewer functions, compared to non-security bugs >>>
USENIX'19 Paper
System


Attacks
- Monitoring nPT (nested page table) and gPT (guest page table)
- Page faults => a list of accessed pages => find the actual address of the target page
- Decryption oracle: move content of the ciphertext to the SWIOTLB
- Let it be decrypted
Technical Details
- Monitoring/MITM the DMA operations
- Pattern matching to find the accessed address in private memory
IOremapto replace ciphertext- QEMU notifies the VM about DMA write. Does it notify the device to read DMA?
Abstract
We present PIDGIN, a program analysis and understanding tool that enables the specification and enforcement of precise application-specific information security guarantees. PIDGIN also allows developers to interactively explore the information flows in their applications to develop policies and investigate counter-examples. PIDGIN combines program dependence graphs (PDGs), which precisely capture the information flows in a whole application, with a custom PDG query language. Queries express properties about the paths in the PDG; because paths in the PDG correspond to information flows in the application, queries can be used to specify global security policies. PIDGIN is scalable. Generating a PDG for a 330k line Java application takes 90 seconds, and checking a policy on that PDG takes under 14 seconds. The query language is expressive, supporting a large class of precise, application-specific security guarantees. Policies are separate from the code and do not interfere with testing or development, and can be used for security regression testing. We describe the design and implementation of PIDGIN and report on using it: (1) to explore information security guarantees in legacy programs; (2) to develop and modify security policies concurrently with application development; and (3) to develop policies based on known vulnerabilities.
How PDG looks like

Methodology
- Generate PDG for a Program
- Query the graph with PidginQL (according to the property to check)
- Check the returned subgraph (if it's empty in most cases)
Comments
This seems to be a lightweight method for validating the property of code. One thing worth notice is that the generation of PDG takes relatively long while, whereas querying it takes much less time (~5X). The properties to validate is dependent on the program, which means for different programs, the query could be different.
However, this method lacks formal foundation. The soundness and completeness are not covered in this paper, and I'm not sure about the reliability of such PDG-based methods.
Abstract
Industries and governments are increasingly compelled by regulations and public pressure to handle sensitive information responsibly. Regulatory requirements and user expectations may be complex and have subtle implications for the use of data. Information flow properties can express complex restrictions on data usage by specifying how sensitive data (and data derived from sensitive data) may flow throughout computation. Controlling these flows of information according to the appropriate specification can prevent both leakage of confidential information to adversaries and corruption of critical data by adversaries. There is a rich literature expressing information flow properties to describe the complex restrictions on data usage required by today’s digital society. This monograph summarizes how the expressiveness of information flow properties has evolved over the last four decades to handle different threat models, computational models, and conditions that determine whether flows are allowed. In addition to highlighting the significant advances of this area, we identify some remaining problems worthy of further investigation.
Considerations
Theoretical Foundations
- Lattice theory
- Noninterference
- Logic models (e.g., temporal logic)
Threat Models
- Termination: does termination leaks high*?
- Time: different time
- Interaction: input/output flow
- Program code
Computational Models
- Nondeterminism: the program is not deterministic
- Composition of systems: e.g., feedback: the output becomes next input. Composition can lead to nondeterminism
- Concurrency
Re(de)classification
- Need to consider: what, where, when, and who
- Introduce Delimited Release to declassify
S-FaaS: Trustworthy and Accountable Function-as-a-Service using Intel SGX
- Resource accounting on SGX “enclaved” FaaS.
- Trusted timer: built using TSX + additional timer thread
- Model: function trusted by user, but not service provider(platform) => sandbox
- KMS, transitive attestation, encryption
- Implementation on Apache OpenWhisk
Towards Demystifying Serverless Machine Learning Training
- Implement a serverless distributed ML framework, LambdaML, including distributed optimization, communication (with a storage server) and synchronization
- Compare the FaaS and IaaS solution for distributed ML.
Trust more, serverless
- JS FaaS in SGX enclaves
- Google V8 engine/Duntape + SGX LKL + Apache OpenWhisk
- Key management
- Parallel, warm start, adjust to load
Clemmys: Towards Secure Remote Execution in FaaS
- SGX2: DMM to speedup enclave init
- OpenWhisk + Scone + Palaemon(KMS)
- Gateway(T) + Controller(U) + Worker(T): not all in the enclave
- Features: function chaining & verification
- Functions should be manually inspected
Other related papers
Confidential Serverless Made Efficient with Plug-In Enclaves
Facts
Compiler optimization passes can introduce new vulnerabilities into correctly written code. For example, an optimization pass may introduce branching instructions in originally branchless C code [46].
Idea
Constant-time in(similar to) C is not very easy:
- Compiler may optimize the CT instructions away with branches
- CT code is not easy to write in C (and hard to read)
- The generated CT code is not very efficient (e.g., not use CT-related instructions like
cmov,adc)
FaCT also has a IFC label on data to determine is security level.

Applying cluster on code to find inconsistency.
Key insight: Our approach is inspired by the observation that many bugs in software manifest as inconsistencies deviating from their non-buggy counterparts, namely the code snippets that implement the similar logic in the same codebase. Such bugs, regardless of their types, can be detected by identifying functionally-similar yet inconsistent code snippets in the same codebase
Pros
- Two-level clustering
- Embedding on program dependency graph
- Found bugs (at function level) in large projects
- Embedding on code structures
- Generality
Cons
- Need repo-specific training
- Literals are removed at the IR level
To abstract Constructs, we preserve only the variable types for each program statement and remove all variable names and versions.
- Needs repository-specific configuration of thresholds
- Still very high FP
Others
- Granularity at the function level
If an inconsistent cluster contains more than a fixed number (e.g., 2) of deviating nodes (i.e., nodes in Table 2), the inconsistency is deprioritized because it is unlikely to be a true inconsistency (i.e., a single inconsistency rarely involves many deviations).
# Rebase
## Change last commit
git commit --amend --date "$(date)"
# MISC
## Add tag
git tag -a <tag> <commit>
git push --tags
## Delete file in commit (but not in FS)
git rm <file_name> --cached


Partial GPU
Passing a partial GPU to a VM using vGPU and SRIOV.
This shared case can be dangerous.
Isolation inside the CVM
How exactly does the GPU access the CVM's memory? Part of the memory is marked as shared, while encrypted.
The protected file system is first initialized by function pal_linux_main (in db_main.c).
PF initialization
The init function is init_protected_files in enclave_pf.c.
int init_protected_files(void) {
int ret;
pf_debug_f debug_callback = NULL;
#ifdef DEBUG
debug_callback = cb_debug;
#endif
pf_set_callbacks(cb_read, cb_write, cb_truncate, cb_aes_gcm_encrypt, cb_aes_gcm_decrypt,
cb_random, debug_callback);
/* if wrap key is not hard-coded in the manifest, assume that it was received from parent or
* it will be provisioned after local/remote attestation; otherwise read it from manifest */
char* protected_files_key_str = NULL;
ret = toml_string_in(g_pal_state.manifest_root, "sgx.protected_files_key",
&protected_files_key_str);
if (ret < 0) {
log_error("Cannot parse \'sgx.protected_files_key\' "
"(the value must be put in double quotes!)\n");
return -PAL_ERROR_INVAL;
}
if (protected_files_key_str) {
if (strlen(protected_files_key_str) != PF_KEY_SIZE * 2) {
log_error("Malformed \'sgx.protected_files_key\' value in the manifest\n");
free(protected_files_key_str);
return -PAL_ERROR_INVAL;
}
memset(g_pf_wrap_key, 0, sizeof(g_pf_wrap_key));
for (size_t i = 0; i < strlen(protected_files_key_str); i++) {
int8_t val = hex2dec(protected_files_key_str[i]);
if (val < 0) {
log_error("Malformed \'sgx.protected_files_key\' value in the manifest\n");
free(protected_files_key_str);
return -PAL_ERROR_INVAL;
}
g_pf_wrap_key[i / 2] = g_pf_wrap_key[i / 2] * 16 + (uint8_t)val;
}
free(protected_files_key_str);
g_pf_wrap_key_set = true;
}
if (register_protected_files() < 0) {
log_error("Malformed protected files found in manifest\n");
}
return 0;
}Modify this function if RA/LA to pass the key to PFs
- Set callback functions which will be invoked for encryption and decryption (when are they called?)
- Read PF key from manifest
- Register protected files
Open in Graphene SGX
It will check if the file to open is a PF first. See code in db_files.c:
static int file_open(PAL_HANDLE* handle, const char* type, const char* uri, int access, int share,
int create, int options) {
// MISSING CODE ...
pf = load_protected_file(path, (int*)&hdl->file.fd, st.st_size, pf_mode, pf_create, pf);
if (pf) {
pf->refcount++;
if (pf_mode & PF_FILE_MODE_WRITE) {
pf->writable_fd = fd;
}
} else {
// MISSING CODE ...See also Graphene-SGX PF Implementation for more details.
/* Host callbacks */
static pf_read_f g_cb_read = NULL;
static pf_write_f g_cb_write = NULL;
static pf_truncate_f g_cb_truncate = NULL;
static pf_debug_f g_cb_debug = NULL;
static pf_aes_gcm_encrypt_f g_cb_aes_gcm_encrypt = NULL;
static pf_aes_gcm_decrypt_f g_cb_aes_gcm_decrypt = NULL;
static pf_random_f g_cb_random = NULL;read
g_cb_read is used in ipf_read_node:
static bool ipf_read_node(pf_context_t* pf, pf_handle_t handle, uint64_t node_number, void* buffer,
uint32_t node_size) {
uint64_t offset = node_number * node_size;
pf_status_t status = g_cb_read(handle, buffer, offset, node_size);
if (PF_FAILURE(status)) {
pf->last_error = status;
return false;
}
return true;
}This callback function is used in PF:
/* Callbacks for protected files handling */
static pf_status_t cb_read(pf_handle_t handle, void* buffer, uint64_t offset, size_t size) {
int fd = *(int*)handle;
size_t buffer_offset = 0;
size_t to_read = size;
while (to_read > 0) {
ssize_t read = ocall_pread(fd, buffer + buffer_offset, to_read, offset + buffer_offset);
if (read == -EINTR)
continue;
if (read < 0) {
log_error("cb_read(%d, %p, %lu, %lu): read failed: %ld\n", fd, buffer, offset,
size, read);
return PF_STATUS_CALLBACK_FAILED;
}
/* EOF is an error condition, we want to read exactly `size` bytes */
if (read == 0) {
log_error("cb_read(%d, %p, %lu, %lu): EOF\n", fd, buffer, offset, size);
return PF_STATUS_CALLBACK_FAILED;
}
to_read -= read;
buffer_offset += read;
}
return PF_STATUS_SUCCESS;
}write
g_cb_write is used in ipf_write_file.
static bool ipf_write_file(pf_context_t* pf, pf_handle_t handle, uint64_t offset, void* buffer,
uint32_t size) {
pf_status_t status = g_cb_write(handle, buffer, offset, size);
if (PF_FAILURE(status)) {
pf->last_error = status;
return false;
}
return true;
}This callback function is used in PF:
static pf_status_t cb_write(pf_handle_t handle, const void* buffer, uint64_t offset, size_t size) {
int fd = *(int*)handle;
size_t buffer_offset = 0;
size_t to_write = size;
while (to_write > 0) {
ssize_t written = ocall_pwrite(fd, buffer + buffer_offset, to_write,
offset + buffer_offset);
if (written == -EINTR)
continue;
if (written < 0) {
log_error("cb_write(%d, %p, %lu, %lu): write failed: %ld\n", fd, buffer, offset,
size, written);
return PF_STATUS_CALLBACK_FAILED;
}
/* EOF is an error condition, we want to write exactly `size` bytes */
if (written == 0) {
log_error("cb_write(%d, %p, %lu, %lu): EOF\n", fd, buffer, offset, size);
return PF_STATUS_CALLBACK_FAILED;
}
to_write -= written;
buffer_offset += written;
}
return PF_STATUS_SUCCESS;
}truncate
Not used in the implementation, it's less interesting.
encrypt
g_cb_aes_gcm_encrypt is used in several places, including ipf_import_metadata_key, ipf_update_all_data_and_mht_nodes, ipf_update_all_data_and_mht_nodes, ipf_update_metadata_node, all in file protected_files.c. This function is mainly called when data needs updates or init.
The callback is merely calling AES GCM function to encrypt.
static pf_status_t cb_aes_gcm_encrypt(const pf_key_t* key, const pf_iv_t* iv, const void* aad,
size_t aad_size, const void* input, size_t input_size,
void* output, pf_mac_t* mac) {
int ret = lib_AESGCMEncrypt((const uint8_t*)key, sizeof(*key), (const uint8_t*)iv, input,
input_size, aad, aad_size, output, (uint8_t*)mac, sizeof(*mac));
if (ret != 0) {
log_error("lib_AESGCMEncrypt failed: %d\n", ret);
return PF_STATUS_CALLBACK_FAILED;
}
return PF_STATUS_SUCCESS;
}decrypt
g_cb_aes_gcm_decrypt is used in ipf_init_existing_file, ipf_read_data_node, ipf_read_mht_node.
Likewise, its callback is:
static pf_status_t cb_aes_gcm_decrypt(const pf_key_t* key, const pf_iv_t* iv, const void* aad,
size_t aad_size, const void* input, size_t input_size,
void* output, const pf_mac_t* mac) {
int ret = lib_AESGCMDecrypt((const uint8_t*)key, sizeof(*key), (const uint8_t*)iv, input,
input_size, aad, aad_size, output, (const uint8_t*)mac,
sizeof(*mac));
if (ret != 0) {
log_error("lib_AESGCMDecrypt failed: %d\n", ret);
return PF_STATUS_CALLBACK_FAILED;
}
return PF_STATUS_SUCCESS;
}random
g_cb_random is used in ipf_import_metadata_key, ipf_generate_random_key.
The callback calls _DkRandomBitsRead, which reads in random bits from a random device.
static pf_status_t cb_random(uint8_t* buffer, size_t size) {
int ret = _DkRandomBitsRead(buffer, size);
if (ret < 0) {
log_error("_DkRandomBitsRead failed: %d\n", ret);
return PF_STATUS_CALLBACK_FAILED;
}
return PF_STATUS_SUCCESS;
}pf_contex
struct pf_context {
metadata_node_t file_metadata; // actual data from disk's meta data node
pf_status_t last_error;
metadata_encrypted_t encrypted_part_plain; // encrypted part of metadata node, decrypted
file_node_t root_mht; // the root of the mht is always needed (for files bigger than 3KB)
pf_handle_t file;
pf_file_mode_t mode;
uint64_t offset; // current file position (user's view)
bool end_of_file;
uint64_t real_file_size;
bool need_writing;
pf_status_t file_status;
pf_key_t user_kdk_key;
pf_key_t cur_key;
lruc_context_t* cache;
#ifdef DEBUG
char* debug_buffer; // buffer for debug output
#endif
};See also: SGX_PF_Class
How nodes organized
In the PF implementation, there is a function called get_node_numbers, and the comments implies the node structure of a PF:
What's child MHT node? why 32?- Three types of nodes: metadata, data, and mht
- metadata: TODO
- data: just to store encrypted data
- mht: each mht node can contain
keyandgmacof 96 data nodes and 32 child mht nodes. Every pf has at least one root mht node, and a mht (child) node is added to this pf after every 96 consecutive data nodes.
// this is a very 'specific' function, tied to the architecture of the file layout,
// returning the node numbers according to the data offset in the file
static void get_node_numbers(uint64_t offset, uint64_t* mht_node_number, uint64_t* data_node_number,
uint64_t* physical_mht_node_number,
uint64_t* physical_data_node_number) {
// physical nodes (file layout):
// node 0 - meta data node
// node 1 - mht
// nodes 2-97 - data (ATTACHED_DATA_NODES_COUNT == 96)
// node 98 - mht
// node 99-195 - data
// etc.
uint64_t _physical_mht_node_number;
uint64_t _physical_data_node_number;
// "logical" nodes: sequential index of the corresponding mht/data node in all mht/data nodes
uint64_t _mht_node_number;
uint64_t _data_node_number;
assert(offset >= MD_USER_DATA_SIZE);
_data_node_number = (offset - MD_USER_DATA_SIZE) / PF_NODE_SIZE;
_mht_node_number = _data_node_number / ATTACHED_DATA_NODES_COUNT;
_physical_data_node_number = _data_node_number
+ 1 // meta data node
+ 1 // mht root
+ _mht_node_number; // number of mht nodes in the middle
// (the root mht mht_node_number is 0)
_physical_mht_node_number = _physical_data_node_number
- _data_node_number % ATTACHED_DATA_NODES_COUNT // now we are at
// the first data node attached to this mht node
- 1; // and now at the mht node itself!
if (mht_node_number != NULL)
*mht_node_number = _mht_node_number;
if (data_node_number != NULL)
*data_node_number = _data_node_number;
if (physical_mht_node_number != NULL)
*physical_mht_node_number = _physical_mht_node_number;
if (physical_data_node_number != NULL)
*physical_data_node_number = _physical_data_node_number;
}file_node_t
- This macro also defines a linked list of
file_node_t - Two types of decrypted data in this node
DEFINE_LIST(_file_node);
typedef struct _file_node {
LIST_TYPE(_file_node) list;
uint8_t type;
uint64_t node_number;
struct _file_node* parent;
bool need_writing;
bool new_node;
struct {
uint64_t physical_node_number;
encrypted_node_t encrypted; // the actual data from the disk
};
union { // decrypted data
mht_node_t mht;
data_node_t data;
} decrypted;
} file_node_t;
DEFINE_LISTP(_file_node);
typedef struct _mht_node {
gcm_crypto_data_t data_nodes_crypto[ATTACHED_DATA_NODES_COUNT];
gcm_crypto_data_t mht_nodes_crypto[CHILD_MHT_NODES_COUNT];
} mht_node_t;
typedef struct _data_node {
uint8_t data[PF_NODE_SIZE];
} data_node_t;
typedef struct _encrypted_node {
uint8_t cipher[PF_NODE_SIZE];
} encrypted_node_t;See also: SDK_PF_DataNode
metadata_node_t
It seems like in graphene pf, the metadata node will be padded rather than filled in with user data.- Similar to SDK:
#define PF_NODE_SIZE 4096Uand#define MD_USER_DATA_SIZE (PF_NODE_SIZE * 3 / 4)
typedef struct _metadata_node {
metadata_plain_t plain_part;
metadata_encrypted_blob_t encrypted_part;
metadata_padding_t padding;
} metadata_node_t;
typedef struct _metadata_plain {
uint64_t file_id;
uint8_t major_version;
uint8_t minor_version;
pf_keyid_t metadata_key_id;
pf_mac_t metadata_gmac; /* GCM mac */
} metadata_plain_t;
typedef struct _metadata_encrypted {
char path[PATH_MAX_SIZE];
uint64_t size;
pf_key_t mht_key;
pf_mac_t mht_gmac;
uint8_t data[MD_USER_DATA_SIZE];
} metadata_encrypted_t;
typedef uint8_t metadata_encrypted_blob_t[sizeof(metadata_encrypted_t)];
typedef uint8_t metadata_padding_t[METADATA_NODE_SIZE -
(sizeof(metadata_plain_t) + sizeof(metadata_encrypted_blob_t))];See also: SDK_PF_metadata
High-level Overview
- Protected file operations trapped into the libOS
- LibOS calls the corresponding user-level functions (
pf_*) - The user-level functions invokes it's internal Intel PF functions (
ipf_*) - Callback the actual functions which does the operation (
cb_*)
- PF is stateful and it's maintained by
pf_context - Integrity guaranteed by MHT
Gadgets
- The implementation of PF can be found here.
- Just like the Intel PF, there are a set of user interfaces and another set of functions as internal implementation.
ipfstands for Intel Protected File. They are internal implementation of PF, just like which in the SGX SDK.
User Interfaces
Graphene-SGX PF User Interfaces
Callbacks
First of all, several callback function pointers are set beforehand and will be used later in read & write, encryption and decryption.
All the call back function pointers are set to callbacks from enclave_pf.c.
Internal data structures
They are very similar to which in SGX SDK.
Internal implementation
Functions starting with name ipf_.
These functions performs essential operations on protected files. The implementations seem like transporting the official Intel SGX SDK cpp code to c at graphene side.
- LRU cache is used for data/mht nodes iteration
ipf_open
- Create and initialize(
ipf_init_fields) apf(pf_context_t) - Check validity of key, path, handle(fd), size
- Check if it needs to create a new file or the file exits
- Return
pf
static pf_context_t* ipf_open(const char* path, pf_file_mode_t mode, bool create, pf_handle_t file,
uint64_t real_size, const pf_key_t* kdk_key, pf_status_t* status) {
*status = PF_STATUS_NO_MEMORY;
pf_context_t* pf = calloc(1, sizeof(*pf));
if (!pf)
goto out;
if (!ipf_init_fields(pf))
goto out;
DEBUG_PF("handle: %d, path: '%s', real size: %lu, mode: 0x%x\n", *(int*)file, path, real_size,
mode);
if (kdk_key == NULL) {
DEBUG_PF("no key specified\n");
pf->last_error = PF_STATUS_INVALID_PARAMETER;
goto out;
}
if (path && strlen(path) > PATH_MAX_SIZE - 1) {
pf->last_error = PF_STATUS_PATH_TOO_LONG;
goto out;
}
// for new file, this value will later be saved in the meta data plain part (init_new_file)
// for existing file, we will later compare this value with the value from the file
// (init_existing_file)
COPY_ARRAY(pf->user_kdk_key, *kdk_key);
// omeg: we require a canonical full path to file, so no stripping path to filename only
// omeg: Intel's implementation opens the file, we get the fd and size from the Graphene handler
if (!file) {
DEBUG_PF("invalid handle\n");
pf->last_error = PF_STATUS_INVALID_PARAMETER;
goto out;
}
if (real_size % PF_NODE_SIZE != 0) {
pf->last_error = PF_STATUS_INVALID_HEADER;
goto out;
}
pf->file = file;
pf->real_file_size = real_size;
pf->mode = mode;
if (!create) {
// existing file
if (!ipf_init_existing_file(pf, path))
goto out;
} else {
// new file
if (!ipf_init_new_file(pf, path))
goto out;
}
pf->last_error = pf->file_status = PF_STATUS_SUCCESS;
DEBUG_PF("OK (data size %lu)\n", pf->encrypted_part_plain.size);
out:
if (pf && PF_FAILURE(pf->last_error)) {
DEBUG_PF("failed: %d\n", pf->last_error);
free(pf);
pf = NULL;
}
if (pf)
*status = pf->last_error;
return pf;
}ipf_read
- Check if error occurs beforehand
- Get data out from metadata block (1st blk) if needed
- Continuously retrieve a node to read and read this node (
ipf_get_data_node)
static size_t ipf_read(pf_context_t* pf, void* ptr, size_t size) {
if (ptr == NULL) {
pf->last_error = PF_STATUS_INVALID_PARAMETER;
return 0;
}
if (PF_FAILURE(pf->file_status)) {
pf->last_error = pf->file_status;
return 0;
}
if (!(pf->mode & PF_FILE_MODE_READ)) {
pf->last_error = PF_STATUS_INVALID_MODE;
return 0;
}
size_t data_left_to_read = size;
if (((uint64_t)data_left_to_read) > (uint64_t)(pf->encrypted_part_plain.size - pf->offset)) {
// the request is bigger than what's left in the file
data_left_to_read = (size_t)(pf->encrypted_part_plain.size - pf->offset);
}
// used at the end to return how much we actually read
size_t data_attempted_to_read = data_left_to_read;
unsigned char* out_buffer = (unsigned char*)ptr;
// the first block of user data is read from the meta-data encrypted part
if (pf->offset < MD_USER_DATA_SIZE) {
// offset is smaller than MD_USER_DATA_SIZE
size_t data_left_in_md = MD_USER_DATA_SIZE - (size_t)pf->offset;
size_t size_to_read = MIN(data_left_to_read, data_left_in_md);
memcpy(out_buffer, &pf->encrypted_part_plain.data[pf->offset], size_to_read);
pf->offset += size_to_read;
out_buffer += size_to_read;
data_left_to_read -= size_to_read;
}
while (data_left_to_read > 0) {
file_node_t* file_data_node = NULL;
// return the data node of the current offset, will read it from disk if needed
// (and also the mht node if needed)
file_data_node = ipf_get_data_node(pf);
if (file_data_node == NULL)
break;
size_t offset_in_node = (pf->offset - MD_USER_DATA_SIZE) % PF_NODE_SIZE;
size_t data_left_in_node = PF_NODE_SIZE - offset_in_node;
size_t size_to_read = MIN(data_left_to_read, data_left_in_node);
memcpy(out_buffer, &file_data_node->decrypted.data.data[offset_in_node], size_to_read);
pf->offset += size_to_read;
out_buffer += size_to_read;
data_left_to_read -= size_to_read;
}
if (data_left_to_read == 0 && data_attempted_to_read != size) {
// user wanted to read more and we had to shrink the request
assert(pf->offset == pf->encrypted_part_plain.size);
pf->end_of_file = true;
}
return data_attempted_to_read - data_left_to_read;
}static bool ipf_read_node(pf_context_t* pf, pf_handle_t handle, uint64_t node_number, void* buffer,
uint32_t node_size) {
uint64_t offset = node_number * node_size;
pf_status_t status = g_cb_read(handle, buffer, offset, node_size);
if (PF_FAILURE(status)) {
pf->last_error = status;
return false;
}
return true;
}ipf_write
- Check if error occurred
- Write to metadata block if there is empty space left
- Get data node (
ipf_get_data_node) and write data into the node iteratively. Besides, setneed_writingto all mht nodes in this pf.
// write zeros if `ptr` is NULL
static size_t ipf_write(pf_context_t* pf, const void* ptr, size_t size) {
if (size == 0) {
pf->last_error = PF_STATUS_INVALID_PARAMETER;
return 0;
}
size_t data_left_to_write = size;
if (PF_FAILURE(pf->file_status)) {
pf->last_error = pf->file_status;
DEBUG_PF("bad file status %d\n", pf->last_error);
return 0;
}
if (!(pf->mode & PF_FILE_MODE_WRITE)) {
pf->last_error = PF_STATUS_INVALID_MODE;
DEBUG_PF("File is read-only\n");
return 0;
}
const unsigned char* data_to_write = (const unsigned char*)ptr;
// the first block of user data is written in the meta-data encrypted part
if (pf->offset < MD_USER_DATA_SIZE) {
// offset is smaller than MD_USER_DATA_SIZE
size_t empty_place_left_in_md = MD_USER_DATA_SIZE - (size_t)pf->offset;
size_t size_to_write = MIN(data_left_to_write, empty_place_left_in_md);
memcpy_or_zero_initialize(&pf->encrypted_part_plain.data[pf->offset], data_to_write,
size_to_write);
pf->offset += size_to_write;
if (data_to_write)
data_to_write += size_to_write;
data_left_to_write -= size_to_write;
if (pf->offset > pf->encrypted_part_plain.size)
pf->encrypted_part_plain.size = pf->offset; // file grew, update the new file size
pf->need_writing = true;
}
while (data_left_to_write > 0) {
file_node_t* file_data_node = NULL;
// return the data node of the current offset, will read it from disk or create new one
// if needed (and also the mht node if needed)
file_data_node = ipf_get_data_node(pf);
if (file_data_node == NULL) {
DEBUG_PF("failed to get data node\n");
break;
}
size_t offset_in_node = (size_t)((pf->offset - MD_USER_DATA_SIZE) % PF_NODE_SIZE);
size_t empty_place_left_in_node = PF_NODE_SIZE - offset_in_node;
size_t size_to_write = MIN(data_left_to_write, empty_place_left_in_node);
memcpy_or_zero_initialize(&file_data_node->decrypted.data.data[offset_in_node],
data_to_write, size_to_write);
pf->offset += size_to_write;
if (data_to_write)
data_to_write += size_to_write;
data_left_to_write -= size_to_write;
if (pf->offset > pf->encrypted_part_plain.size) {
pf->encrypted_part_plain.size = pf->offset; // file grew, update the new file size
}
if (!file_data_node->need_writing) {
file_data_node->need_writing = true;
file_node_t* file_mht_node = file_data_node->parent;
while (file_mht_node->node_number != 0) {
// set all the mht parent nodes as 'need writing'
file_mht_node->need_writing = true;
file_mht_node = file_mht_node->parent;
}
pf->root_mht.need_writing = true;
pf->need_writing = true;
}
}
return size - data_left_to_write;
}ipf_get_data_node
- check the offset is at the edge of nodes and not in metanode
- If
offset==size, create a new node byipf_append_data_node; otherwise read the next data nodeipf_read_data_node. - "bump all the parents mht to reside before the data node in the cache"
- Do other LRU cache related operations TODO
static file_node_t* ipf_get_data_node(pf_context_t* pf) {
file_node_t* file_data_node = NULL;
if (pf->offset < MD_USER_DATA_SIZE) {
pf->last_error = PF_STATUS_UNKNOWN_ERROR;
return NULL;
}
if ((pf->offset - MD_USER_DATA_SIZE) % PF_NODE_SIZE == 0
&& pf->offset == pf->encrypted_part_plain.size) {
// new node
file_data_node = ipf_append_data_node(pf);
} else {
// existing node
file_data_node = ipf_read_data_node(pf);
}
// bump all the parents mht to reside before the data node in the cache
if (file_data_node != NULL) {
file_node_t* file_mht_node = file_data_node->parent;
while (file_mht_node->node_number != 0) {
// bump the mht node to the head of the lru
lruc_get(pf->cache, file_mht_node->physical_node_number);
file_mht_node = file_mht_node->parent;
}
}
// even if we didn't get the required data_node, we might have read other nodes in the process
while (lruc_size(pf->cache) > MAX_PAGES_IN_CACHE) {
void* data = lruc_get_last(pf->cache);
assert(data != NULL);
// for production -
if (data == NULL) {
pf->last_error = PF_STATUS_UNKNOWN_ERROR;
return NULL;
}
if (!((file_node_t*)data)->need_writing) {
lruc_remove_last(pf->cache);
// before deleting the memory, need to scrub the plain secrets
file_node_t* file_node = (file_node_t*)data;
erase_memory(&file_node->decrypted, sizeof(file_node->decrypted));
free(file_node);
} else {
if (!ipf_internal_flush(pf)) {
// error, can't flush cache, file status changed to error
assert(pf->file_status != PF_STATUS_SUCCESS);
if (pf->file_status == PF_STATUS_SUCCESS)
pf->file_status = PF_STATUS_FLUSH_ERROR; // for release set this anyway
return NULL; // even if we got the data_node!
}
}
}
return file_data_node;
}ipf_read_data_node
This function first reads the ciphertext of a node by specifying a node number and a pf, then decrypt the ciphertext using the callback function to get the plaintext. Besides, add what have been read to LRU cache.
ipf_close
- called by
pf_close - invokes
ipf_internal_flushif the status is notPF_STATUS_SUCCESS - also do some cleaning jobs on the LRU cache
ipf_internal_flush
- Check if writing is needed (for mht and other nodes)
- Update data/mht/meta nodes
- Write to disk
static bool ipf_internal_flush(pf_context_t* pf) {
if (!pf->need_writing) {
// no changes at all
DEBUG_PF("no need to write\n");
return true;
}
if (pf->encrypted_part_plain.size > MD_USER_DATA_SIZE && pf->root_mht.need_writing) {
// otherwise it's just one write - the meta-data node
if (!ipf_update_all_data_and_mht_nodes(pf)) {
// this is something that shouldn't happen, can't fix this...
pf->file_status = PF_STATUS_CRYPTO_ERROR;
DEBUG_PF("failed to update data nodes\n");
return false;
}
}
if (!ipf_update_metadata_node(pf)) {
// this is something that shouldn't happen, can't fix this...
pf->file_status = PF_STATUS_CRYPTO_ERROR;
DEBUG_PF("failed to update metadata nodes\n");
return false;
}
if (!ipf_write_all_changes_to_disk(pf)) {
pf->file_status = PF_STATUS_WRITE_TO_DISK_FAILED;
DEBUG_PF("failed to write changes to disk\n");
return false;
}
pf->need_writing = false;
return true;
}ipf_update_all_data_and_mht_nodes
This function is very complex. It iterates all nodes with need_writing flag set and do corresponding change/encryption/update
- Iterate all data nodes needing writing: generate a key for the node, store the key in its parent mht node and encrypt data, then store the gmac in the mht node
- Iterate all mht nodes needing writing: put these mht nodes into an array and sort them
- Iterate this array from the last node to the first: like what have been done to the data nodes, mht nodes also need to be maintained in a similar way.
static bool ipf_update_all_data_and_mht_nodes(pf_context_t* pf) {
bool ret = false;
file_node_t** mht_array = NULL;
file_node_t* file_mht_node;
pf_status_t status;
void* data = lruc_get_first(pf->cache);
// 1. encrypt the changed data
// 2. set the IV+GMAC in the parent MHT
// [3. set the need_writing flag for all the parents]
while (data != NULL) {
if (((file_node_t*)data)->type == FILE_DATA_NODE_TYPE) {
file_node_t* data_node = (file_node_t*)data;
if (data_node->need_writing) {
gcm_crypto_data_t* gcm_crypto_data =
&data_node->parent->decrypted.mht
.data_nodes_crypto[data_node->node_number % ATTACHED_DATA_NODES_COUNT];
if (!ipf_generate_random_key(pf, &gcm_crypto_data->key))
goto out;
// encrypt the data, this also saves the gmac of the operation in the mht crypto
// node
status = g_cb_aes_gcm_encrypt(&gcm_crypto_data->key, &g_empty_iv, NULL, 0, // aad
data_node->decrypted.data.data, PF_NODE_SIZE,
data_node->encrypted.cipher, &gcm_crypto_data->gmac);
if (PF_FAILURE(status)) {
pf->last_error = status;
goto out;
}
file_mht_node = data_node->parent;
#ifdef DEBUG
// this loop should do nothing, add it here just to be safe
while (file_mht_node->node_number != 0) {
assert(file_mht_node->need_writing == true);
file_mht_node = file_mht_node->parent;
}
#endif
}
}
data = lruc_get_next(pf->cache);
}
size_t dirty_count = 0;
// count dirty mht nodes
data = lruc_get_first(pf->cache);
while (data != NULL) {
if (((file_node_t*)data)->type == FILE_MHT_NODE_TYPE) {
if (((file_node_t*)data)->need_writing)
dirty_count++;
}
data = lruc_get_next(pf->cache);
}
// add all the mht nodes that needs writing to a list
mht_array = malloc(dirty_count * sizeof(*mht_array));
if (!mht_array) {
pf->last_error = PF_STATUS_NO_MEMORY;
goto out;
}
data = lruc_get_first(pf->cache);
uint64_t dirty_idx = 0;
while (data != NULL) {
if (((file_node_t*)data)->type == FILE_MHT_NODE_TYPE) {
file_mht_node = (file_node_t*)data;
if (file_mht_node->need_writing)
mht_array[dirty_idx++] = file_mht_node;
}
data = lruc_get_next(pf->cache);
}
if (dirty_count > 0)
sort_nodes(mht_array, 0, dirty_count - 1);
// update the gmacs in the parents from last node to first (bottom layers first)
for (dirty_idx = dirty_count; dirty_idx > 0; dirty_idx--) {
file_mht_node = mht_array[dirty_idx - 1];
gcm_crypto_data_t* gcm_crypto_data =
&file_mht_node->parent->decrypted.mht
.mht_nodes_crypto[(file_mht_node->node_number - 1) % CHILD_MHT_NODES_COUNT];
if (!ipf_generate_random_key(pf, &gcm_crypto_data->key)) {
goto out;
}
status = g_cb_aes_gcm_encrypt(&gcm_crypto_data->key, &g_empty_iv, NULL, 0,
&file_mht_node->decrypted.mht, PF_NODE_SIZE,
&file_mht_node->encrypted.cipher, &gcm_crypto_data->gmac);
if (PF_FAILURE(status)) {
pf->last_error = status;
goto out;
}
}
// update mht root gmac in the meta data node
if (!ipf_generate_random_key(pf, &pf->encrypted_part_plain.mht_key))
goto out;
status = g_cb_aes_gcm_encrypt(&pf->encrypted_part_plain.mht_key, &g_empty_iv,
NULL, 0,
&pf->root_mht.decrypted.mht, PF_NODE_SIZE,
&pf->root_mht.encrypted.cipher,
&pf->encrypted_part_plain.mht_gmac);
if (PF_FAILURE(status)) {
pf->last_error = status;
goto out;
}
ret = true;
out:
free(mht_array);
return ret;
}
''''
!! `ipf_update_metadata_node`
This function first generate a random key (derived from user's KDK) and encrypt the metadata node using this key.
!! `ipf_write_all_changes_to_disk`
Write all nodes in `pf` back to the disk. It will first write data and child mht nodes, then root mht node, and last, write the metadata node.All these functions will first check if the PF subsystem is correctly initialized (callback functions set).
pf_open
First we need to know how a PF is opened.
pf_status_t pf_open(pf_handle_t handle, const char* path, uint64_t underlying_size,
pf_file_mode_t mode, bool create, const pf_key_t* key, pf_context_t** context) {
if (!g_initialized)
return PF_STATUS_UNINITIALIZED;
pf_status_t status;
*context = ipf_open(path, mode, create, handle, underlying_size, key, &status);
return status;
}Function call trace:
pf_close
Just like pf_open, this function will be invoked in unload_protected_file or when error occurs and file needs to be closed.
pf_status_t pf_close(pf_context_t* pf) {
if (!g_initialized)
return PF_STATUS_UNINITIALIZED;
if (ipf_close(pf))
return PF_STATUS_SUCCESS;
return pf->last_error;
}pf_get_size
This function is invoked in function related to file mapping, like pf_file_map in db_files.c. Not of great interest.
pf_set_size
To truncate a file, also not very interesting.
pf_read
pf_read and pf_wirte have similar logic: seek to an appropriate position in the file and then read or wirte.
pf_status_t pf_read(pf_context_t* pf, uint64_t offset, size_t size, void* output,
size_t* bytes_read) {
if (!g_initialized)
return PF_STATUS_UNINITIALIZED;
if (!size) {
*bytes_read = 0;
return PF_STATUS_SUCCESS;
}
if (!ipf_seek(pf, offset))
return pf->last_error;
if (pf->end_of_file || pf->offset == pf->encrypted_part_plain.size) {
pf->end_of_file = true;
*bytes_read = 0;
return PF_STATUS_SUCCESS;
}
size_t bytes = ipf_read(pf, output, size);
if (!bytes)
return pf->last_error;
*bytes_read = bytes;
return PF_STATUS_SUCCESS;
}pf_write
pf_status_t pf_write(pf_context_t* pf, uint64_t offset, size_t size, const void* input) {
if (!g_initialized)
return PF_STATUS_UNINITIALIZED;
if (!ipf_seek(pf, offset))
return pf->last_error;
if (ipf_write(pf, input, size) != size)
return pf->last_error;
return PF_STATUS_SUCCESS;
}pf_flush
pf_status_t pf_flush(pf_context_t* pf) {
if (!g_initialized)
return PF_STATUS_UNINITIALIZED;
if (!ipf_internal_flush(pf))
return pf->last_error;
return PF_STATUS_SUCCESS;
}Graphene-SGX: A Practical Library OS for Unmodified Applications on SGX
LibOS in enclave + unmodified binary
Intel SGX hardware enables applications to protect themselves from potentially-malicious OSes or hypervisors. In cloud computing and other systems, many users and applications could benefit from SGX. Unfortunately, current applications will not work out-of-the-box on SGX. Although previous work has shown that a library OS can execute unmodified applications on SGX, a belief has developed that a library OS will be ruinous for performance and TCB size, making application code modification an implicit prerequisite to adopting SGX.
This paper demonstrates that these concerns are exaggerated, and that a fully-featured library OS can rapidly deploy unmodified applications on SGX with overheads comparable to applications modified to use “shim” layers. We present a port of Graphene to SGX, as well as a number of improvements to make the security benefits of SGX more usable, such as integrity support for dynamically-loaded libraries, and secure multi-process support. Graphene-SGX supports a wide range of unmodified applications, including Apache, GCC, and the R interpreter. The performance overheads of Graphene- SGX range from matching a Linux process to less than 2× in most single-process cases; these overheads are largely attributable to current SGX hardware or missed opportunities to optimize Graphene internals, and are not necessarily fundamental to leaving the application unmodified. Graphene-SGX is open-source and has been used concurrently by other groups for SGX research.

- Graphene-SGX assumes trusted binary, so it cannot protect enclave from malicious code/vulnerable code
- Graphene-SGX loads its enclave first, and let the enclave then load the so-called unmodified binary
- Interfaces are re-implemented in LibOS or export to the OS (Ocall)
- To improve performance, some Ocalls can be exitless. This is implemented through writing the arguments outside the enclave at a specific location (ocall stack) and the outside code can help execute with these args.




OSDI'23

- Huge implementation effort
- Type 1 hypervisor
- Static analysis (validator-based)
- Still need to rely on the driver (but not fully trust it)

Abstract
Software development life cycle is profoundly influenced by bugs: their introduction, identification, and eventual resolution account for a significant portion of software cost. This has motivated software engineering researchers and practitioners to propose different approaches for automating the identification and repair of software defects. Large language models have been adapted to the program repair task through few-shot demonstration learning and instruction prompting, treating this as an infilling task. However, these models have only focused on learning general bug-fixing patterns for uncategorized bugs mined from public repositories. In this paper, we propose InferFix: a transformer-based program repair framework paired with a state-of-the-art static analyzer to fix critical security and performance bugs. InferFix combines a Retriever – transformer encoder model pretrained via contrastive learning objective, which aims at searching for semantically equivalent bugs and corresponding fixes; and a Generator – a large language model (Codex Cushman) finetuned on supervised bug-fix data with prompts augmented via bug type annotations and semantically similar fixes retrieved from an external non-parametric memory. To train and evaluate our approach, we curated InferredBugs, a novel, metadata-rich dataset of bugs extracted by executing the Infer static analyzer on the change histories of thousands of Java and C# repositories. Our evaluation demonstrates that InferFix outperforms strong LLM baselines, with a top-1 accuracy of 65.6% for generating fixes in C# and 76.8% in Java. We discuss the deployment of InferFix alongside Infer at Microsoft which offers an end-to-end solution for detection, classification, and localization of bugs, as well as fixing and validation of candidate patches, integrated in the continuous integration pipeline to automate the software development workflow.
Methodology
Fine-tuned model on the task.
Gadgets
Prompt engineering methodology.
- Exploits BPU(Branch-prediction Unit)
- Train BPU to mispredict in a shadow program and observe side-channel
Intel has introduced a hardware-based trusted execution environment, Intel Software Guard Extensions (SGX), that provides a secure, isolated execution environment, or enclave, for a user program without trusting any underlying software (e.g., an operating system) or firmware. Researchers have demonstrated that SGX is vulnerable to a page-fault-based attack. However, the attack only reveals page-level memory accesses within an enclave.
In this paper, we explore a new, yet critical, sidechannel attack, branch shadowing, that reveals fine-grained control flows (branch granularity) in an enclave. The root cause of this attack is that SGX does not clear branch history when switching from enclave to non-enclave mode, leaving fine-grained traces for the outside world to observe, which gives rise to a branch-prediction side channel. However, exploiting this channel in practice is challenging because 1) measuring branch execution time is too noisy for distinguishing fine-grained control-flow changes and 2) pausing an enclave right after it has executed the code block we target requires sophisticated control. To overcome these challenges, we develop two novel exploitation techniques: 1) a last branch record (LBR)-based history-inferring technique and 2) an advanced programmable interrupt controller (APIC)-based technique to control the execution of an enclave in a fine-grained manner. An evaluation against RSA shows that our attack infers each private key bit with 99.8% accuracy. Finally, we thoroughly study the feasibility of hardware-based solutions (i.e., branch history flushing) and propose a software-based approach that mitigates the attack.


Abstract
We are now seeing increased hardware support for improving the security and performance of privilege separation and compartmentalization techniques. Today, developers can benefit from multiple compartmentalization mechanisms such as process-based sandboxes, trusted execution environments (TEEs)/enclaves, and even intra-address space compartments (i.e., intra-process or intra-enclave). We dub such a computing model a “hetero-compartment” environment and observe that existing system stacks still assume single-compartment models (i.e., user space processes), leading to limitations in using, integrating, and monitoring heterogeneous compartments from a security and performance perspective. We introduce Deluminator, a set of OS abstractions and a userspace framework to enable extensible and fine-grained information flow tracking in hetero-compartment environments. Deluminator allows developers to securely use and combine compartments, define security policies over shared system resources, and audit policy violations and perform digital forensics across heterogeneous compartments. We implemented Deluminator on Linux-based ARM and x86-64 platforms, which supports diverse compartment types ranging from processes, SGX enclaves, TrustZone Trusted Apps (TAs), and intra-address space compartments. Our evaluation shows that our kernel and hardware-assisted approach results in a reasonable overhead (on average 7-29%) that makes it suitable for real-world applications.





Abstract
Asbestos, a new prototype operating system, provides novel labeling and isolation mechanisms that help contain the effects of exploitable software flaws. Applications can express a wide range of policies with Asbestos's kernel-enforced label mechanism, including controls on inter-process communication and system-wide information flow. A new event process abstraction provides lightweight, isolated contexts within a single process, allowing the same process to act on behalf of multiple users while preventing it from leaking any single user's data to any other user. A Web server that uses Asbestos labels to isolate user data requires about 1.5 memory pages per user, demonstrating that additional security can come at an acceptable cost.
Propose a system: SVEN: property-specific continuous vectors to guide program generation towards the given property, without modifying the LM’s weights.
- Two studies: security hardening and adversarial testing
Goods
- Great evaluation result
- Lots of efforts
Questions
- Does other methods degrade the performance (i.e., functional correctness?)
- How do they evaluate functional correctness?
- Does the training set contains source code of different lanauges?
- Can we get the same performance via prompt engineering? I.e., using prompts to lead LLMs to the hidden state led by the vectors.
Interesting Things
- The refined model performs better on CWEs which are not covered in the training data.
Lacks
- Understanding: why the model performs well on other CWEs?
- Only a baseline prompt is evaluated. What about more complex prompts?
Abstract
Machine learning has been attracting strong interests in recent years. Numerous companies have invested great efforts and resources to develop customized deep-learning models, which are their key intellectual properties. In this work, we investigate to what extent the secret of deep-learning models can be inferred by attackers. In particular, we focus on the scenario that a model developer and an adversary share the same GPU when training a Deep Neural Network (DNN) model. We exploit the GPU side-channel based on context-switching penalties. This side-channel allows us to extract the fine-grained structural secret of a DNN model, including its layer composition and hyper-parameters. Leveraging this side-channel, we developed an attack prototype named MosConS, which applies LSTM-based inference models to identify the structural secret. Our evaluation of MosConS shows the structural information can be accurately recovered. Therefore, we believe new defense mechanisms should be developed to protect training against the GPU side-channel.
Method


- Shared resource: CUPTI, NVIDIA's performance counter
- CUDA, kernels, blocks => construct concurrency & GPU contention => A spy
- LSTM model training => 5 models: splitting iterations; recognizing long ops; recognizing other ops; inferring hyper-parameters; model correction
Questions
- How is GPU shared between VMs? How to avoid different drivers interfereing with each other? (especially both are root).
- Will these features(CUPTI) be available on GPUs in data centers?
Limbic System Functions
- Control of functions for self preservation
- Regulate autonomic and endocrine function in response to emotional stimuli
- Set level of arousal & involved with motivation and reinforcement
- “limbic lobe” are cortical areas that surround the corpus callosum
- “feeling and reacting brain”
- Memory systems
- Emotion systems
Fornix
- Large fiber bundle that curves around the thalamus
- Originates in hippocampus, curves forward then ventrally to connect to hypothalamus and connect to mammillary bodies
- Major output of hippocampus
- Important in declarative memory
- Degeneration of fornix precedes degeneration of hippocampus in Alzheimer’s disease
Amygdala
- Almond shaped structure that abuts the hippocampus anteriorly
- Input and output fibers are bundled
- Fibers from all sensory cortices, viscera, strong olfactory connections, and directly to and from hippocampus
- Highly implicated in emotional processing, especially fear.
- Emotional learning from high connectivity to hippocampus
- Central nucleus produces autonomic components of emotion (HR, blood pressure etc) through connections with hypothalamus
- Connections to ACC & orbitofrontal cortex involved with conscious perception of emotion
- Temporal lobe epilepsy stimulates amygdala: terror and aggression responses
- Lesions result in inability to detect fear, or respond to fearful situations
Hypothalamus
- Links CNS with endocrine system through pituitary gland for hormone release
- Controls body temp, hunger, thirst, fatigue, sleep, circadian rhythms attachment behaviors.
- Mammillary bodies of hypothalamus are highly connected to rest of limbic system (through fornix).
- Two way fiber bundles
- Also highly involved with stress and fear
Images





Meta Research
- LLM Security; twitter @llm_sec
Technical Reports
- GPT-4 Technical Report
- CodeT5+: Open Code Large Language Models for Code Understanding and Generation
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models
LLM for Security
Fuzzing
- Large Language Models are Zero-Shot Fuzzers: Fuzzing Deep-Learning Libraries via Large Language Models
- Large Language Models are Edge-Case Fuzzers: Testing Deep Learning Libraries via FuzzGPT
- Large Language Models for Fuzzing Parsers (Registered Report)
- Universal Fuzzing via Large Language Models
Program Repair
- A New Era in Software Security: Towards Self-Healing Software via Large Language Models and Formal Verification
- InferFix: End-to-End Program Repair with LLMs over Retrieval-Augmented Prompts
- Frustrated with Code Quality Issues? LLMs can Help!
- Examining Zero-Shot Vulnerability Repair with Large Language Models
Code Analysis
Test Geenration
- Large Language Models are Few-shot Testers: Exploring LLM-based General Bug Reproduction
- An Empirical Evaluation of Using Large Language Models for Automated Unit Test Generation
MISC

void Init(const IRModule& mod, const Target& target) {
InitializeLLVM();
tm_ = GetLLVMTargetMachine(target);
bool system_lib = target->GetAttr<Bool>("system-lib").value_or(Bool(false));
bool target_c_runtime = (target->GetAttr<String>("runtime").value_or("") == kTvmRuntimeCrt);
ctx_ = std::make_shared<llvm::LLVMContext>();
std::unique_ptr<CodeGenLLVM> cg = CodeGenLLVM::Create(tm_.get());
std::vector<PrimFunc> funcs;
std::string entry_func;
Map<String, LinkedParam> linked_params;
bool found_linked_params = false;
bool could_have_linked_params = target->GetAttr<Bool>("link-params").value_or(Bool(false));
for (auto kv : mod->functions) {
if (could_have_linked_params &&
kv.first->name_hint == ::tvm::runtime::symbol::tvm_lookup_linked_param) {
Map<String, ObjectRef> attrs_dict =
Downcast<Map<String, ObjectRef>>(kv.second->attrs->dict);
CHECK(attrs_dict.find(::tvm::tir::attr::kLinkedParams) != attrs_dict.end())
<< "no " << ::tvm::tir::attr::kLinkedParams << " attribute found!";
linked_params =
Downcast<Map<String, LinkedParam>>(attrs_dict[::tvm::tir::attr::kLinkedParams]);
found_linked_params = true;
continue;
}
if (!kv.second->IsInstance<PrimFuncNode>()) {
// (@jroesch): we relax constraints here, Relay functions will just be ignored.
DLOG(INFO) << "Can only lower IR Module with PrimFuncs, but got "
<< kv.second->GetTypeKey();
continue;
}
auto f = Downcast<PrimFunc>(kv.second);
auto global_symbol = f->GetAttr<String>(tvm::attr::kGlobalSymbol);
ICHECK(global_symbol.defined());
function_names_.push_back(global_symbol.value());
if (f->HasNonzeroAttr(tir::attr::kIsEntryFunc)) {
entry_func = global_symbol.value();
}
funcs.push_back(f);
}
// TODO(@jroesch): follow up on this condition.
// ICHECK(funcs.size() > 0 || (could_have_linked_params && found_linked_params));
// TODO(tqchen): remove the entry function behavior as it does not
// makes sense when we start to use multiple modules.
cg->Init("TVMMod", tm_.get(), ctx_.get(), system_lib, system_lib, target_c_runtime);
for (const auto& f : funcs) {
cg->AddFunction(f);
}
if (entry_func.length() != 0) {
cg->AddMainFunction(entry_func);
}
if (found_linked_params) {
cg->LinkParameters(linked_params);
}
module_ = cg->Finish();
module_->addModuleFlag(llvm::Module::Warning, "tvm_target",
llvm::MDString::get(*ctx_, LLVMTargetToString(target)));
module_->addModuleFlag(llvm::Module::Override, "Debug Info Version",
llvm::DEBUG_METADATA_VERSION);
if (tm_->getTargetTriple().isOSDarwin()) {
module_->addModuleFlag(llvm::Module::Override, "Dwarf Version", 2);
}
std::string verify_errors_storage;
llvm::raw_string_ostream verify_errors(verify_errors_storage);
LOG_IF(FATAL, llvm::verifyModule(*module_, &verify_errors))
<< "LLVM module verification failed with the following errors: \n"
<< verify_errors.str();
target_ = target;
mptr_ = module_.get();
}- What Was Your Prompt? A Remote Keylogging Attack on AI Assistants Usenix'24, packet length
- The Early Bird Catches the Leak: Unveiling Timing Side Channels in LLM Serving Systems arxiv, KV cache
This is an interesting work.
The idea of GPU record and replay combining with TEE can be trace back to 2021 from an arxiv paper: Safe and Practical GPU Acceleration in TrustZone. This should be the arxiv version of the ASPLOS'22 paper GPUReplay: a 50-KB GPU stack for client ML.
记录一下折腾这个笔记的过程
现在我采用的方案是 TiddlyWiki Server 的目录放在我的 Github Pages 主页中,然后每次commit之前重新生成一个 html 链接在主站上面。
插件
我使用了一些插件来支持markdown, LaTeX 等常用组件。
Cheat Sheet
- List all under a tag:
<<list-links "[tag[SGX]]">> - List tiddlers having two tags simultaneously:
<<list-links "[tag[SGX]tag[Paper]]">>
Resources from: https://images.nvidia.com/aem-dam/en-zz/Solutions/data-center/HCC-Whitepaper-v1.0.pdf
Host Side
- Secure Boot: BIOS validates the certificates of the main OS (boot loader)
- BL boots kernel, and the kernel validates the firmware (as it has access to the firmware after loaded)
- Kernel drivers query the mother board vendor: validate the certificates (stored)
- Conduct attestation of the hardware (e.g., firmware configurations)
Guest Side
The CVM still needs to ensure the GPU is trusted.
ASPLOS'20
Abstract
Intel Software Guard Extensions (SGX) enables user-level code to create private memory regions called enclaves, whose code and data are protected by the CPU from software and hardware attacks outside the enclaves. Recent work introduces library operating systems (LibOSes) to SGX so that legacy applications can run inside enclaves with few or even no modifications. As virtually any non-trivial application demands multiple processes, it is essential for LibOSes to support multitasking. However, none of the existing SGX LibOSes support multitasking both securely and efficiently.
This paper presents Occlum, a system that enables secure and efficient multitasking on SGX. We implement the LibOS processes as SFI-Isolated Processes (SIPs). SFI is a software instrumentation technique for sandboxing untrusted modules (called domains). We design a novel SFI scheme named MPX-based, Multi-Domain SFI (MMDSFI) and leverage MMDSFI to enforce the isolation of SIPs. We also design an independent verifier to ensure the security guarantees of MMDSFI. With SIPs safely sharing the single address space of an enclave, the LibOS can implement multitasking efficiently. The Occlum LibOS outperforms the state-of-the-art SGX LibOS on multitasking-heavy workloads by up to 6,600x on micro-benchmarks and up to 500x on application benchmarks.
Motivation & Target & Model
- Modern services are highly interdependent, therefore putting some service into the enclave requires some other corresponding services
- One Library OS to serve multiple process in ONE enclave
- Separation between LibOS and processes, and among processes
- Adversarial binary leaks no sensitive info
- Injecting new code is prevented, but control flow may not be guaranteed
Design
- SFI to isolate processes (MMDSFI)
- Memory access and control flow are restricted
- Thus enhance performance of certain tasks: avoid enclave creation,
fork->spawn
Method
- Two pseudo-instructions:
cfi_labelandcfi-guardto indicate a valid call site and check if the site is valid, respectively. - Binary is generated outside of enclave (using Occlum's instrumented compilier) and verified in the enclave
Opaque: An Oblivious and Encrypted Distributed Analytics Platform
- Oblivious operation on distributed platform, e.g. Spark SQL
This is an interesting work. It enforces Decentralized Information Flow Control (DIFC) using network switches and OS (using eBPF). They designed a new language to express DIFC policies and can introduce very low overhead on DIFC enforcement.
Although the project only contains 4K LoC, they've conducted extensive evaluation, and some of the evaluations were on simulated environment.
Questions
- As P4Control enforces DIFC at the file level, the tags may not be enough (e.g., only 256 different tags)?
PartEmu
- USENIX Security 2020
- Paper
- Source code unavailable
Traditional TrustZone OSes and Applications is not easy to fuzz because they cannot be instrumented or modified easily in the original hardware environment. So to emulate them for fuzzing purpose.
Targets
- Emulate TrustZone OSes(TZOS) and Trusted Applications (TAs)
- Abstract and reimplement a subset of hardware/software interfaces
- Fuzz these components
- TZOSes: QSEE, Huawei, OPTEE, Kinibi, TEEGRIS(Samsung) & TAs
Design & Method
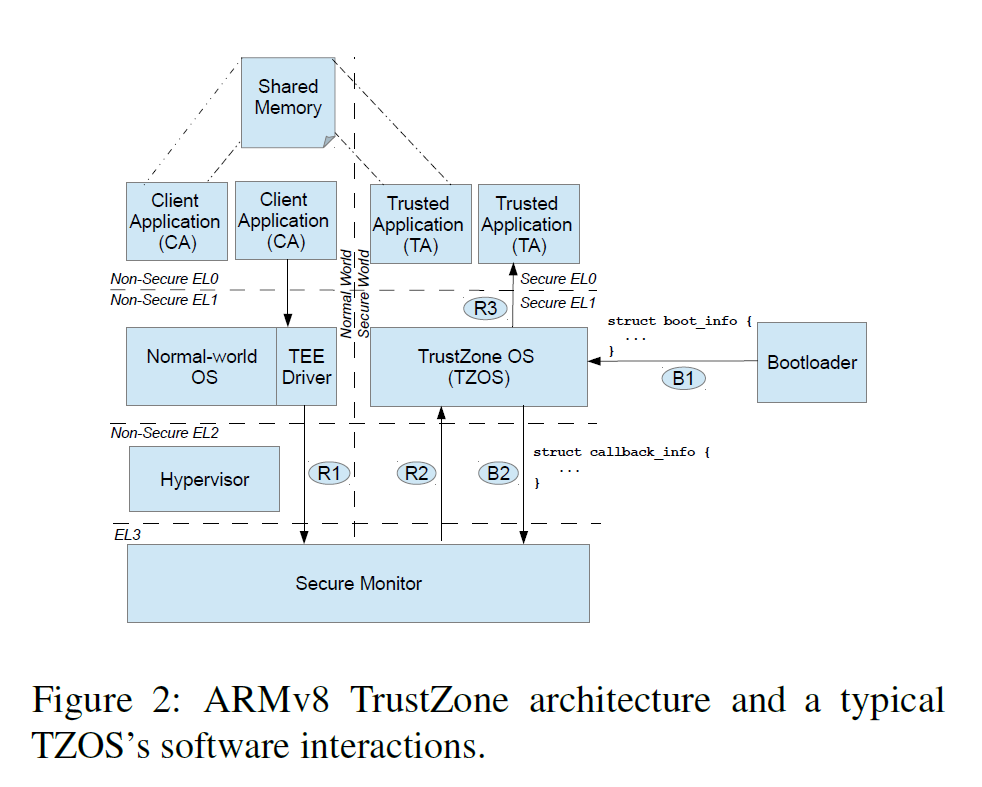
- Re-host the TZOS frimware
- Choose the components to reuse/emulate carefully
- Bootloader
- Secure Monitor
- TEE driver and TEE userspace
- MMIO registers (easy to emulate)
Tools
- TriforceAFL + QEMU
- Manually written Interfaces
Results
Emulations works well. For upgraded TZOSes, only a few efforts are needed for compatibility.
TAs
Challenges
- Identifying the fuzzed target
- Result stability (migrate to hardware, reproducibility)
- Randomness
| Class | Vulnerability Types | Crashes |
|---|---|---|
| Availability | Null-pointer dereferences | 9 |
| Insufficient shared memory crashes | 10 | |
| Other | 8 | |
| Confidentiality | Read from attacker-controlled pointer to shared memory | 8 |
| Read from attacker-controlled | 0 | |
| OOB buffer length to shared memory | ||
| Integrity | Write to secure memory using attacker-controlled pointer | 11 |
| Write to secure memory using | 2 | |
| attacker-controlled OOB buffer length |
Just like the previous paper, the main causes of the crashes can be attributed to:
- Assumptions of Normal-World Call Sequence
- Unvalidated Pointers from Normal World
- Unvalidated Types
TZOSes
- Normal-World Checks
- Assumptions of Normal-World Call Sequence
Review
Strength
- Solid work
- Efforts taken to run TZOS and TA in emulation environment
- Acceptable performance
Weakness
- Low coverage
- Crashes -X-> vulnerabilities
SGX2 Memory Integrity
Documents
- https://www.intel.com/content/dam/www/public/us/en/documents/white-papers/supporting-intel-sgx-on-mulit-socket-platforms.pdf
- https://heartever.github.io/files/scalable_sgx_public.pdf

*
Potential Attacks

- Inside-in Aliasing
- Outside-in Aliasing
Possible sources of aliasing
Server’s RAS feature
- Memory Address Range Mirroring
- Memory Predictive Failure Analysis (PFA)
PFA: if a physical memory page is believed to be affected by an underlying hardware fault (e.g., a weak cell or faulty row in a memory chip or DRAM), the affected page can be retired by relocating its content to another physical page, and placing the retired page on a list of physical pages that should not be subsequently allocated by the virtual memory system.
Documents
- https://lenovopress.lenovo.com/lp0778.pdf
- https://www.supermicro.com/manuals/other/Memory_RAS_Configuration_User_Guide.pd
Possible attack from OS?
Via Memory Components (System Software)
- Program critical system hardware devices, e.g., memory controller, DMA engines (doc1, p113) DMA is controlled by the CPU in x86-64 systems
- Program page tables/EPT => inside-in alias (doc1, p113)
Other possible attack
- Firmware <= defend by secure boot/PFR/Intel Hardware Shield (doc.2)
Documents
- https://www.intel.com/content/dam/develop/external/us/en/documents/332680-001-720907.pdf
- Intel PFR Github
Related Papers
- https://os.itec.kit.edu/downloads/publ_2017_hillenbrand_xeon_decoding.pdf
- PIkit: A New Kernel-Independent Processor-Interconnect Rootkit
- SGX Explained
TDX Problems
References

WASM bin is instrumented according to hardware configuration detected by the Prober and a configuration file. The instrumented binary is then validated and can be attested by the remote user.
- The validator works like a final binary verifier to check if the instrumentations exist as expected.
- Attestation: software attestation in PRIDWEN
Contributions
- The first platform-aware load-time synthesis framework for SGX programs
- Attestable in-enclave Wasm instrumentation and compilation toolchain.
- Extensive evaluation.
Abstract
Cloud providers are extending support for trusted hardware primitives such as Intel SGX. Simultaneously, the field of deep learning is seeing enormous innovation as well as an increase in adoption. In this paper, we ask a timely question: "Can third-party cloud services use Intel SGX enclaves to provide practical, yet secure DNN Inference-as-a-service?" We first demonstrate that DNN models executing inside enclaves are vulnerable to access pattern based attacks. We show that by simply observing access patterns, an attacker can classify encrypted inputs with 97% and 71% attack accuracy for MNIST and CIFAR10 datasets on models trained to achieve 99% and 79% original accuracy respectively. This motivates the need for PRIVADO, a system we have designed for secure, easy-to-use, and performance efficient inference-as-a-service. PRIVADO is input-oblivious: it transforms any deep learning framework that is written in C/C++ to be free of input-dependent access patterns thus eliminating the leakage. PRIVADO is fully-automated and has a low TCB: with zero developer effort, given an ONNX description of a model, it generates compact and enclave-compatible code which can be deployed on an SGX cloud platform. PRIVADO incurs low performance overhead: we use PRIVADO with Torch framework and show its overhead to be 17.18% on average on 11 different contemporary neural networks.
Model
- Service: In-enclave ML model. model is unpublic
- Users: data providers, input & output are secret
Attack
Infer the output label from memory access trace collected when the user's input is processing.
- DNN contains data-dependent branches
- A ML model (linear reg) is built up from memory access traces and the output label
- Can achieve high accuracy on inferring output tag from memory trace
Defense
- Data-dependency usually occurs at activation functions (e.g. ReLU) and max pooling, etc. Other layers merely contains data-dependent memory access.
- Eliminate the input/secret-dependency in the Torch library
- End-to-end model compilation
Abstract
Continuous compliance with privacy regulations, such as GDPR and CCPA, has become a costly burden for companies from small-sized start-ups to business giants. The culprit is the heavy reliance on human auditing in today's compliance process, which is expensive, slow, and error-prone. To address the issue, we propose PrivGuard, a novel system design that reduces human participation required and improves the productivity of the compliance process. PrivGuard is mainly comprised of two components: (1) PrivAnalyzer, a static analyzer based on abstract interpretation for partly enforcing privacy regulations, and (2) a set of components providing strong security protection on the data throughout its life cycle. To validate the effectiveness of this approach, we prototype PrivGuard and integrate it into an industrial-level data governance platform. Our case studies and evaluation show that PrivGuard can correctly enforce the encoded privacy policies on real-world programs with reasonable performance overhead.

Methodology
Users can prescribe their privacy policies, and the analyst can then leverage user data for data analysis tasks. However, the difference privacy policies are automatically enforced and satisfied by PrivGuard, which is executed inside TEE.
The policy is prescribed in a formal language, and the data analysis program is statically analyzed by PrivAnalyzer to check privacy policy compliance. PrivAnalyzer use python interpreter as a abstract interpreter to check if the privacy policies might be broken by the program. Since the python program may use a lot of 3rd party libraries, the authors purpose functions summaries for these functions and over approximate the result.
Weakness
- Intentional information leakage (analyst is assumed trusted)
- Language level bypasses
Sidenote
Some papers mentioned in this work is also interesting, especially those related to dealing with loops and branches in static analysis.
This paper may need to be checked again!
- Few Shot
Providing Examples
- Chain-of-Thought
Let's think step by step.
- Tree of Thoughts
Imagine three different experts are answering this question. All experts will write down 1 step of their thinking, then share it with the group. Then all experts will go on to the next step, etc. If any expert realises they're wrong at any point then they leave. The question is...
- Retrieval Augmented Generation
High-level idea: retrieve external source of information.
- Step-back Prompting
Survey
- Proofs for Satisfiability Problems
- Generating and Exploiting Automated Reasoning Proof Certificates
- PROOFS FOR SMT
Projects
Verifiers
- SMTCoq: A Plug-In for Integrating SMT Solvers into Coq
- CARCARA: An Efficient Proof Checker and Elaborator for SMT Proofs in the Alethe Format
- A Resolution-Based Interactive Proof System for UNSAT
Proof Formats
Work Based on Proof Checking
Abstract
Many applications, from the Web to smart contracts, need to safely execute untrusted code. We observe that WebAssembly (Wasm) is ideally positioned to support such applications, since it promises safety and performance, while serving as a compiler target for many high-level languages. However, Wasm's safety guarantees are only as strong as the implementation that enforces them. Hence, we explore two distinct approaches to producing provably sandboxed Wasm code. One draws on traditional formal methods to produce mathematical, machine-checked proofs of safety. The second carefully embeds Wasm semantics in safe Rust code such that the Rust compiler can emit safe executable code with good performance. Our implementation and evaluation of these two techniques indicate that leveraging Wasm gives us provably-safe multilingual sandboxing with performance comparable to standard, unsafe approaches.
Methodology
Two methods for securely hosting WASM code are proposed:
vWASM
Verified sandbox: proven in F*, based on a x64 machine model
rWASM
Translate WASM to Rust and using Rust compiler to compile it.
Since Rust is designed to be a memory-safe language, the compiled binary should also be safe is no unsafe code is introduced.
Insights
Building the model for machine and verifying some properties take a lot of effort! Their proof is written in F*, which leverage Z3 for automatic proving at its backend. Therefor it might be a little bit easier to use than Coq. But induction (so do inductive prove) is way more complex in F*, and programmer won't know "why" something cannot be proven when Z3 fails.
Translating WASM to Rust seems like a stupid operation. However, the performance is better when compared to vWASM. Using Rust to make potentially insecure code secure seems like a viable solution. But will there be bugs? In other words, how to maintain semantics? Logic bugs might be introduced if semantics are not consistent.
Background
Transformer
- Learn by this video YouTube: Hung-yi Lee, Transformer
- Summarized in these tweets
Questions
- How do we train those weight matrixes?
Blog Posts
Abstract
To use library APIs, a developer is supposed to follow guidance and respect some constraints, which we call integration assumptions (IAs). Violations of these assumptions can have serious consequences, introducing security-critical flaws such as use-after-free, NULL-dereference, and authentication errors. Analyzing a program for compliance with IAs involves significant effort and needs to be automated. A promising direction is to automatically recover IAs from a library document using Natural Language Processing (NLP) and then verify their consistency with the ways APIs are used in a program through code analysis. However, a practical solution along this line needs to overcome several key challenges, particularly the discovery of IAs from loosely formatted documents and interpretation of their informal descriptions to identify complicated constraints (e.g., data-/control-flow relations between different APIs).
In this paper, we present a new technique for automated assumption discovery and verification derivation from library documents. Our approach, called Advance, utilizes a suite of innovations to address those challenges. More specifically, we leverage the observation that IAs tend to express a strong sentiment in emphasizing the importance of a constraint, particularly those security-critical, and utilize a new sentiment analysis model to accurately recover them from loosely formatted documents. These IAs are further processed to identify hidden references to APIs and parameters, through an embedding model, to identify the information-flow relations expected to be followed. Then our approach runs frequent subtree mining to discover the grammatical units in IA sentences that tend to indicate some categories of constraints that could have security implications. These components are mapped to verification code snippets organized in line with the IA sentence's grammatical structure, and can be assembled into verification code executed through CodeQL to discover misuses inside a program. We implemented this design and evaluated it on 5 popular libraries (OpenSSL, SQLite, libpcap, libdbus and libxml2) and 39 real-world applications. Our analysis discovered 193 API misuses, including 139 flaws never reported before.
System

- Extract IA from the documents
- Identify the functions referred in the IA
- Generate CodeQL queries of the target API (mis)uses
Strengthes and Weaknesses
- High accuracy and low FP (how?)
- Identified a lot of previously-unknown bugs
- New dataset
- Relies heavily on well-formed documentation?
- The FN is not very low
- Generating VC takes a long while
- Resource accounting on SGX “enclaved” FaaS.
- Trusted timer: built using TSX + additional timer thread
- Model: function trusted by user, but not service provider(platform) => sandbox
- KMS, transitive attestation, encryption
- Implementation on Apache OpenWhisk
Safe, Untrusted Agents Using Proof-Carrying Code
PCC Charactristics
- General
- Low-risk & automatic
- Efficient
- Don't need to trust code producer
- Flexible
Components

The code and annotations are sent to a parser, which generates IL to be executed in a symbolic evaluator. The symbolic evaluator derives a predicate and asks an untrusted prover to solve it. The proof is encoded in Edinburgh Logical Framework. A type of proof is type checked means proving the right predicate.
Gadgets
- Invariant annotation is the most important one
- Their security policy: safe read/write; execution time bounded
Questions in the code:
- https://github.com/llvm/llvm-project/blob/main/llvm/lib/CodeGen/SafeStack.cpp#L210 what's
!C? - What's DI?
Basic Concepts
Proof Checker
Solver
Verified/Certified Solver
VeriT
- Can be used with external checkers, e.g. SMTCoq
versat: A Verified Modern SAT Solver
- No code, not usable
- Dependent Type; Guru-lang
Papers
SMT Solver Funzzing
Formal(ly Verified) SAT/SMT Solver
- A Reflexive Formalization of a SAT Solver in Coq
- Formal verification of a modern SAT solver by shallow embedding into Isabelle/HOL
Proof Checking
Also see the related articles.
Other Resources
- SMT-LIB
- Practical SAT Solving A course
Abstract
Secure hardware enclaves have been widely used for protecting security-critical applications in the cloud. However, existing enclave designs fail to meet the requirements of scalability demanded by new scenarios like serverless computing, mainly due to the limitations in their secure memory protection mechanisms, including static allocation, restricted capacity and high-cost initialization. In this paper, we propose a software-hardware co-design to support dynamic, fine-grained, large-scale secure memory as well as fast-initialization. We first introduce two new hardware primitives: 1) Guarded Page Table (GPT), which protects page table pages to support page-level secure memory isolation; 2) Mountable Merkle Tree (MMT), which supports scalable integrity protection for secure memory. Upon these two primitives, our system can scale to thousands of concurrent enclaves with high resource utilization and eliminate the high-cost initialization of secure memory using fork-style enclave creation without weakening the security guarantees.
We have implemented a prototype of our design based on Penglai, an open-sourced enclave system for RISC-V. The experimental results show that Penglai can support 1,000s enclave instances running concurrently and scale up to 512GB secure memory with both encryption and integrity protection. The overhead of GPT is 5% for memory-intensive workloads (e.g., Redis) and negligible for CPU-intensive workloads (e.g., RV8 and Coremarks). Penglai also reduces the latency of secure memory initialization by three orders of magnitude and gains 3.6x speedup for real-world applications (e.g., MapReduce).
Anatomy of Paper
Although Penglai is a very large system, this paper mainly focuses on scalability, security, and (initialization) performance of their design. This paper first introduces their motivations and the limitations of current systems (TEEs). The author them list their goals for the new design, and presents an overview.
After that, they demonstrate the new design focusing on several components.
- Memory Isolation Model (guarded page table);
- Memory Integrity (Mountable Merkle Tree), claimed challenges and novelty
- Secure Enclave Initialization (shadow fork)
- Cache-side channel mitigation (Cache Line Locking)
I don't think they follow a clear logic order to introduce the details of these aspects, but I think they tried to mention the difficulties & their solutions, and they explained them in a sensible way.
Their implementation is 2-fold, incorporating the hardware and software parts. They introduce the newly added commands, the tools & components used to realized the system, and some unimplemented functionalities.
In evaluation, they first present some microbenchmarks to show Penglai (especially the new components) only induces minor performance degradation. Then in they compare Penglai with similar systems (keystone, native, etc.) on bigger tasks. Besides, they also have 2 case studies which exhibits Penglai's strength on FaaS and distributed tasks.
Comments
I think this is a good and dense paper in general. Considering Penglai is a very huge system, the authors are clever since they focus on what made Penglai different: scalable enclave memory. However, some details are too vague and require a lot of background knowledge to understand, which is not covered in this paper. The 4 aspects in their design are scattered, and in each subsection I found no logic order, which made it difficult for understanding the big map.

Flush
- Flush if status is
OK.
bool protected_fs_file::pre_close(sgx_key_128bit_t* key, bool import)
{
int32_t result32 = 0;
bool retval = true;
sgx_status_t status = SGX_SUCCESS;
sgx_thread_mutex_lock(&mutex);
if (import == true)
{
if (use_user_kdk_key == 1) // import file is only needed for auto-key
retval = false;
else
need_writing = true; // will re-encrypt the neta-data node with local key
}
if (file_status != SGX_FILE_STATUS_OK)
{
sgx_thread_mutex_unlock(&mutex);
clear_error(); // last attempt to fix it
sgx_thread_mutex_lock(&mutex);
}
else // file_status == SGX_FILE_STATUS_OK
{
internal_flush(/*false,*/ true);
}
if (file_status != SGX_FILE_STATUS_OK)
retval = false;
if (file != NULL)
{
status = u_sgxprotectedfs_fclose(&result32, file);
if (status != SGX_SUCCESS || result32 != 0)
{
last_error = (status != SGX_SUCCESS) ? status :
(result32 != -1) ? result32 : SGX_ERROR_FILE_CLOSE_FAILED;
retval = false;
}
file = NULL;
}
if (file_status == SGX_FILE_STATUS_OK &&
last_error == SGX_SUCCESS) // else...maybe something bad happened and the recovery file will be needed
erase_recovery_file();
if (key != NULL)
{
if (use_user_kdk_key == 1) // export key is only used for auto-key
{
retval = false;
}
else
{
if (restore_current_meta_data_key(NULL) == true)
memcpy(key, cur_key, sizeof(sgx_key_128bit_t));
else
retval = false;
}
}
file_status = SGX_FILE_STATUS_CLOSED;
sgx_thread_mutex_unlock(&mutex);
return retval;
}Struct definition
typedef struct _file_data_node
{
/* these are exactly the same as file_mht_node_t above, any change should apply to both (both are saved in the cache as void*) */
uint8_t type;
uint64_t data_node_number;
file_mht_node_t* parent;
bool need_writing;
bool new_node;
union {
struct {
uint64_t physical_node_number;
encrypted_node_t encrypted; // the actual data from the disk
};
recovery_node_t recovery_node;
};
/* from here the structures are different */
data_node_t plain; // decrypted data
} file_data_node_t;This struct is nearly the same as file_mht_node_t, it seems like these are duplicated but working code.
Steps
- Write recovery file and set flags if needed
- Update data and mht nodes if needed
- Update meta data node and update flags
- Write data to the disk
- Perform the actual data write in
protected_fs_file::write_all_changes_to_disk. - LRU cache is used here for performance.
bool protected_fs_file::internal_flush(/*bool mc,*/ bool flush_to_disk)
{
if (need_writing == false) // no changes at all
return true;
if (encrypted_part_plain.size > MD_USER_DATA_SIZE && root_mht.need_writing == true) // otherwise it's just one write - the meta-data node
{
if (_RECOVERY_HOOK_(0) || write_recovery_file() != true)
{
file_status = SGX_FILE_STATUS_FLUSH_ERROR;
return false;
}
if (_RECOVERY_HOOK_(1) || set_update_flag(flush_to_disk) != true)
{
file_status = SGX_FILE_STATUS_FLUSH_ERROR;
return false;
}
if (_RECOVERY_HOOK_(2) || update_all_data_and_mht_nodes() != true)
{
clear_update_flag();
file_status = SGX_FILE_STATUS_CRYPTO_ERROR; // this is something that shouldn't happen, can't fix this...
return false;
}
}
if (_RECOVERY_HOOK_(3) || update_meta_data_node() != true)
{
clear_update_flag();
file_status = SGX_FILE_STATUS_CRYPTO_ERROR; // this is something that shouldn't happen, can't fix this...
return false;
}
if (_RECOVERY_HOOK_(4) || write_all_changes_to_disk(flush_to_disk) != true)
{
//if (mc == false)
file_status = SGX_FILE_STATUS_WRITE_TO_DISK_FAILED; // special case, need only to repeat write_all_changes_to_disk in order to repair it
//else
//file_status = SGX_FILE_STATUS_WRITE_TO_DISK_FAILED_NEED_MC; // special case, need to repeat write_all_changes_to_disk AND increase the monotonic counter in order to repair it
return false;
}
need_writing = false;
return true;
}Struct definition
typedef struct _meta_data_encrypted
{
char clean_filename[FILENAME_MAX_LEN];
int64_t size;
sgx_mc_uuid_t mc_uuid; // not used
uint32_t mc_value; // not used
sgx_aes_gcm_128bit_key_t mht_key;
sgx_aes_gcm_128bit_tag_t mht_gmac;
uint8_t data[MD_USER_DATA_SIZE];
} meta_data_encrypted_t;Construction function
- check key validity
- create report
- check if file exist
- open file
- check if it's a valid SGX SDK PF (by size)
https://github.com/intel/linux-sgx/blob/master/sdk/protected_fs/sgx_tprotected_fs/file_init.cpp
protected_fs_file::protected_fs_file(const char* filename, const char* mode, const sgx_aes_gcm_128bit_key_t* import_key, const sgx_aes_gcm_128bit_key_t* kdk_key)
{
sgx_status_t status = SGX_SUCCESS;
uint8_t result = 0;
int32_t result32 = 0;
init_fields();
if (filename == NULL || mode == NULL ||
strnlen(filename, 1) == 0 || strnlen(mode, 1) == 0)
{
last_error = EINVAL;
return;
}
if (strnlen(filename, FULLNAME_MAX_LEN) >= FULLNAME_MAX_LEN - 1)
{
last_error = ENAMETOOLONG;
return;
}
if (import_key != NULL && kdk_key != NULL)
{// import key is used only with auto generated keys
last_error = EINVAL;
return;
}
status = sgx_create_report(NULL, NULL, &report);
if (status != SGX_SUCCESS)
{
last_error = status;
return;
}
result32 = sgx_thread_mutex_init(&mutex, NULL);
if (result32 != 0)
{
last_error = result32;
return;
}
if (init_session_master_key() == false)
// last_error already set
return;
if (kdk_key != NULL)
{
// for new file, this value will later be saved in the meta data plain part (init_new_file)
// for existing file, we will later compare this value with the value from the file (init_existing_file)
use_user_kdk_key = 1;
memcpy(user_kdk_key, kdk_key, sizeof(sgx_aes_gcm_128bit_key_t));
}
// get the clean file name (original name might be clean or with relative path or with absolute path...)
char clean_filename[FILENAME_MAX_LEN];
if (cleanup_filename(filename, clean_filename) == false)
// last_error already set
return;
if (import_key != NULL)
{// verify the key is not empty - note from SAFE review
sgx_aes_gcm_128bit_key_t empty_aes_key = {0};
if (consttime_memequal(import_key, &empty_aes_key, sizeof(sgx_aes_gcm_128bit_key_t)) == 1)
{
last_error = EINVAL;
return;
}
}
if (parse_mode(mode) == false)
{
last_error = EINVAL;
return;
}
status = u_sgxprotectedfs_check_if_file_exists(&result, filename); // if result == 1 --> file exists
if (status != SGX_SUCCESS)
{
last_error = status;
return;
}
if (open_mode.write == 1 && result == 1)
{// try to delete existing file
int32_t saved_errno = 0;
result32 = remove(filename);
if (result32 != 0)
{
// either can't delete or the file was already deleted by someone else
saved_errno = errno;
errno = 0;
}
// re-check
status = u_sgxprotectedfs_check_if_file_exists(&result, filename);
if (status != SGX_SUCCESS || result == 1)
{
last_error = (status != SGX_SUCCESS) ? status :
(saved_errno != 0) ? saved_errno : EACCES;
return;
}
}
if (open_mode.read == 1 && result == 0)
{// file must exists
last_error = ENOENT;
return;
}
if (import_key != NULL && result == 0)
{// file must exists - otherwise the user key is not used
last_error = ENOENT;
return;
}
// now open the file
read_only = (open_mode.read == 1 && open_mode.update == 0); // read only files can be opened simultaneously by many enclaves
do {
status = u_sgxprotectedfs_exclusive_file_open(&file, filename, read_only, &real_file_size, &result32);
if (status != SGX_SUCCESS || file == NULL)
{
last_error = (status != SGX_SUCCESS) ? status :
(result32 != 0) ? result32 : EACCES;
break;
}
if (real_file_size < 0)
{
last_error = EINVAL;
break;
}
if (real_file_size % NODE_SIZE != 0)
{
last_error = SGX_ERROR_FILE_NOT_SGX_FILE;
break;
}
strncpy(recovery_filename, filename, FULLNAME_MAX_LEN - 1); // copy full file name
recovery_filename[FULLNAME_MAX_LEN - 1] = '\0'; // just to be safe
size_t full_name_len = strnlen(recovery_filename, RECOVERY_FILE_MAX_LEN);
strncpy(&recovery_filename[full_name_len], "_recovery", 10);
if (real_file_size > 0)
{// existing file
if (open_mode.write == 1) // redundant check, just in case
{
last_error = EACCES;
break;
}
if (init_existing_file(filename, clean_filename, import_key) == false)
break;
if (open_mode.append == 1 && open_mode.update == 0)
offset = encrypted_part_plain.size;
}
else
{// new file
if (init_new_file(clean_filename) == false)
break;
}
file_status = SGX_FILE_STATUS_OK;
} while(0);
if (file_status != SGX_FILE_STATUS_OK)
{
if (file != NULL)
{
u_sgxprotectedfs_fclose(&result32, file); // we don't care about the result
file = NULL;
}
}
}See also: C++ fwrite
Note that write only do memory cope but doesn't actually write to the disk.
- check data to write within enclave
- check if the destination can be written
- check if there is empty place left in the meta data region. If so then write
- write data to the data node(
file_data_node_t) iteratively, see below - return count
Write data
- create a new data node if needed
- write to
file_data_node->plain.data[offset_in_node] - update file size
- update writing status and mht (Merkle Hash Tree) info
size_t protected_fs_file::write(const void* ptr, size_t size, size_t count)
{
if (ptr == NULL || size == 0 || count == 0)
return 0;
int32_t result32 = sgx_thread_mutex_lock(&mutex);
if (result32 != 0)
{
last_error = result32;
file_status = SGX_FILE_STATUS_MEMORY_CORRUPTED;
return 0;
}
size_t data_left_to_write = size * count;
// prevent overlap...
#if defined(_WIN64) || defined(__x86_64__)
if (size > UINT32_MAX || count > UINT32_MAX)
{
last_error = EINVAL;
sgx_thread_mutex_unlock(&mutex);
return 0;
}
#else
if (((uint64_t)((uint64_t)size * (uint64_t)count)) != (uint64_t)data_left_to_write)
{
last_error = EINVAL;
sgx_thread_mutex_unlock(&mutex);
return 0;
}
#endif
if (sgx_is_outside_enclave(ptr, data_left_to_write))
{
last_error = SGX_ERROR_INVALID_PARAMETER;
sgx_thread_mutex_unlock(&mutex);
return 0;
}
if (file_status != SGX_FILE_STATUS_OK)
{
last_error = SGX_ERROR_FILE_BAD_STATUS;
sgx_thread_mutex_unlock(&mutex);
return 0;
}
if (open_mode.append == 0 && open_mode.update == 0 && open_mode.write == 0)
{
last_error = EACCES;
sgx_thread_mutex_unlock(&mutex);
return 0;
}
if (open_mode.append == 1)
offset = encrypted_part_plain.size; // add at the end of the file
const unsigned char* data_to_write = (const unsigned char*)ptr;
// the first block of user data is written in the meta-data encrypted part
if (offset < MD_USER_DATA_SIZE)
{
size_t empty_place_left_in_md = MD_USER_DATA_SIZE - (size_t)offset; // offset is smaller than MD_USER_DATA_SIZE
if (data_left_to_write <= empty_place_left_in_md)
{
memcpy(&encrypted_part_plain.data[offset], data_to_write, data_left_to_write);
offset += data_left_to_write;
data_to_write += data_left_to_write; // not needed, to prevent future errors
data_left_to_write = 0;
}
else
{
memcpy(&encrypted_part_plain.data[offset], data_to_write, empty_place_left_in_md);
offset += empty_place_left_in_md;
data_to_write += empty_place_left_in_md;
data_left_to_write -= empty_place_left_in_md;
}
if (offset > encrypted_part_plain.size)
encrypted_part_plain.size = offset; // file grew, update the new file size
need_writing = true;
}
while (data_left_to_write > 0)
{
file_data_node_t* file_data_node = NULL;
file_data_node = get_data_node(); // return the data node of the current offset, will read it from disk or create new one if needed (and also the mht node if needed)
if (file_data_node == NULL)
break;
size_t offset_in_node = (size_t)((offset - MD_USER_DATA_SIZE) % NODE_SIZE);
size_t empty_place_left_in_node = NODE_SIZE - offset_in_node;
if (data_left_to_write <= empty_place_left_in_node)
{ // this will be the last write
memcpy(&file_data_node->plain.data[offset_in_node], data_to_write, data_left_to_write);
offset += data_left_to_write;
data_to_write += data_left_to_write; // not needed, to prevent future errors
data_left_to_write = 0;
}
else
{
memcpy(&file_data_node->plain.data[offset_in_node], data_to_write, empty_place_left_in_node);
offset += empty_place_left_in_node;
data_to_write += empty_place_left_in_node;
data_left_to_write -= empty_place_left_in_node;
}
if (offset > encrypted_part_plain.size)
encrypted_part_plain.size = offset; // file grew, update the new file size
if (file_data_node->need_writing == false)
{
file_data_node->need_writing = true;
file_mht_node_t* file_mht_node = file_data_node->parent;
while (file_mht_node->mht_node_number != 0) // set all the mht parent nodes as 'need writing'
{
file_mht_node->need_writing = true;
file_mht_node = file_mht_node->parent;
}
root_mht.need_writing = true;
need_writing = true;
}
}
sgx_thread_mutex_unlock(&mutex);
size_t ret_count = ((size * count) - data_left_to_write) / size;
return ret_count;
}The implementations are in https://github.com/intel/linux-sgx/tree/master/sdk/protected_fs/sgx_tprotected_fs.
High Level Organization
Protected files are objects in SGX SDK's implementation. The opened PFs contains important fields like key, report and file pointer received from the OS. Data in the file is maintained as Merkle Hash Tree Nodes, and each node contains node number and encrypted/decrypted data in its struct. Besides, metadata is also stored in a meta node, which includes MAC, key, file id and version info about CPU/ISV/PF. The encryption scheme is rijndael 128 GCM (AES 128 GCM) algorithm. To ensure PF operations are atomic, it also recruits mutex mechanism.
All the internal interfaces in the enclave relies on the untrusted code to perform file operations by OS. Those interfaces are in https://github.com/intel/linux-sgx/tree/master/sdk/protected_fs/sgx_uprotected_fs, and are of less interest.
Encryption
sgx_status_t sgx_rijndael128GCM_encrypt(const sgx_aes_gcm_128bit_key_t *p_key, const uint8_t *p_src, uint32_t src_len, uint8_t *p_dst, const uint8_t *p_iv, uint32_t iv_len, const uint8_t *p_aad, uint32_t aad_len, sgx_aes_gcm_128bit_tag_t *p_out_mac)Decryption
sgx_status_t sgx_rijndael128GCM_decrypt(const sgx_aes_gcm_128bit_key_t *p_key, const uint8_t *p_src, uint32_t src_len, uint8_t *p_dst, const uint8_t *p_iv, uint32_t iv_len, const uint8_t *p_aad, uint32_t aad_len, const sgx_aes_gcm_128bit_tag_t *p_in_mac)See also:
SDK_PF_New (protected_fs_file::protected_fs_file)
SDK_ProtectedFileClass
Internal APIs
Open
- new
protected_fs_file(SDK_PF_New) - if no error, return handle
static SGX_FILE* sgx_fopen_internal(const char* filename, const char* mode, const sgx_key_128bit_t *auto_key, const sgx_key_128bit_t *kdk_key)
{
protected_fs_file* file = NULL;
if (filename == NULL || mode == NULL)
{
errno = EINVAL;
return NULL;
}
try {
file = new protected_fs_file(filename, mode, auto_key, kdk_key);
}
catch (std::bad_alloc& e) {
(void)e; // remove warning
errno = ENOMEM;
return NULL;
}
if (file->get_error() != SGX_FILE_STATUS_OK)
{
errno = file->get_error();
delete file;
file = NULL;
}
return (SGX_FILE*)file;
}Write
size_t sgx_fwrite(const void* ptr, size_t size, size_t count, SGX_FILE* stream)
{
if (ptr == NULL || stream == NULL || size == 0 || count == 0)
return 0;
protected_fs_file* file = (protected_fs_file*)stream;
return file->write(ptr, size, count);
}Close
int32_t sgx_fclose(SGX_FILE* stream)
{
return sgx_fclose_internal(stream, NULL, false);
}
static int32_t sgx_fclose_internal(SGX_FILE* stream, sgx_key_128bit_t *key, bool import)
{
int32_t retval = 0;
if (stream == NULL)
return EOF;
protected_fs_file* file = (protected_fs_file*)stream;
if (file->pre_close(key, import) == false)
retval = 1;
delete file;
return retval;
}Flush
Flush performs the actual encryption and write.
User level APIs are in https://github.com/intel/linux-sgx/blob/master/common/inc/sgx_tprotected_fs.h,
See also: Implementation
/* sgx_fopen
* Purpose: open existing protected file (created with previous call to sgc_fopen) or create a new one (see c++ fopen documentation for more details).
*
* Parameters:
* filename - [IN] the name of the file to open/create.
* mode - [IN] open mode. only supports 'r' or 'w' or 'a' (one and only one of them must be present), and optionally 'b' and/or '+'.
* key - [IN] encryption key that will be used for the file encryption
* NOTE - the key is actually used as a KDK (key derivation key) and only for the meta-data node, and not used directly for the encryption of any part of the file
* this is important in order to prevent hitting the key wear-out problem, and some other issues with GCM encryptions using the same key
*
* Return value:
* SGX_FILE* - pointer to the newly created file handle, NULL if an error occurred - check errno for the error code.
*/
SGX_FILE* SGXAPI sgx_fopen(const char* filename, const char* mode, const sgx_key_128bit_t *key);
/* sgx_fwrite
* Purpose: write data to a file (see c++ fwrite documentation for more details).
*
* Parameters:
* ptr - [IN] pointer to the input data buffer
* size - [IN] size of data block
* count - [IN] count of data blocks to write
* stream - [IN] the file handle (opened with sgx_fopen or sgx_fopen_auto_key)
*
* Return value:
* size_t - number of 'size' blocks written to the file, 0 in case of an error - check sgx_ferror for error code
*/
size_t SGXAPI sgx_fwrite(const void* ptr, size_t size, size_t count, SGX_FILE* stream);
/* sgx_fread
* Purpose: read data from a file (see c++ fread documentation for more details).
*
* Parameters:
* ptr - [OUT] pointer to the output data buffer
* size - [IN] size of data block
* count - [IN] count of data blocks to write
* stream - [IN] the file handle (opened with sgx_fopen or sgx_fopen_auto_key)
*
* Return value:
* size_t - number of 'size' blocks read from the file, 0 in case of an error - check sgx_ferror for error code
*/
size_t SGXAPI sgx_fread(void* ptr, size_t size, size_t count, SGX_FILE* stream);
/* sgx_fflush
* Purpose: force actual write of all the cached data to the disk (see c++ fflush documentation for more details).
*
* Parameters:
* stream - [IN] the file handle (opened with sgx_fopen or sgx_fopen_auto_key)
*
* Return value:
* int32_t - result, 0 on success, 1 in case of an error - check sgx_ferror for error code
*/
int32_t SGXAPI sgx_fflush(SGX_FILE* stream);
int32_t SGXAPI sgx_fclose(SGX_FILE* stream);
int64_t SGXAPI sgx_ftell(SGX_FILE* stream);
int32_t SGXAPI sgx_fseek(SGX_FILE* stream, int64_t offset, int origin);
...Abstract
Trusted hardware systems, such as Intel's new SGX instruction set architecture extension, aim to provide strong confidentiality and integrity assurances for applications. Recent work, however, raises serious concerns about the vulnerability of such systems to side-channel attacks. We propose, formalize, and explore a cryptographic primitive called a Sealed-Glass Proof (SGP) that models computation possible in an isolated execution environment with unbounded leakage, and thus in the face of arbitrary side-channels. A SGP specifically models the capabilities of trusted hardware that can attest to correct execution of a piece of code, but whose execution is transparent, meaning that an application's secrets and state are visible to other processes on the same host. Despite this strong threat model, we show that SGPs enable a range of practical applications. Our key observation is that SGPs permit safe verifiable computing in zero-knowledge, as data leakage results only in the prover learning her own secrets. Among other applications, we describe the implementation of an end-to-end bug bounty (or zero-day solicitation) platform that couples a SGX-based SGP with a smart contract. Our platform enables a marketplace that achieves fair exchange, protects against unfair bounty withdrawals, and resists denial-of-service attacks by dishonest sellers. We also consider a slight relaxation of the SGP model that permits black-box modules instantiating minimal, side-channel resistant primitives, yielding a still broader range of applications. Our work shows how trusted hardware systems such as SGX can support trustworthy applications even in the presence of side channels.
Overview
- Transparent enclave execution (protects integrity)
- Sealed-Glass Proofs -> verifiable computing, commitment schemes, ZK proofs
- SGP -> smart contract -> knowledge marketplace -> bug bounty
Important building blocks




Important Gadgets
- Secret (of the prover) is processed on prover's host, therefore the system is resistant to side-channel
- Multiple provers is also permitted by an extended design
- A bug bounty mechanism needs careful design to protect the buyer and sellers
Secure Computation is not what I think.
Generally speaking, secure computation is to let 2(or more) mutually distrusted parties compute on both parties' data without exposing the plaintext of the data.
This problem originates in this paper: Protocols for Secure Computations (PDF). The famous millionaires' problem came from this paper and then Garbled Circuit(Wiki) became popular in this field. Dr. Qizhi Yao is the initiator of field and he is also the founder of several other fields in crypto and computer theory.
Related Projects
Related Papers
Intel Software Guard Extensions (SGX) offers strong confidentialityand integrity protection to software programs running in untrustedoperating systems. Unfortunately, SGX may be abused by attackersto shield suspicious payloads and conceal misbehaviors in SGXenclaves, which cannot be easily detected by existing defense solu-tions. There is no comprehensive study conducted to characterizemalicious enclaves. In this paper, we present the first systematicstudy that scrutinizes all possible interaction interfaces betweenenclaves and the outside (i.e., cache-memory hierarchy, host vir-tual memory, and enclave-mode transitions), and identifies sevenattack vectors. Moreover, we proposeSGX-Bouncer, a detectionframework that can detect these attacks by leveraging multifariousside-channel observations and SGX-specific features. We conductempirical evaluations with existing malicious SGX applications,which suggestsSGX-Bouncercan effectively detect various abnor-mal behaviors from malicious enclaves.
Abstract
Network administrators face a security-critical dilemma. While they want to tightly contain their hosts, they usually have to relax firewall policies to support a large variety of applications. However, liberal policies like this enable data exfiltration by unknown (and untrusted) client applications. An inability to attribute communication accurately and reliably to applications is at the heart of this problem. Firewall policies are restricted to coarse-grained features that are easy to evade and mimic, such as protocols or port numbers.
We present SENG, a network gateway that enables firewalls to reliably attribute traffic to an application. SENG shields an application in an SGX-tailored LibOS and transparently establishes an attestation-based DTLS channel between the SGX enclave and the central network gateway. Consequently, administrators can perfectly attribute traffic to its originating application, and thereby enforce fine-grained per-application communication policies at a central firewall. Our prototype implementation demonstrates that SENG (i) allows administrators to readily use their favorite firewall to enforce network policies on a certified per-application basis and (ii) prevents local system-level attackers from interfering with the shielded application's communication.
Design


Challenges
- EPC Memory Limit (SGX)
- Frequent Measurement Update (of Apps)
- Deployment: Mixed Environment, updates (of SENG), key management
Comments
This paper mainly focuses on what are the benefits of putting a firewall into the enclave. Especially, what kind of protection can be provided and what kind of attacks can be defended.
White Papers
Architectural Changes
- C-bit: denoting the page is encrypted/not
- Reverse Map Table (RMP): check the owner of the accessed pages
- VMPL
- vTOM (virtual top of memory): memory below vTOM is private and above vTOM is shared.
Questions
- New CPU instructions enables RMP's manipulation, and these instructions are performed by the hyper => how to ensure that the hypervisor conducts these tasks in a trustworthy way? There is a Validated bit that is set by the guest via a new CPU instruction,
PVALIDATE. - How, for the guest VMs, to know that the page is valid?
Middlewares
Container-like
- Graphene-SGX Paper Code
- Occlum Paper Code
- Scone Official Website Paper PDF Source Code Unavailable
- Ryoan Paper Code doesn't work now
- Chancel
- SGX-LKL Paper Code
- RATEL
- CAT
Need updates - Civet Paper (graphene)
- Enarx
- Oak
- Mystikos
Language-specific
SDK/API/Runtimes
- Intel SGX Code
- Google Asylo Code
- Open Enclave Code
- Fortanix Rust EDP Code
- Teaclave SGX SDK (Rust-SGX) Paper PDF Code
- Panoply Code Inactive
Parallel
Attacks
Meta
Official Documents
Reviews
Attacks:
- A Tale of Two Worlds: Assessing the Vulnerability of Enclave Shielding Runtimes
- COIN Attacks: On Insecurity of Enclave Untrusted Interfaces in SGX
- Controlled-Channel Attacks: Deterministic SideChannels for Untrusted Operating Systems
- Emilia: Catching Iago in Legacy Code
- Inferring Fine-grained Control Flow Inside SGX Enclaves with Branch Shadowing
- Privado: Practical and Secure DNN Inference with Enclaves
- Software Grand Exposure: SGX Cache Attacks Are Practical
Defenses:
- A Design and Verification Methodology for Secure Isolated Regions
- Achieving Keyless CDNs with Conclaves
- BlackMirror: Preventing Wallhacks in 3D Online FPS Games
- CHANCEL: Efficient Multi-client Isolation Under Adversarial Programs
- Occlum: Secure and Efficient Multitasking Inside a Single Enclave of Intel SGX
- Opaque: An Oblivious and Encrypted Distributed Analytics Platform
- PRIDWEN: Universally Hardening SGX Programs via Load-Time Synthesis
- Privado: Practical and Secure DNN Inference with Enclaves
- See through Walls: Detecting Malware in SGX Enclaves with SGX-Bouncer
- SENG, the SGX-Enforcing Network Gateway: Authorizing Communication from Shielded Clients
- SinClave: Hardware-assisted Singletons for TEEs
- Varys: Protecting SGX Enclaves from Practical Side-Channel Attacks
Applications:
- Achieving Keyless CDNs with Conclaves
- DelegaTEE: Brokered Delegation Using Trusted Execution Environments
- S-FaaS: Trustworthy and Accountable Function-as-a-Service using Intel SGX
- SENG, the SGX-Enforcing Network Gateway: Authorizing Communication from Shielded Clients
See also:
- A Formal Foundation for Secure Remote Execution of Enclaves
- AccTEE: A WebAssembly-based Two-way Sandbox for Trusted Resource Accounting
- An efficient and secure scheme of verifiable computation for Intel SGX
- BesFS: A POSIX Filesystem for Enclaves with a Mechanized Safety Proof
- Clemmys: Towards Secure Remote Execution in FaaS
- Dynamic Binary Translation for SGX Enclaves (Ratel)
- GrapheneSGX
- Machine Learning with Confidential Computing: A Systematization of Knowledge
- Sealed-Glass Proofs: Using Transparent Enclaves to Prove and Sell Knowledge
- Securing TEEs with Verifiable Execution Contracts
- SGX Posts
- SGXFUZZ: Efficiently Synthesizing Nested Structures for SGX Enclave Fuzzing
- SoK: SGX.Fail: How Stuff Gets eXposed
- Towards Formal Verification of State Continuity for Enclave Programs
- Trust more, serverless
- Web Assembly+ SGX
Related materials other than paper
- Disk Encryption in CVMs
- FaaS Papers, mainly in TEE
- Graphene-SGX PF
- Graphene-SGX PF Callbacks
- Graphene-SGX PF Data Structure
- Graphene-SGX PF Implementation
- Graphene-SGX PF Internal
- Graphene-SGX PF User Interfaces
- Potential Threats of Memory Integrity on SEV(SNP), (Scalable) SGX2, and TDX
- SDK_PF_Close
- SDK_PF_DataNode
- SDK_PF_Flush
- SDK_PF_metadata
- SDK_PF_New
- SDK_PF_Write
- SDK_PFImplementations
- SDK_PFUserInterfaces
- SGX Application Papers
- SGX Documents
- SGX Middleware (Papers)
- SGX_PF_Class
- Side-Channel Meta
- Teaclave
- Teaclave Commands
- TEEPapers
- Trusted Computing Base TCB
- Virtualization in SGX
- WAMR Installation & run in SGX enclave
- WAMR+Teaclave
class protected_fs_file
{
private:
union {
struct {
uint64_t meta_data_node_number; // for recovery purpose, so it is easy to write this node
meta_data_node_t file_meta_data; // actual data from disk's meta data node
};
recovery_node_t meta_data_recovery_node;
};
meta_data_encrypted_t encrypted_part_plain; // encrypted part of meta data node, decrypted
file_mht_node_t root_mht; // the root of the mht is always needed (for files bigger than 3KB)
FILE* file; // OS's FILE pointer
open_mode_t open_mode;
uint8_t read_only;
int64_t offset; // current file position (user's view)
bool end_of_file; // flag
int64_t real_file_size;
bool need_writing; // flag
uint32_t last_error; // last operation error
protected_fs_status_e file_status;
sgx_thread_mutex_t mutex;
uint8_t use_user_kdk_key;
sgx_aes_gcm_128bit_key_t user_kdk_key; // recieved from user, used instead of the seal key
sgx_aes_gcm_128bit_key_t cur_key;
sgx_aes_gcm_128bit_key_t session_master_key;
uint32_t master_key_count;
char recovery_filename[RECOVERY_FILE_MAX_LEN]; // might include full path to the file
lru_cache cache;
// these don't change after init...
sgx_iv_t empty_iv;
sgx_report_t report;
void init_fields();
bool cleanup_filename(const char* src, char* dest);
bool parse_mode(const char* mode);
bool file_recovery(const char* filename);
bool init_existing_file(const char* filename, const char* clean_filename, const sgx_aes_gcm_128bit_key_t* import_key);
bool init_new_file(const char* clean_filename);
bool generate_secure_blob(sgx_aes_gcm_128bit_key_t* key, const char* label, uint64_t physical_node_number, sgx_aes_gcm_128bit_tag_t* output);
bool generate_secure_blob_from_user_kdk(bool restore);
bool init_session_master_key();
bool derive_random_node_key(uint64_t physical_node_number);
bool generate_random_meta_data_key();
bool restore_current_meta_data_key(const sgx_aes_gcm_128bit_key_t* import_key);
file_data_node_t* get_data_node();
file_data_node_t* read_data_node();
file_data_node_t* append_data_node();
file_mht_node_t* get_mht_node();
file_mht_node_t* read_mht_node(uint64_t mht_node_number);
file_mht_node_t* append_mht_node(uint64_t mht_node_number);
bool write_recovery_file();
bool set_update_flag(bool flush_to_disk);
void clear_update_flag();
bool update_all_data_and_mht_nodes();
bool update_meta_data_node();
bool write_all_changes_to_disk(bool flush_to_disk);
void erase_recovery_file();
bool internal_flush(/*bool mc,*/ bool flush_to_disk);
public:
protected_fs_file(const char* filename, const char* mode, const sgx_aes_gcm_128bit_key_t* import_key, const sgx_aes_gcm_128bit_key_t* kdk_key);
~protected_fs_file();
size_t write(const void* ptr, size_t size, size_t count);
size_t read(void* ptr, size_t size, size_t count);
int64_t tell();
int seek(int64_t new_offset, int origin);
bool get_eof();
uint32_t get_error();
void clear_error();
int32_t clear_cache();
bool flush(/*bool mc*/);
bool pre_close(sgx_key_128bit_t* key, bool import);
static int32_t remove(const char* filename);
};Abstract
Intel's Software Guard Extensions (SGX) provide a nonintrospectable trusted execution environment (TEE) to protect security-critical code from a potentially malicious OS. This protection can only be effective if the individual enclaves are secure, which is already challenging in regular software, and this becomes even more difficult for enclaves as the entire environment is potentially malicious. As such, many enclaves expose common vulnerabilities, e.g., memory corruption and SGXspecific vulnerabilities like null-pointer dereferences. While fuzzing is a popular technique to assess the security of software, dynamically analyzing enclaves is challenging as enclaves are meant to be non-introspectable. Further, they expect an allocated multi-pointer structure as input instead of a plain buffer.
In this paper, we present SGXFUZZ, a coverage-guided fuzzer that introduces a novel binary input structure synthesis method to expose enclave vulnerabilities even without source-code access. To obtain code coverage feedback from enclaves, we show how to extract enclave code from distribution formats. We also present an enclave runner that allows execution of the extracted enclave code as a user-space application at native speed, while emulating all relevant environment interactions of the enclave. We use this setup to fuzz enclaves using a state-of-the-art snapshot fuzzing engine that deploys our novel structure synthesis stage. This stage synthesizes multi-layer pointer structures and size fields incrementally on-the-fly based on fault signals. Furthermore, it matches the expected input format of the enclave without any prior knowledge. We evaluate our approach on 30 open- and closed-source enclaves and found a total of 79 new bugs and vulnerabilities.
Contributions
- Enclave Dumping: Using the SGX driver, we completely extract executable enclave code on Windows and Linux in an automated way.
- Enclave Runner: We show how to execute enclave code, including SGX-specific instructions, natively outside SGX to retrieve code coverage feedback.
- Structure Synthesis: We present a method to synthesize multi-layer structures of pointers, arrays, and size fields using fuzzing.
- Memory Location Havoc: To analyze whether enclaves are vulnerable to trust-boundary attacks, we develop a fuzzing stage that tries different memory locations for each of the pointers in the synthesized structure.
- Fuzz Analysis: Utilizing the methods developed in this work, we analyze the security of 30 enclaves and found 79 new bugs and vulnerabilities. So far, a total of three CVEs were assigned and $13k in bug bounty were paid for the vulnerabilities we identified.
- Limitations of Symbolic Execution: We analyze previous work on vulnerability detection using symbolic execution, discuss limitations, and extensively compare the results with SGXFUZZ.
I believe the most novel one in this paper is Structure Synthesis, which may also be related to another work.
Design


Oh-my-zsh
sh -c "$(curl -fsSL https://raw.github.com/ohmyzsh/ohmyzsh/master/tools/install.sh)"
# or
sh -c "$(wget https://raw.github.com/ohmyzsh/ohmyzsh/master/tools/install.sh -O -)"zsh-autosuggestions
git clone https://github.com/zsh-users/zsh-autosuggestions ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-autosuggestions
# add to .zshrc
plugins=(
# other plugins...
zsh-autosuggestions
)
# or manually
source ~/.zsh/zsh-autosuggestions/zsh-autosuggestions.zsh
zsh-syntax-highlighting
git clone https://github.com/zsh-users/zsh-syntax-highlighting.git ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-syntax-highlighting
# and
plugins=( [plugins...] zsh-syntax-highlighting)
# or
source /usr/local/share/zsh-syntax-highlighting/zsh-syntax-highlighting.zshAttacks
- A Systematic Look at Ciphertext Side Channels on AMD SEV-SNP
- Controlled-Channel Attacks: Deterministic SideChannels for Untrusted Operating Systems
- Exploiting Unprotected I/O Operations in AMD’s Secure Encrypted Virtualization
- Inferring Fine-grained Control Flow Inside SGX Enclaves with Branch Shadowing
- Leaky DNN: Stealing Deep-learning Model Secret with GPU Context-switching Side-channel
- LM Side-channel
- Privado: Practical and Secure DNN Inference with Enclaves
- Software Grand Exposure: SGX Cache Attacks Are Practical
Defenses
- A Survey on Mix Networks and Their Secure Applications
- Constant-Time Foundations for the New Spectre Era
- PRIDWEN: Universally Hardening SGX Programs via Load-Time Synthesis
- Privado: Practical and Secure DNN Inference with Enclaves
- Varys: Protecting SGX Enclaves from Practical Side-Channel Attacks
SGX-related
- Controlled-Channel Attacks: Deterministic SideChannels for Untrusted Operating Systems
- Inferring Fine-grained Control Flow Inside SGX Enclaves with Branch Shadowing
- PRIDWEN: Universally Hardening SGX Programs via Load-Time Synthesis
- Privado: Practical and Secure DNN Inference with Enclaves
- Sealed-Glass Proofs: Using Transparent Enclaves to Prove and Sell Knowledge
- SGX Posts
- Software Grand Exposure: SGX Cache Attacks Are Practical
- Varys: Protecting SGX Enclaves from Practical Side-Channel Attacks
PDF Middleware ’23
Attack

If the software’s configuration that is not reflected in the enclave measurement (§ 3.3) dictates the to-be-loaded program, the adversary can simply start a report server implementation.
- Is it correct? Yes, at least for SCONE.
Defense

The basic idea behind our solution is that system software adds an additional page, the instance page (see Figure 5), to the enclave dynamically during enclave construction. This page, in particular, contains an attestation token, and the verifier’s cryptographic identity. The attestation token is unique and generated by the verifier in a previous step.
- How can SinClave ensure that such token is securely protected (i.e., not leaked to the adversary)?
Diving into this topic, I found that there are plenty of questions regarding this idea.
Questions
- What are the motivations?
- Reducing available gadgets seems like a good motivation, but it's not clear whether this can enhance software security. There seems to be other factors: whether these gadgets are exploitable?
- How to measure the effectiveness of debloating?
- This is a more complex question. As 1) how to assure the trimmed software components are not used by users? and 2) how to claim the security is indeed enhanced?
- The metrics seem to be too indirect. For example, reduced #gadgets cannot represent how many exploitable vulnerabilities are fixed.
- It seems to me this idea aligns conditional compilation. What are the differences?
Papers
Is Less Really More? Towards Better Metrics for Measuring Security Improvements Realized Through Software Debloating
This work points out that although #gadgets is can be reduced by some of the debloating tools, they sometimes actually introduce more gadgets that enhances the expressiveness of potential attacks. However, it's still not clear to me whether these introduced gadgets are indeed exploitable.
A Broad Comparative Evaluation of Software Debloating Tools
This work is more interesting. Seems like nearly all of the existing tools designed for software debloating are effective neither on security nor performance.
Potential Directions
Maybe LLMs can aid this? Found an interesting paper: LPR: Large Language Models-Aided Program Reduction
Intel SGX isolates the memory of security-critical applications from the untrusted OS. However, it has been speculated that SGX may be vulnerable to side-channel attacks through shared caches. We developed new cache attack techniques customized for SGX. Our attack differs from other SGX cache attacks in that it is easy to deploy and avoids known detection approaches. We demonstrate the effectiveness of our attack on two case studies: RSA decryption and genomic processing. While cache timing attacks against RSA and other cryptographic operations can be prevented by using appropriately hardened crypto libraries, the same cannot be easily done for other computations, such as genomic processing. Our second case study therefore shows that attacks on non-cryptographic but privacy sensitive operations are a serious threat. We analyze countermeasures and show that none of the known defenses eliminates the attack.

- L1 cache
- Prime + Probe
In Figure 2, the attacker will observe an increased access time for cache line 2. Since the attacker knows the code and access pattern of the victim, he knows that address X of the victim maps to cache line 2, and that the sensitive key-bit must be zero.
Techniques
- Constraint solving
- Symbolic value generation & searching
Challenges
- Path Explosion
- Constraint Solving
- Memory modeling
- Concurrency
Solutions
- Concolic execution
- Imprecision vs. completeness in dynamic symbolic exe- cution
By topic
FaaS Papers, mainly in TEE
Generated List of Papers:
- A Design and Verification Methodology for Secure Isolated Regions
- A Formal Foundation for Secure Remote Execution of Enclaves
- A Study of Modern Linux API Usage and Compatibility: What to Support When You’re Supporting
- A Survey on Mix Networks and Their Secure Applications
- A Systematic Look at Ciphertext Side Channels on AMD SEV-SNP
- AccTEE: A WebAssembly-based Two-way Sandbox for Trusted Resource Accounting
- AddressSanitizer: A fast address sanity checker
- Agamotto: Accelerating Kernel Driver Fuzzing with Lightweight Virtual Machine Checkpoints
- BesFS: A POSIX Filesystem for Enclaves with a Mechanized Safety Proof
- Building GPU TEEs using CPU Secure Enclaves with GEVisor
- CHANCEL: Efficient Multi-client Isolation Under Adversarial Programs
- Clemmys: Towards Secure Remote Execution in FaaS
- ConfLLVM: A Compiler for Enforcing Data Confidentiality in Low-Level Code
- Data-Oriented Programming: On the Expressiveness of Non-Control Data Attacks
- Dune: Safe User-level Access to Privileged CPU Features
- Empirical Study Towards a Leading Indicator for Cost of Formal Software Verification
- Expressing Information Flow Properties
- GrapheneSGX
- Honeycomb: Secure and Efficient GPU Executions via Static Validation
- Information Flow Tracking for Heterogeneous Compartmentalized Software
- Labels and event processes in the asbestos operating system
- Machine Learning with Confidential Computing: A Systematization of Knowledge
- Occlum: Secure and Efficient Multitasking Inside a Single Enclave of Intel SGX
- Opaque: An Oblivious and Encrypted Distributed Analytics Platform
- P4CONTROL: Line-Rate Cross-Host Attack Prevention via In-Network Information Flow Control Enabled by Programmable Switches and eBPF
- PARTEMU: Enabling Dynamic Analysis of Real-World TrustZone Software Using Emulation
- PCC: Conventional and Foundational
- PRIDWEN: Universally Hardening SGX Programs via Load-Time Synthesis
- PrivGuard: Privacy Regulation Compliance Made Easier
- Proof Checking/Verification for SMT Solvers
- Provably-Safe Multilingual Software Sandboxing using WebAssembly
- S-FaaS: Trustworthy and Accountable Function-as-a-Service using Intel SGX
- SafeStack & CPI
- Scalable Memory Protection in the Penglai Enclave
- Securing TEEs with Verifiable Execution Contracts
- SGX Posts
- SinClave: Hardware-assisted Singletons for TEEs
- Software Debloating
- SoK: SGX.Fail: How Stuff Gets eXposed
- Towards Demystifying Serverless Machine Learning Training
- Trust more, serverless
- Using Lightweight Formal Methods to Validate a Key-Value Storage Node in Amazon S3
- Why3: Shepherd Your Herd of Provers
- Доверя́й, но проверя́й: SFI safety for native-compiled Wasm
Interesting Things
- TDX defends agains side-channel attacks?
an example of such policy would be the module using the Indirect- Branch- Prediction Barrier (IBPB) when switching TDs to help keep a TD-indirect-branch prediction from being influenced by code in a previously executed TD.
From whitepaper.
- PAMT (Physical-Address-Metadata Table) tracks pages mapped into the TD. Similar to RMP in SEV-SNP.
- TD partitioning: TD Partitioning extends the base TDX architecture by allowing TDs to contain multiple virtual machines (VMs).
- TD Preserving Architecture provides the ability to update TDX Module at runtime, while persisting TD State and minimum TD interruption.
- Two EPTs: Secure Extended page table (private key ID + PA) and Shared Extended
(shared key ID + PA) page table
Questions
- Are the states of a TD encrypted?
Run
(cd docker && docker-compose -f docker-compose-ubuntu-1804-sgx-sim-mode.yml up --build)
SGX_MODE=SW PYTHONPATH=../../sdk/python python3 wasm_tvm_mnist.py
docker run --rm -it -v $(pwd):/teaclave -w /teaclave teaclave/teaclave-build-ubuntu-1804-sgx-2.14:latest
The case is a bit more complex on ARM. This is like Intel, where TDX and SGX coexists.
However, the things are different and more complex.

- Root: the combination of the Root security state and Root physical address space.
- Normal: like the host on X86
- Secure: has a Trusted OS (TOS). Virtualization to the Secure world allows you to manage multiple Secure Partitions in the Secure world. The Secure Partition Manager (SPM) has a similar functionality to the hypervisor in the Normal world.
- Realm: contains confidential VM launched in the normal world.
Abstract
Static analysis is a widely used technique in software engineering for identifying and mitigating bugs. However, a significant hurdle lies in achieving a delicate balance between precision and scalability. Large Language Models (LLMs) offer a promising alternative, as recent advances demonstrate remarkable capabilities in comprehending, generating, and even debugging code. Yet, the logic of bugs can be complex and require sophisticated reasoning and a large analysis scope spanning multiple functions. Therefore, at this point, LLMs are better used in an assistive role to complement static analysis. In this paper, we take a deep dive into the open space of LLM-assisted static analysis, using use-before-initialization (UBI) bugs as a case study. To this end, we develop LLift, a fully automated agent that interfaces with both a static analysis tool and an LLM. By carefully designing the agent and the prompts, we are able to overcome a number of challenges, including bug-specific modeling, the large problem scope, the non-deterministic nature of LLMs, etc. Tested in a real-world scenario analyzing nearly a thousand potential UBI bugs produced by static analysis, LLift demonstrates an extremely potent capability, showcasing a high precision (50%) and recall rate (100%). It even identified 13 previously unknown UBI bugs in the Linux kernel. This research paves the way for new opportunities and methodologies in the use of LLMs for bug discovery in extensive, real-world datasets.
This paper lists some common mistakes of Chinese-English technical papers.
Some mistakes made by me:
- How to use a, an, and the?
- Sentences should not begin with numbers (e.g., 1) or "how".
- Very long sentence! (>60 words)
- Using inline symbols (e.g., >)
- Placing the most important things at the beginning!
- Format (taken care by latex)
Paper planning to read
Books
- Handbook of Satisfiability
- Refactoring
- PL Books
Papers
TEE/CC
- SoK: Hardware-supported Trusted Execution Environments
- Private delegated computations using strong isolation
- TDX Security Spec
Middlewares
Software Security
Side-channel
- An Analysis of Speculative Type Confusion Vulnerabilities in the Wild
- A Systematic Evaluation of Transient Execution Attacks and Defenses
- Survey of Transient Execution Attacks and Their Mitigations Wenjie Xiong
Blog Posts
Abstract
We introduce a general way to locate programmer mistakes that are detected by static analyses such as type checking. The program analysis is expressed in a constraint language in which mistakes result in unsatisfiable constraints. Given an unsatisfiable system of constraints, both satisfiable and unsatisfiable constraints are analyzed, to identify the program expressions most likely to be the cause of unsatisfiability. The likelihood of different error explanations is evaluated under the assumption that the programmer's code is mostly correct, so the simplest explanations are chosen, following Bayesian principles. For analyses that rely on programmer-stated assumptions, the diagnosis also identifies assumptions likely to have been omitted. The new error diagnosis approach has been implemented for two very different program analyses: type inference in OCaml and information flow checking in Jif. The effectiveness of the approach is evaluated using previously collected programs containing errors. The results show that when compared to existing compilers and other tools, the general technique identifies the location of programmer errors significantly more accurately.
Overview
This work leverages constraint graph and Bayesian probability for Ocaml and Jif to output more meaningful compilation error report, especially on the accurate site of problematic code. The error report includes type error and/or missing assmuptions.
Methodology
Type Information => Constraints => Constraint Graph => Satisfiability Checking => Inferring likely wrong entities/missing hypotheses
Comments
Since I'm not very familiar with PL, some concepts confused a me for a long while until one professor explained them to me, which includes covariant/contravariant. Fortunately, I've heard other terminologies more or less in the compiler or PL class, so it made easier for me to catch the big map and understand the essence of the paper.
Information Flow Control
- (manually added) label for confidentiality level, partial order on the level, data-flow analysis to find out how the secret data is declassified.
- Data-flow analysis can also be used for inferring types.This will also produce the constraints (by using the rules) and help finding out unsatisfiable paths.
- Implement a serverless distributed ML framework, LambdaML, including distributed optimization, communication (with a storage server) and synchronization
- Compare the FaaS and IaaS solution for distributed ML.
Abstract
Abstract. Recent years have seen increasing success in building large formal proof developments using interactive theorem provers (ITPs). Some proofs have involved many authors, years of effort, and resulted in large, complex interdependent sets of proof “source code” files. Developing these in the first place, and maintaining and extending them afterwards, is a considerable challenge. It has prompted the idea of Proof Engineering as a new sub-field, to find methods and tools to help. It is natural to try to borrow ideas from Software Engineering for this.
In this paper we investigate the idea of defining proof metrics by analogy with software metrics. We seek metrics that may help to monitor and compare formal proof developments, which might be used to guide good practice, locate likely problem areas, or suggest refactorings. Starting from metrics that have been proposed for object-oriented design, we define analogues for formal proofs. We show that our metrics enjoy reasonable properties, and we demonstrate their behaviour with some practical experiments, showing changes over time as proof developments evolve, and making comparisons across between different ITPs
- JS FaaS in SGX enclaves
- Google V8 engine/Duntape + SGX LKL + Apache OpenWhisk
- Key management
- Parallel, warm start, adjust to load
Blog posts
What’s a Trusted Compute Base?
Early Documents
SPECIFICATION OF A TRUSTED COMPUTING BASE (TCB)
- G. H. Nibaldi, 30 November 1979 PDF
A Trusted Computing Base (TCB) is the totality of access control mechanisms for an operating system.
A TCB is a hardware and softwere access control mechunism that establishes v protection environment to control the sharing of information in computer systems. A TCB is an implementation of a reference monitor, as defined in [Anderson 72), that controls when and how data is accessed.
Proof that the TCB will indeed enforce the relevant protection policy can only be provided through a fonrial, methodological approach to TCB design and verification... Because the TCB consists of all the security-related mechanisms, proof of its validity implies the remainder of the system will perform correctly with resWpct to the policy.
Reference Monitor
a TCB is an implementation cf a reference monitor.
- complete mediation of access
- self-protecting
- verifiable
Minimizing the complexity of TCB software is a major factor in raising the confidence level that can be assigned to the protection mechanisms it provides.
...two general design goals to follow after identifying all security relevant operations for inclusion in the TCB are (a) to exclude from the TCB software any operations not strictly security-related so that one can focus attention on those that are, and (b) to make as full use as possible of protection features available in the hardware.
DEPARTMENT OF DEFENSE TRUSTED COMPUTER SYSTEM EVALUATION CRITERIA
- DoD 5200.28 STD, l5 Aug 83 PDF
The heart of a trusted computer system is the Trusted Computing Base (TCB) which contains all of the elements of the system responsible for supporting the security policy and supporting the isolation of objects (code and data) on which the protection is based.
... In the interest of understandable and maintainable protection, a TCB should be as simple as possible consistent with the functions it has to perform. Thus, the TCB includes hardware, firmware, and software critical to protection and must be designed and implemented such that system elements excluded from it need not be trusted to maintain protection.
Trusted Computing Base (TCB) - The totality of protection mechanisms within a computer system – including hardware, firmware, and software – the combination of which is responsible for enforcing a security policy. A TCB consists of one or more components that together enforce a unified security policy over a product or system. The ability of a trusted computing base to correctly enforce a security policy depends solely on the mechanisms within the TCB and on the correct input by system administrative personnel of parameters (e.g., a user's clearance) related to the security policy.
Now the concept of TCB is applicable not only in OS but also embedded systems, and focuses on a security-critical portion of the system, including hardware and software.
Some system (Class A1) still requires a formal design specification and verification of TCB to ensure high degrees of assurance.
Authentication in Distributed Systems: Theory and Practice
Another important concept is the ‘trusted computing base’ or TCB [9], a small amount of software and hardware that security depends on and that we distinguish from a much larger amount that can misbehave without affecting security
Some weaknesses of the TCB model
S&P 1997 Paper
Authentication in Distributed Systems: Theory and Practice,
ACM Transactions on Computer Systems, 1992
It’s not quite true that components outside the TCB can fail without affecting security. Rather, the system should be ‘fail-secure’: if an untrusted component fails, the system may deny access it should have granted, but it won’t grant access it should have denied.
An Efficient TCB for a Generic Content Distribution System
2012 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discover PDF
The trusted computing base (TCB) [1] for a system is a small amount of hardware and/or software that need to be trusted in order to realize the desired assurances. More specifically, the assurances are guaranteed even if all elements outside the TCB misbehave.
The lower the complexity of the elements in the TCB, the lower is the ability to hide malicious/accidental functionality in the TCB components. Consequently, in the design of any security solution it is necessary to lower the complexity of components in the TCB to the extent feasible.
More Recent Study
TCB Minimizing Model of Computation (TMMC)
Bushra, Naila. Mississippi State University ProQuest Dissertations Publishing, 2019. 27664004. Paper
Reducing TCB Complexity for Security-Sensitive Applications: Three Case Studies
EuroSys, 2006 PDF
The security requirements fall into four main categories: confidentiality, integrity, recoverability, and availability. For clarity, we present the definition of these terms.
- Confidentiality: Only authorized users (entities, principals, etc.) can access information (data, programs, etc.).
- Integrity: Either information is current, correct, and complete, or it is possible to detect that these properties do not hold.
- Recoverability: Information that has been damaged can be recovered eventually.
- Availability: Data is available when and where an authorized user needs it.
Justifications of Reducing TCB
Relationships between selected software measures and latent bug-density: Guidelines for improving quality
It seems that nearly all code size/complexity measurements contributes to bug density, except Method Hiding Factor and Polymorphism Factor.
This work just focuses on C++ programs. What about using a different language, e.g., Rust?
Choice of Language also Matters
Rust modernizes a range of other language aspects, which results in improved correctness of code:
Other Related Work
Œuf: Minimizing the Coq Extraction TCB
Reducing TCB complexity for security-sensitive applications: Three case studies
WASM Code Generation Debug Note
Analysis
TVM Build
This Python interface checks the validity of the input and invokes codegen.build_module
codegen.build_module
def build_module(mod, target):
"""Build IRModule into Module.
Parameters
----------
mod : tvm.IRModule
The ir module.
target : str
The target module type.
Returns
-------
module : runtime.Module
The corressponding module.
"""
target = Target(target) if isinstance(target, str) else target
return _ffi_api.Build(mod, target)FFI
ffi is a very mysterious part in TVM. The _ffi_api is:
"""FFI APIs for tvm.target"""
import tvm._ffi
tvm._ffi._init_api("target", __name__)Then:
def _init_api(namespace, target_module_name=None):
"""Initialize api for a given module name
namespace : str
The namespace of the source registry
target_module_name : str
The target module name if different from namespace
"""
target_module_name = target_module_name if target_module_name else namespace
if namespace.startswith("tvm."):
_init_api_prefix(target_module_name, namespace[4:])
else:
_init_api_prefix(target_module_name, namespace)
def _init_api_prefix(module_name, prefix):
module = sys.modules[module_name]
for name in list_global_func_names():
if not name.startswith(prefix):
continue
fname = name[len(prefix) + 1 :]
target_module = module
if fname.find(".") != -1:
continue
f = get_global_func(name)
ff = _get_api(f)
ff.__name__ = fname
ff.__doc__ = "TVM PackedFunc %s. " % fname
setattr(target_module, ff.__name__, ff)It seems the FFI part in TVM will automatically collect all exported FFIs.
So I then looked at the related module.
src/target/codegen.cc
There is a Build method which is also registered:
runtime::Module Build(IRModule mod, Target target) {
if (transform::PassContext::Current()
->GetConfig<Bool>("tir.disable_assert", Bool(false))
.value()) {
mod = tir::transform::SkipAssert()(mod);
}
// the build function.
std::string build_f_name = "target.build." + target->kind->name;
const PackedFunc* bf = runtime::Registry::Get(build_f_name);
ICHECK(bf != nullptr) << build_f_name << " is not enabled";
return (*bf)(mod, target);
}
// Some code here
TVM_REGISTER_GLOBAL("target.Build").set_body_typed(Build);Here this function calls target.build.llvm indirectly in my case.
src/target/llvm/llvm_module.cc
Just like the previous one, the function has been registered:
TVM_REGISTER_GLOBAL("target.build.llvm")
.set_body_typed([](IRModule mod, Target target) -> runtime::Module {
auto n = make_object<LLVMModuleNode>();
n->Init(mod, target);
return runtime::Module(n);
});And this function invokes LLVMModuleNode::Init
At the beginning it does some parameter checks.
The function here invokes CodeGenLLVM::Init, which initializes the code generator for LLVM.
The core functions for generating functions in LLVM are:
void CodeGenLLVM::AddFunction(const PrimFunc& f) { this->AddFunctionInternal(f, false); }
void CodeGenLLVM::InitFuncState() {
var_map_.clear();
alias_var_set_.clear();
alloc_storage_info_.clear();
volatile_buf_.clear();
analyzer_.reset(new arith::Analyzer());
}
void CodeGenLLVM::AddFunctionInternal(const PrimFunc& f, bool ret_void) {
this->InitFuncState();
ICHECK_EQ(f->buffer_map.size(), 0U)
<< "Cannot codegen function with buffer_map, please lower them first";
std::vector<llvm::Type*> param_types;
is_restricted_ = f->HasNonzeroAttr(tir::attr::kNoAlias);
for (Var param : f->params) {
param_types.push_back(GetLLVMType(param));
if (!is_restricted_ && param.dtype().is_handle()) {
alias_var_set_.insert(param.get());
}
}
// TODO(tvm-team):
// Update the function type to respect the ret_type field of f.
// Once we allow more flexibility in the PrimFunc.
llvm::FunctionType* ftype =
llvm::FunctionType::get(ret_void ? t_void_ : t_int_, param_types, false);
auto global_symbol = f->GetAttr<String>(tvm::attr::kGlobalSymbol);
ICHECK(global_symbol.defined())
<< "CodeGenLLVM: Expect PrimFunc to have the global_symbol attribute";
ICHECK(module_->getFunction(static_cast<std::string>(global_symbol.value())) == nullptr)
<< "Function " << global_symbol << " already exist in module";
function_ = llvm::Function::Create(ftype, llvm::Function::ExternalLinkage,
global_symbol.value().operator std::string(), module_.get());
function_->setCallingConv(llvm::CallingConv::C);
function_->setDLLStorageClass(llvm::GlobalValue::DLLStorageClassTypes::DLLExportStorageClass);
// set var map and align information
auto arg_it = function_->arg_begin();
for (size_t i = 0; i < f->params.size(); ++i, ++arg_it) {
llvm::Argument* v = &(*arg_it);
const Var& var = f->params[i];
var_map_[var.get()] = v;
if (is_restricted_) {
if (var.dtype().is_handle() && !alias_var_set_.count(var.get())) {
// set non alias.
#if TVM_LLVM_VERSION >= 50
function_->addParamAttr(i, llvm::Attribute::NoAlias);
#else
function_->setDoesNotAlias(i + 1);
#endif
}
}
}
llvm::BasicBlock* entry = llvm::BasicBlock::Create(*ctx_, "entry", function_);
builder_->SetInsertPoint(entry);
this->VisitStmt(f->body);
// Add alignment attribute if needed.
#if TVM_LLVM_VERSION >= 50
for (size_t i = 0; i < f->params.size(); ++i) {
const Var& var = f->params[i];
auto f = alloc_storage_info_.find(var.get());
if (f != alloc_storage_info_.end()) {
unsigned align = f->second.alignment;
if (align > 1) {
auto attr = llvm::Attribute::get(*ctx_, llvm::Attribute::Alignment, align);
function_->addParamAttr(i, attr);
}
}
}
#endif
llvm::StringRef fs = target_machine_->getTargetFeatureString();
if (!fs.empty()) {
function_->addFnAttr("target-features", fs);
}
if (ret_void) {
builder_->CreateRetVoid();
} else {
builder_->CreateRet(ConstInt32(0));
}
}However, there is no function that have the same signature as BackendPackedCFunc.
Tir Level Transformation
After searching for a while, I finally found a place for BackendPackedCFunc generation. It invoked in the Python script: mod_host, mdev = _build_for_device(input_mod, tar, target_host):
def _build_for_device(input_mod, target, target_host):
"""Build the lowered functions for a device with the given compilation
target.
Parameters
----------
input_mod : IRModule
The schedule to be built.
target : str or :any:`tvm.target.Target`
The target and option of the compilation.
target_host : str or :any:`tvm.target.Target`
The host compilation target.
Returns
-------
fhost : IRModule
The host IRModule.
mdev : tvm.module
A module that contains device code.
"""
target, target_host = Target.check_and_update_host_consist(target, target_host)
device_type = ndarray.device(target.kind.name, 0).device_type
mod_mixed = input_mod
mod_mixed = tvm.tir.transform.Apply(lambda f: f.with_attr("target", target))(mod_mixed)
opt_mixed = [tvm.tir.transform.VerifyMemory()]
if len(mod_mixed.functions) == 1:
opt_mixed += [tvm.tir.transform.Apply(lambda f: f.with_attr("tir.is_entry_func", True))]
if PassContext.current().config.get("tir.detect_global_barrier", False):
opt_mixed += [tvm.tir.transform.ThreadSync("global")]
opt_mixed += [
tvm.tir.transform.ThreadSync("shared"),
tvm.tir.transform.ThreadSync("warp"),
tvm.tir.transform.InferFragment(),
tvm.tir.transform.LowerThreadAllreduce(),
tvm.tir.transform.MakePackedAPI(),
tvm.tir.transform.SplitHostDevice(),
]
mod_mixed = tvm.transform.Sequential(opt_mixed)(mod_mixed)
# device optimizations
opt_device = tvm.transform.Sequential(
[
tvm.tir.transform.Filter(
lambda f: "calling_conv" in f.attrs
and f.attrs["calling_conv"].value == CallingConv.DEVICE_KERNEL_LAUNCH
),
tvm.tir.transform.LowerWarpMemory(),
tvm.tir.transform.Simplify(),
tvm.tir.transform.LowerDeviceStorageAccessInfo(),
tvm.tir.transform.LowerCustomDatatypes(),
tvm.tir.transform.LowerIntrin(),
]
)
mod_dev = opt_device(mod_mixed)
# host optimizations
opt_host = tvm.transform.Sequential(
[
tvm.tir.transform.Filter(
lambda f: "calling_conv" not in f.attrs
or f.attrs["calling_conv"].value != CallingConv.DEVICE_KERNEL_LAUNCH
),
tvm.tir.transform.Apply(lambda f: f.with_attr("target", target_host)),
tvm.tir.transform.LowerTVMBuiltin(),
tvm.tir.transform.LowerDeviceStorageAccessInfo(),
tvm.tir.transform.LowerCustomDatatypes(),
tvm.tir.transform.LowerIntrin(),
tvm.tir.transform.CombineContextCall(),
]
)
mod_host = opt_host(mod_mixed)
if device_type == ndarray.cpu(0).device_type and target_host == target:
assert len(mod_dev.functions) == 0
if "gpu" in target.keys and len(mod_dev.functions) == 0:
warnings.warn(
"Specified target %s, but cannot find device code, did you do " "bind?" % target
)
rt_mod_dev = codegen.build_module(mod_dev, target) if len(mod_dev.functions) != 0 else None
return mod_host, rt_mod_devHere the function MakePackedAPI generates the function with BackendPackedCFunc signature.
PrimFunc MakePackedAPI(PrimFunc&& func, int num_unpacked_args) {
auto global_symbol = func->GetAttr<String>(tvm::attr::kGlobalSymbol);
ICHECK(global_symbol) << "MakePackedAPI: Expect PrimFunc to have the global_symbol attribute";
auto target = func->GetAttr<Target>(tvm::attr::kTarget);
ICHECK(target.defined()) << "MakePackedAPI: Require the target attribute";
int target_device_type = target.value()->kind->device_type;
std::string name_hint = global_symbol.value();
auto* func_ptr = func.CopyOnWrite();
const Stmt nop = Evaluate(0);
int num_args = static_cast<int>(func_ptr->params.size());
ICHECK_LE(num_unpacked_args, num_args);
bool pack_args = (num_unpacked_args == -1) || (num_args > num_unpacked_args);
if (num_unpacked_args == -1) {
// reset to zero
num_unpacked_args = 0;
}
ICHECK_GE(num_unpacked_args, 0);
int num_packed_args = num_args - num_unpacked_args;
// Data field definitions
// The packed fields
Var v_packed_args("args", DataType::Handle());
Var v_packed_arg_type_ids("arg_type_ids", DataType::Handle());
Var v_num_packed_args("num_args", DataType::Int(32));
Var v_out_ret_value("out_ret_value", DataType::Handle());
Var v_out_ret_tcode("out_ret_tcode", DataType::Handle());
Var v_resource_handle("resource_handle", DataType::Handle());
// The arguments of the function.
Array<Var> args;
// The device context
Var device_id("dev_id");
Integer device_type(target_device_type);
// seq_init gives sequence of initialization
// seq_check gives sequence of later checks after init
std::vector<Stmt> seq_init, seq_check;
std::unordered_map<const VarNode*, PrimExpr> vmap;
ArgBinder binder(&vmap);
// ---------------------------
// local function definitions
// load i-th argument as type t
auto f_arg_value = [&](DataType t, int i) {
Array<PrimExpr> call_args{v_packed_args, IntImm(DataType::Int(32), i),
IntImm(DataType::Int(32), builtin::kTVMValueContent)};
// load 64 bit version
DataType api_type = APIType(t);
PrimExpr res = Call(api_type, builtin::tvm_struct_get(), call_args);
// cast to the target version.
if (api_type != t) {
res = Cast(t, res);
}
return res;
};
// ---------------------------
// start of logics
// add signiture for packed arguments.
if (pack_args) {
args.push_back(v_packed_args);
args.push_back(v_packed_arg_type_ids);
args.push_back(v_num_packed_args);
std::ostringstream os;
os << name_hint << ": num_args should be " << num_packed_args;
seq_init.emplace_back(MakeAssertEQ(v_num_packed_args, num_packed_args, os.str()));
}
// Need to re-declare vars, in case some arguments also appears in the buffer.
std::vector<std::pair<Var, Var> > var_def;
std::vector<std::pair<Var, Buffer> > buffer_def;
for (int i = 0; i < static_cast<int>(func_ptr->params.size()); ++i) {
Var param = func_ptr->params[i];
Var v_arg = Var("arg" + std::to_string(i), param->dtype);
auto it = func_ptr->buffer_map.find(param);
if (it != func_ptr->buffer_map.end()) {
buffer_def.emplace_back(v_arg, (*it).second);
} else {
var_def.emplace_back(v_arg, param);
}
if (i < num_packed_args) {
// Value loads
seq_init.emplace_back(LetStmt(v_arg, f_arg_value(v_arg.dtype(), i), nop));
// type code checks
Var tcode(v_arg->name_hint + ".code", DataType::Int(32));
seq_init.emplace_back(LetStmt(tcode,
Load(DataType::Int(32), v_packed_arg_type_ids,
IntImm(DataType::Int(32), i), const_true(1)),
nop));
DataType t = v_arg.dtype();
if (t.is_handle()) {
std::ostringstream msg;
msg << name_hint << ": Expect arg[" << i << "] to be pointer";
seq_check.emplace_back(AssertStmt(tcode == kTVMOpaqueHandle || tcode == kTVMNDArrayHandle ||
tcode == kTVMDLTensorHandle || tcode == kTVMNullptr,
tvm::tir::StringImm(msg.str()), nop));
} else if (t.is_int() || t.is_uint()) {
std::ostringstream msg;
msg << name_hint << ": Expect arg[" << i << "] to be int";
seq_check.emplace_back(AssertStmt(tcode == kDLInt, tvm::tir::StringImm(msg.str()), nop));
} else {
ICHECK(t.is_float());
std::ostringstream msg;
msg << name_hint << ": Expect arg[" << i << "] to be float";
seq_check.emplace_back(AssertStmt(tcode == kDLFloat, tvm::tir::StringImm(msg.str()), nop));
}
} else {
args.push_back(v_arg);
}
}
// allow return value if the function is packed.
if (pack_args) {
args.push_back(v_out_ret_value);
args.push_back(v_out_ret_tcode);
args.push_back(v_resource_handle);
}
size_t expected_nargs = num_unpacked_args + (pack_args ? 6 : 0);
ICHECK_EQ(args.size(), expected_nargs);
// Arg definitions are defined before buffer binding to avoid the use before
// def errors.
//
// For example, for auto broadcasting, checks are required to guarantee that
// either 0 or the original stride will be correctly used. Checks here have
// to use the args that may have no let binding yet. Therefore, hoisting let
// binding for args before buffer declaration is needed.
for (const auto& kv : var_def) {
binder.Bind(kv.second, kv.first, kv.first->name_hint, true);
}
for (const auto& kv : buffer_def) {
binder.BindDLTensor(kv.second, device_type, device_id, kv.first, kv.first->name_hint);
}
if (num_unpacked_args == 0) {
func = WithAttr(std::move(func), tvm::attr::kCallingConv, Integer(CallingConv::kCPackedFunc));
}
Stmt body = RewriteReturn(func_ptr->body, v_out_ret_value, v_out_ret_tcode);
body = AttrStmt(make_zero(DataType::Int(32)), attr::compute_scope,
StringImm(name_hint + "_compute_"), body);
// Set device context
if (vmap.count(device_id.get())) {
PrimExpr node = StringImm("default");
seq_check.push_back(AttrStmt(node, attr::device_id, device_id, nop));
seq_check.push_back(AttrStmt(node, attr::device_type, device_type, nop));
if (runtime::DeviceAPI::NeedSetDevice(target_device_type)) {
Stmt set_device =
Evaluate(Call(DataType::Int(32), builtin::tvm_call_packed(),
{StringImm(runtime::symbol::tvm_set_device), device_type, device_id}));
body = SeqStmt({set_device, body});
}
}
func_ptr->body = MergeNest({seq_init, binder.init_nest(), seq_check, binder.asserts()}, body);
func_ptr->params = args;
Array<Var> undefined = UndefinedVars(func_ptr->body, func_ptr->params);
if (undefined.size() != 0) {
std::ostringstream os;
for (Var v : undefined) {
os << " \'" << v->name_hint << "\' ";
}
os << " is not bound to any variables";
LOG(FATAL) << "Not all Vars are passed in api_args: " << os.str();
}
func_ptr->buffer_map = Map<Var, Buffer>();
func_ptr->checked_type_ = func_ptr->func_type_annotation();
func_ptr->ret_type = PrimType(DataType::Int(32));
// return the function.
return std::move(func);
}Abstract
This paper reports our experience applying lightweight formal methods to validate the correctness of ShardStore, a new key-value storage node implementation for the Amazon S3 cloud object storage service. By “lightweight formal methods" we mean a pragmatic approach to verifying the correctness of a production storage node that is under ongoing feature development by a full-time engineering team. We do not aim to achieve full formal verification, but instead emphasize automation, usability, and the ability to continually ensure correctness as both software and its specification evolve over time. Our approach decomposes correctness into independent properties, each checked by the most appropriate tool, and develops executable reference models as specifications to be checked against the implementation. Our work has prevented 16 issues from reaching production, including subtle crash consistency and concurrency problems, and has been extended by non-formal-methods experts to check new features and properties as ShardStore has evolved.
Summary
This paper explains the experience of verifying ShardStore, a KV DB implemented in Rust on Amazon S3. They first introduces what's ShardStore, and then describe their goals and the anatomy of their tasks. There are 3 major parts for validation:
- Correctness
- Crash Consistency
- Concurrent Execution
Correctness refers to the functionalities should not deviate from the specification. So they build a reference model alone with source code in Rust and launch conformance checking on the model. When testing, they can further use the mock model in memory and avoid using low-speed disks for performance.
For crash consistency, they want to verify persistence(operations should be consistent if they are persisted before a crash) and forward progress(grace shutdown implies the operations are persisted). They use a dependency graph to depict the interdependencies of operations and such Dependency type can also be passed by the operations. By adding DirtyReboot to the aforementioned model, they can check this property.
Finally for potential race conditions. they developed their own tool called Shuttle, since current tools cannot scale up. Their tool recruits random algorithm for model checking.
However, there are still some properties relying on unsafe Rust and cannot be covered by the tools. So they use the Rust interpreter validate these parts. And for some security-critical components, they also utilize a formal verifier.
It turns out that they found several problems, and more potential problems are eliminated before code review.
Comments
This paper is really well-written. However, I don't think there is something pretty novel in the traditional way and I'm surprised this is the best paper in the System top conference. It's more like to share readers their methodology and experiences of tuning a huge system. However, I do believe the way they present solved a real-world problem in a lightweight manner, which is really valuable.
Besides, I think the concept, Continuous Validation, is interesting. Although their method is not formal enough, they can build a system which allow the engineers without formal verification background to amend the specification(expected) model when contributing code for new functionalities, and therefore permits verifiability in the future.
Related Artifacts
Abstract
Numerous recent works have experimentally shown that Intel Software Guard Extensions (SGX) are vulnerable to cache timing and page table side-channel attacks which could be used to circumvent the data confidentiality guarantees provided by SGX. Existing mechanisms that protect against these attacks either incur high execution costs, are ineffective against certain attack variants, or require significant code modifications.
We present Varys, a system that protects unmodified programs running in SGX enclaves from cache timing and page table side-channel attacks. Varys takes a pragmatic approach of strict reservation of physical cores to security-sensitive threads, thereby preventing the attacker from accessing shared CPU resources during enclave execution. The key challenge that we are addressing is that of maintaining the core reservation in the presence of an untrusted OS.
Varys fully protects against all L1/L2 cache timing attacks and significantly raises the bar for page table side-channel attacks - all with only 15% overhead on average for Phoenix and PARSEC benchmarks. Additionally, we propose a set of minor hardware extensions that hold the potential to extend Varys' security guarantees to L3 cache and further improve its performance.
Method
The basic idea is very simple: making the SGX threads on the same core and avoid preemption by OS or an attacking thread. At the same time, guaranteeing the AEX freq. is below a specific bound.
Implementation
- LLVM pass -> instrumentation
- Covert channel to detect threads are on the same core
static bool
init_runtime(bool alloc_with_pool, uint32_t max_thread_num)
{
uint64_t ecall_args[2];
ecall_args[0] = alloc_with_pool;
ecall_args[1] = max_thread_num;
if (SGX_SUCCESS != ecall_handle_command(g_eid, CMD_INIT_RUNTIME,
(uint8_t *)ecall_args,
sizeof(uint64_t) * 2)) {
printf("Call ecall_handle_command() failed.\n");
return false;
}
if (!(bool)ecall_args[0]) {
printf("Init runtime environment failed.\n");
return false;
}
return true;
}handle_cmd_init_runtime
This function is invoked at very beginning to initiate the WASM runtime.
Create a heap buffer and pass the init_args to wasm_runtime_full_init
static void
handle_cmd_init_runtime(uint64 *args, uint32 argc)
{
bool alloc_with_pool;
uint32 max_thread_num;
RuntimeInitArgs init_args;
bh_assert(argc == 2);
os_set_print_function(enclave_print);
#if WASM_ENABLE_SPEC_TEST == 0
alloc_with_pool = (bool)args[0];
#else
alloc_with_pool = true;
#endif
max_thread_num = (uint32)args[1];
memset(&init_args, 0, sizeof(RuntimeInitArgs));
init_args.max_thread_num = max_thread_num;
if (alloc_with_pool) {
init_args.mem_alloc_type = Alloc_With_Pool;
init_args.mem_alloc_option.pool.heap_buf = global_heap_buf;
init_args.mem_alloc_option.pool.heap_size = sizeof(global_heap_buf);
}
else {
init_args.mem_alloc_type = Alloc_With_System_Allocator;
}
/* initialize runtime environment */
if (!wasm_runtime_full_init(&init_args)) {
LOG_ERROR("Init runtime environment failed.\n");
args[0] = false;
return;
}
args[0] = true;
LOG_VERBOSE("Init runtime environment success.\n");
}wasm_runtime_full_init
bool
wasm_runtime_full_init(RuntimeInitArgs *init_args)
{
if (!wasm_runtime_memory_init(init_args->mem_alloc_type,
&init_args->mem_alloc_option))
return false;
if (!wasm_runtime_env_init()) {
wasm_runtime_memory_destroy();
return false;
}
if (init_args->n_native_symbols > 0
&& !wasm_runtime_register_natives(init_args->native_module_name,
init_args->native_symbols,
init_args->n_native_symbols)) {
wasm_runtime_destroy();
return false;
}
#if WASM_ENABLE_THREAD_MGR != 0
wasm_cluster_set_max_thread_num(init_args->max_thread_num);
#endif
return true;
}Initialization will be achieved by several calls.
wasm_runtime_memory_init
os_mutex_initin enclave???What's(heap mempry unit)hmu_tree?- How is heap memory managed?
wasm_runtime_memory_init(mem_alloc_type_t mem_alloc_type,
const MemAllocOption *alloc_option)
{
if (mem_alloc_type == Alloc_With_Pool)
return wasm_memory_init_with_pool(alloc_option->pool.heap_buf,
alloc_option->pool.heap_size);
else if (mem_alloc_type == Alloc_With_Allocator)
return wasm_memory_init_with_allocator(alloc_option->allocator.malloc_func,
alloc_option->allocator.realloc_func,
alloc_option->allocator.free_func);
else if (mem_alloc_type == Alloc_With_System_Allocator)
return wasm_memory_init_with_allocator(os_malloc, os_realloc, os_free);
else
return false;
}wasm_runtime_env_init
static bool
wasm_runtime_env_init()
{
if (bh_platform_init() != 0)
return false;
if (wasm_native_init() == false) {
goto fail1;
}
#if WASM_ENABLE_MULTI_MODULE
if (BHT_OK != os_mutex_init(®istered_module_list_lock)) {
goto fail2;
}
if (BHT_OK != os_mutex_init(&loading_module_list_lock)) {
goto fail3;
}
#endif
#if WASM_ENABLE_SHARED_MEMORY
if (!wasm_shared_memory_init()) {
goto fail4;
}
#endif
#if (WASM_ENABLE_WAMR_COMPILER == 0) && (WASM_ENABLE_THREAD_MGR != 0)
if (!thread_manager_init()) {
goto fail5;
}
#endif
#if WASM_ENABLE_AOT != 0
#ifdef OS_ENABLE_HW_BOUND_CHECK
if (!aot_signal_init()) {
goto fail6;
}
#endif
#endif
#if WASM_ENABLE_REF_TYPES != 0
if (!wasm_externref_map_init()) {
goto fail7;
}
#endif
return true;
#if WASM_ENABLE_REF_TYPES != 0
fail7:
#endif
#if WASM_ENABLE_AOT != 0
#ifdef OS_ENABLE_HW_BOUND_CHECK
aot_signal_destroy();
fail6:
#endif
#endif
#if (WASM_ENABLE_WAMR_COMPILER == 0) && (WASM_ENABLE_THREAD_MGR != 0)
thread_manager_destroy();
fail5:
#endif
#if WASM_ENABLE_SHARED_MEMORY
wasm_shared_memory_destroy();
fail4:
#endif
#if WASM_ENABLE_MULTI_MODULE
os_mutex_destroy(&loading_module_list_lock);
fail3:
os_mutex_destroy(®istered_module_list_lock);
fail2:
#endif
wasm_native_destroy();
fail1:
bh_platform_destroy();
return false;
}bh_platform_init: Initialize the platform internal resources if needed (empty for SGX)wasm_native_init: Import symbols from precompiled libraries (determined when compiling WASM)register_natives: add a newNativeSymbolsNode(allocated during runtime) to store the imported functions- When other fields of
init_argsare set?
static bool
load_from_sections(WASMModule *module, WASMSection *sections,
char *error_buf, uint32 error_buf_size)
{
WASMExport *export;
WASMSection *section = sections;
const uint8 *buf, *buf_end, *buf_code = NULL, *buf_code_end = NULL,
*buf_func = NULL, *buf_func_end = NULL;
WASMGlobal *aux_data_end_global = NULL, *aux_heap_base_global = NULL;
WASMGlobal *aux_stack_top_global = NULL, *global;
uint32 aux_data_end = (uint32)-1, aux_heap_base = (uint32)-1;
uint32 aux_stack_top = (uint32)-1, global_index, func_index, i;
uint32 aux_data_end_global_index = (uint32)-1;
uint32 aux_heap_base_global_index = (uint32)-1;
WASMType *func_type;
/* Find code and function sections if have */
while (section) {
if (section->section_type == SECTION_TYPE_CODE) {
buf_code = section->section_body;
buf_code_end = buf_code + section->section_body_size;
}
else if (section->section_type == SECTION_TYPE_FUNC) {
buf_func = section->section_body;
buf_func_end = buf_func + section->section_body_size;
}
section = section->next;
}
section = sections;
while (section) {
buf = section->section_body;
buf_end = buf + section->section_body_size;
LOG_DEBUG("load section, type: %d", section->section_type);
switch (section->section_type) {
case SECTION_TYPE_USER:
/* unsupported user section, ignore it. */
if (!load_user_section(buf, buf_end, module, error_buf, error_buf_size))
return false;
break;
case SECTION_TYPE_TYPE:
if (!load_type_section(buf, buf_end, module, error_buf, error_buf_size))
return false;
break;
case SECTION_TYPE_IMPORT:
if (!load_import_section(buf, buf_end, module, error_buf, error_buf_size))
return false;
break;
case SECTION_TYPE_FUNC:
if (!load_function_section(buf, buf_end, buf_code, buf_code_end,
module, error_buf, error_buf_size))
return false;
break;
case SECTION_TYPE_TABLE:
if (!load_table_section(buf, buf_end, module, error_buf, error_buf_size))
return false;
break;
case SECTION_TYPE_MEMORY:
if (!load_memory_section(buf, buf_end, module, error_buf, error_buf_size))
return false;
break;
case SECTION_TYPE_GLOBAL:
if (!load_global_section(buf, buf_end, module, error_buf, error_buf_size))
return false;
break;
case SECTION_TYPE_EXPORT:
if (!load_export_section(buf, buf_end, module, error_buf, error_buf_size))
return false;
break;
case SECTION_TYPE_START:
if (!load_start_section(buf, buf_end, module, error_buf, error_buf_size))
return false;
break;
case SECTION_TYPE_ELEM:
if (!load_table_segment_section(buf, buf_end, module, error_buf, error_buf_size))
return false;
break;
case SECTION_TYPE_CODE:
if (!load_code_section(buf, buf_end, buf_func, buf_func_end,
module, error_buf, error_buf_size))
return false;
break;
case SECTION_TYPE_DATA:
if (!load_data_segment_section(buf, buf_end, module, error_buf, error_buf_size))
return false;
break;
#if WASM_ENABLE_BULK_MEMORY != 0
case SECTION_TYPE_DATACOUNT:
if (!load_datacount_section(buf, buf_end, module, error_buf, error_buf_size))
return false;
break;
#endif
default:
set_error_buf(error_buf, error_buf_size,
"invalid section id");
return false;
}
section = section->next;
}
module->aux_data_end_global_index = (uint32)-1;
module->aux_heap_base_global_index = (uint32)-1;
module->aux_stack_top_global_index = (uint32)-1;
/* Resolve auxiliary data/stack/heap info and reset memory info */
export = module->exports;
for (i = 0; i < module->export_count; i++, export++) {
if (export->kind == EXPORT_KIND_GLOBAL) {
if (!strcmp(export->name, "__heap_base")) {
global_index = export->index - module->import_global_count;
global = module->globals + global_index;
if (global->type == VALUE_TYPE_I32
&& !global->is_mutable
&& global->init_expr.init_expr_type ==
INIT_EXPR_TYPE_I32_CONST) {
aux_heap_base_global = global;
aux_heap_base = global->init_expr.u.i32;
aux_heap_base_global_index = export->index;
LOG_VERBOSE("Found aux __heap_base global, value: %d",
aux_heap_base);
}
}
else if (!strcmp(export->name, "__data_end")) {
global_index = export->index - module->import_global_count;
global = module->globals + global_index;
if (global->type == VALUE_TYPE_I32
&& !global->is_mutable
&& global->init_expr.init_expr_type ==
INIT_EXPR_TYPE_I32_CONST) {
aux_data_end_global = global;
aux_data_end = global->init_expr.u.i32;
aux_data_end_global_index = export->index;
LOG_VERBOSE("Found aux __data_end global, value: %d",
aux_data_end);
aux_data_end = align_uint(aux_data_end, 16);
}
}
/* For module compiled with -pthread option, the global is:
[0] stack_top <-- 0
[1] tls_pointer
[2] tls_size
[3] data_end <-- 3
[4] global_base
[5] heap_base <-- 5
[6] dso_handle
For module compiled without -pthread option:
[0] stack_top <-- 0
[1] data_end <-- 1
[2] global_base
[3] heap_base <-- 3
[4] dso_handle
*/
if (aux_data_end_global && aux_heap_base_global
&& aux_data_end <= aux_heap_base) {
module->aux_data_end_global_index = aux_data_end_global_index;
module->aux_data_end = aux_data_end;
module->aux_heap_base_global_index = aux_heap_base_global_index;
module->aux_heap_base = aux_heap_base;
/* Resolve aux stack top global */
for (global_index = 0; global_index < module->global_count;
global_index++) {
global = module->globals + global_index;
if (global->is_mutable /* heap_base and data_end is
not mutable */
&& global->type == VALUE_TYPE_I32
&& global->init_expr.init_expr_type ==
INIT_EXPR_TYPE_I32_CONST
&& (uint32)global->init_expr.u.i32 <= aux_heap_base) {
aux_stack_top_global = global;
aux_stack_top = (uint32)global->init_expr.u.i32;
module->aux_stack_top_global_index =
module->import_global_count + global_index;
module->aux_stack_bottom = aux_stack_top;
module->aux_stack_size = aux_stack_top > aux_data_end
? aux_stack_top - aux_data_end
: aux_stack_top;
LOG_VERBOSE("Found aux stack top global, value: %d, "
"global index: %d, stack size: %d",
aux_stack_top, global_index,
module->aux_stack_size);
break;
}
}
break;
}
}
}
module->malloc_function = (uint32)-1;
module->free_function = (uint32)-1;
/* Resolve malloc/free function exported by wasm module */
export = module->exports;
for (i = 0; i < module->export_count; i++, export++) {
if (export->kind == EXPORT_KIND_FUNC) {
if (!strcmp(export->name, "malloc")
&& export->index >= module->import_function_count) {
func_index = export->index - module->import_function_count;
func_type = module->functions[func_index]->func_type;
if (func_type->param_count == 1
&& func_type->result_count == 1
&& func_type->types[0] == VALUE_TYPE_I32
&& func_type->types[1] == VALUE_TYPE_I32) {
bh_assert(module->malloc_function == (uint32)-1);
module->malloc_function = export->index;
LOG_VERBOSE("Found malloc function, name: %s, index: %u",
export->name, export->index);
}
}
else if (!strcmp(export->name, "__new")
&& export->index >= module->import_function_count) {
/* __new && __pin for AssemblyScript */
func_index = export->index - module->import_function_count;
func_type = module->functions[func_index]->func_type;
if (func_type->param_count == 2
&& func_type->result_count == 1
&& func_type->types[0] == VALUE_TYPE_I32
&& func_type->types[1] == VALUE_TYPE_I32
&& func_type->types[2] == VALUE_TYPE_I32) {
uint32 j;
WASMExport *export_tmp;
bh_assert(module->malloc_function == (uint32)-1);
module->malloc_function = export->index;
LOG_VERBOSE("Found malloc function, name: %s, index: %u",
export->name, export->index);
/* resolve retain function.
If not find, reset malloc function index */
export_tmp = module->exports;
for (j = 0; j < module->export_count; j++, export_tmp++) {
if ((export_tmp->kind == EXPORT_KIND_FUNC)
&& (!strcmp(export_tmp->name, "__retain")
|| !strcmp(export_tmp->name, "__pin"))
&& (export_tmp->index
>= module->import_function_count)) {
func_index = export_tmp->index
- module->import_function_count;
func_type =
module->functions[func_index]->func_type;
if (func_type->param_count == 1
&& func_type->result_count == 1
&& func_type->types[0] == VALUE_TYPE_I32
&& func_type->types[1] == VALUE_TYPE_I32) {
bh_assert(
module->retain_function == (uint32)-1);
module->retain_function = export_tmp->index;
LOG_VERBOSE(
"Found retain function, name: %s, index: %u",
export_tmp->name, export_tmp->index);
break;
}
}
}
if (j == module->export_count) {
module->malloc_function = (uint32)-1;
LOG_VERBOSE("Can't find retain function,"
"reset malloc function index to -1");
}
}
}
else if (((!strcmp(export->name, "free"))
|| (!strcmp(export->name, "__release"))
|| (!strcmp(export->name, "__unpin")))
&& export->index >= module->import_function_count) {
func_index = export->index - module->import_function_count;
func_type = module->functions[func_index]->func_type;
if (func_type->param_count == 1
&& func_type->result_count == 0
&& func_type->types[0] == VALUE_TYPE_I32) {
bh_assert(module->free_function == (uint32)-1);
module->free_function = export->index;
LOG_VERBOSE("Found free function, name: %s, index: %u",
export->name, export->index);
}
}
}
}
#if WASM_ENABLE_FAST_INTERP != 0 && WASM_ENABLE_LABELS_AS_VALUES != 0
handle_table = wasm_interp_get_handle_table();
#endif
for (i = 0; i < module->function_count; i++) {
WASMFunction *func = module->functions[i];
if (!wasm_loader_prepare_bytecode(module, func, i,
error_buf, error_buf_size)) {
return false;
}
}
if (!module->possible_memory_grow) {
WASMMemoryImport *memory_import;
WASMMemory *memory;
if (aux_data_end_global
&& aux_heap_base_global
&& aux_stack_top_global) {
uint64 init_memory_size;
uint32 shrunk_memory_size = align_uint(aux_heap_base, 8);
if (module->import_memory_count) {
memory_import = &module->import_memories[0].u.memory;
init_memory_size = (uint64)memory_import->num_bytes_per_page *
memory_import->init_page_count;
if (shrunk_memory_size <= init_memory_size) {
/* Reset memory info to decrease memory usage */
memory_import->num_bytes_per_page = shrunk_memory_size;
memory_import->init_page_count = 1;
LOG_VERBOSE("Shrink import memory size to %d",
shrunk_memory_size);
}
}
if (module->memory_count) {
memory = &module->memories[0];
init_memory_size = (uint64)memory->num_bytes_per_page *
memory->init_page_count;
if (shrunk_memory_size <= init_memory_size) {
/* Reset memory info to decrease memory usage */
memory->num_bytes_per_page = shrunk_memory_size;
memory->init_page_count = 1;
LOG_VERBOSE("Shrink memory size to %d", shrunk_memory_size);
}
}
}
#if WASM_ENABLE_MULTI_MODULE == 0
if (module->import_memory_count) {
memory_import = &module->import_memories[0].u.memory;
/* Memory init page count cannot be larger than 65536, we don't
check integer overflow again. */
memory_import->num_bytes_per_page *= memory_import->init_page_count;
memory_import->init_page_count = memory_import->max_page_count = 1;
}
if (module->memory_count) {
/* Memory init page count cannot be larger than 65536, we don't
check integer overflow again. */
memory = &module->memories[0];
memory->num_bytes_per_page *= memory->init_page_count;
memory->init_page_count = memory->max_page_count = 1;
}
#endif
}
#if WASM_ENABLE_MEMORY_TRACING != 0
wasm_runtime_dump_module_mem_consumption(module);
#endif
return true;
}wasm_loader_prepare_bytecode
This is a very complex function. It will go through the bytecode of the whole function and generate relarted operations?
Location: wasm-micro-runtime/core/iwasm/interpreter/wasm_mini_loader.c
Path: wasm-micro-runtime/core/iwasm/common/wasm_runtime_common.c
- Find out the function
main(__main_argc_argv/_main) and make sure it's not imported - Get the type of the main function and check its validity
- Prepare parameters (
argcandargv) and do the address translation (native to app) - Execute: call
wasm_runtime_create_exec_env_and_call_wasm wasm_runtime_module_free
bool
wasm_application_execute_main(WASMModuleInstanceCommon *module_inst,
int32 argc, char *argv[])
{
WASMFunctionInstanceCommon *func;
WASMType *func_type = NULL;
uint32 argc1 = 0, argv1[2] = { 0 };
uint32 total_argv_size = 0;
uint64 total_size;
uint32 argv_buf_offset = 0;
int32 i;
char *argv_buf, *p, *p_end;
uint32 *argv_offsets, module_type;
bool ret, is_import_func = true;
#if WASM_ENABLE_LIBC_WASI != 0
if (wasm_runtime_is_wasi_mode(module_inst)) {
/* In wasi mode, we should call function named "_start"
which initializes the wasi envrionment and then calls
the actual main function. Directly call main function
may cause exception thrown. */
if ((func = wasm_runtime_lookup_wasi_start_function(module_inst)))
return wasm_runtime_create_exec_env_and_call_wasm(
module_inst, func, 0, NULL);
/* if no start function is found, we execute
the main function as normal */
}
#endif /* end of WASM_ENABLE_LIBC_WASI */
if (!(func = resolve_function(module_inst, "main"))
&& !(func = resolve_function(module_inst, "__main_argc_argv"))
&& !(func = resolve_function(module_inst, "_main"))) {
wasm_runtime_set_exception(module_inst,
"lookup main function failed");
return false;
}
#if WASM_ENABLE_INTERP != 0
if (module_inst->module_type == Wasm_Module_Bytecode) {
is_import_func = ((WASMFunctionInstance*)func)->is_import_func;
}
#endif
#if WASM_ENABLE_AOT != 0
if (module_inst->module_type == Wasm_Module_AoT) {
is_import_func = ((AOTFunctionInstance*)func)->is_import_func;
}
#endif
if (is_import_func) {
wasm_runtime_set_exception(module_inst,
"lookup main function failed");
return false;
}
module_type = module_inst->module_type;
func_type = wasm_runtime_get_function_type(func, module_type);
if (!func_type) {
LOG_ERROR("invalid module instance type");
return false;
}
if (!check_main_func_type(func_type)) {
wasm_runtime_set_exception(module_inst,
"invalid function type of main function");
return false;
}
if (func_type->param_count) {
for (i = 0; i < argc; i++)
total_argv_size += (uint32)(strlen(argv[i]) + 1);
total_argv_size = align_uint(total_argv_size, 4);
total_size = (uint64)total_argv_size + sizeof(int32) * (uint64)argc;
if (total_size >= UINT32_MAX
|| !(argv_buf_offset =
wasm_runtime_module_malloc(module_inst, (uint32)total_size,
(void**)&argv_buf))) {
wasm_runtime_set_exception(module_inst,
"allocate memory failed");
return false;
}
p = argv_buf;
argv_offsets = (uint32*)(p + total_argv_size);
p_end = p + total_size;
for (i = 0; i < argc; i++) {
bh_memcpy_s(p, (uint32)(p_end - p), argv[i], (uint32)(strlen(argv[i]) + 1));
argv_offsets[i] = argv_buf_offset + (uint32)(p - argv_buf);
p += strlen(argv[i]) + 1;
}
argc1 = 2;
argv1[0] = (uint32)argc;
argv1[1] = (uint32)wasm_runtime_addr_native_to_app(module_inst, argv_offsets);
}
ret = wasm_runtime_create_exec_env_and_call_wasm(module_inst, func,
argc1, argv1);
if (argv_buf_offset)
wasm_runtime_module_free(module_inst, argv_buf_offset);
return ret;
}wasm_runtime_get_function_type
WASMType *
wasm_runtime_get_function_type(const WASMFunctionInstanceCommon *function,
uint32 module_type)
{
WASMType *type = NULL;
#if WASM_ENABLE_INTERP != 0
if (module_type == Wasm_Module_Bytecode) {
WASMFunctionInstance *wasm_func = (WASMFunctionInstance *)function;
type = wasm_func->is_import_func
? wasm_func->u.func_import->func_type
: wasm_func->u.func->func_type;
}
#endif
#if WASM_ENABLE_AOT != 0
if (module_type == Wasm_Module_AoT) {
AOTFunctionInstance *aot_func = (AOTFunctionInstance *)function;
type = aot_func->is_import_func
? aot_func->u.func_import->func_type
: aot_func->u.func.func_type;
}
#endif
return type;
}check_main_func_type
- Two or no parameters
- At least one result(return?)
- The two parameters are
i32(if it has two params) - The first return value is i32
WASMType
typedef struct WASMType {
uint16 param_count;
uint16 result_count;
uint16 param_cell_num;
uint16 ret_cell_num;
/* types of params and results */
uint8 types[1];
} WASMType;static bool
check_main_func_type(const WASMType *type)
{
if (!(type->param_count == 0 || type->param_count == 2)
||type->result_count > 1) {
LOG_ERROR("WASM execute application failed: invalid main function type.\n");
return false;
}
if (type->param_count == 2
&& !(type->types[0] == VALUE_TYPE_I32
&& type->types[1] == VALUE_TYPE_I32)) {
LOG_ERROR("WASM execute application failed: invalid main function type.\n");
return false;
}
if (type->result_count
&& type->types[type->param_count] != VALUE_TYPE_I32) {
LOG_ERROR("WASM execute application failed: invalid main function type.\n");
return false;
}
return true;
}wasm_runtime_create_exec_env_and_call_wasm
Depending on the type of module, invokes AoT or WASM executor.
bool
wasm_runtime_create_exec_env_and_call_wasm(WASMModuleInstanceCommon *module_inst,
WASMFunctionInstanceCommon *function,
uint32 argc, uint32 argv[])
{
bool ret = false;
#if WASM_ENABLE_INTERP != 0
if (module_inst->module_type == Wasm_Module_Bytecode)
ret = wasm_create_exec_env_and_call_function(
(WASMModuleInstance *)module_inst, (WASMFunctionInstance *)function,
argc, argv);
#endif
#if WASM_ENABLE_AOT != 0
if (module_inst->module_type == Wasm_Module_AoT)
ret = aot_create_exec_env_and_call_function(
(AOTModuleInstance *)module_inst, (AOTFunctionInstance *)function,
argc, argv);
#endif
return ret;
}wasm_create_exec_env_and_call_function
- Create environment
- Call the function
- Destory environment
bool
wasm_create_exec_env_and_call_function(WASMModuleInstance *module_inst,
WASMFunctionInstance *func,
unsigned argc, uint32 argv[])
{
WASMExecEnv *exec_env;
bool ret;
#if WASM_ENABLE_THREAD_MGR != 0
WASMExecEnv *existing_exec_env = NULL;
if (!(existing_exec_env = exec_env =
wasm_clusters_search_exec_env(
(WASMModuleInstanceCommon*)module_inst))) {
#endif
if (!(exec_env = wasm_exec_env_create(
(WASMModuleInstanceCommon*)module_inst,
module_inst->default_wasm_stack_size))) {
wasm_set_exception(module_inst, "allocate memory failed");
return false;
}
#if WASM_ENABLE_THREAD_MGR != 0
}
#endif
#if WASM_ENABLE_REF_TYPES != 0
wasm_runtime_prepare_call_function(exec_env, func);
#endif
ret = wasm_call_function(exec_env, func, argc, argv);
#if WASM_ENABLE_REF_TYPES != 0
wasm_runtime_finalize_call_function(exec_env, func, ret, argv);
#endif
#if WASM_ENABLE_THREAD_MGR != 0
/* don't destroy the exec_env if it's searched from the cluster */
if (!existing_exec_env)
#endif
wasm_exec_env_destroy(exec_env);
return ret;
}wasm_exec_env_create_internal
Mainly initializes the stack
WASMExecEnv *
wasm_exec_env_create_internal(struct WASMModuleInstanceCommon *module_inst,
uint32 stack_size)
{
uint64 total_size = offsetof(WASMExecEnv, wasm_stack.s.bottom)
+ (uint64)stack_size;
WASMExecEnv *exec_env;
if (total_size >= UINT32_MAX
|| !(exec_env = wasm_runtime_malloc((uint32)total_size)))
return NULL;
memset(exec_env, 0, (uint32)total_size);
#if WASM_ENABLE_AOT != 0
if (!(exec_env->argv_buf = wasm_runtime_malloc(sizeof(uint32) * 64))) {
goto fail1;
}
#endif
#if WASM_ENABLE_THREAD_MGR != 0
if (os_mutex_init(&exec_env->wait_lock) != 0)
goto fail2;
if (os_cond_init(&exec_env->wait_cond) != 0)
goto fail3;
#endif
exec_env->module_inst = module_inst;
exec_env->wasm_stack_size = stack_size;
exec_env->wasm_stack.s.top_boundary =
exec_env->wasm_stack.s.bottom + stack_size;
exec_env->wasm_stack.s.top = exec_env->wasm_stack.s.bottom;
#if WASM_ENABLE_MEMORY_TRACING != 0
wasm_runtime_dump_exec_env_mem_consumption(exec_env);
#endif
return exec_env;
#if WASM_ENABLE_THREAD_MGR != 0
fail3:
os_mutex_destroy(&exec_env->wait_lock);
fail2:
#endif
#if WASM_ENABLE_AOT != 0
wasm_runtime_free(exec_env->argv_buf);
fail1:
#endif
wasm_runtime_free(exec_env);
return NULL;
}wasm_call_function
bool
wasm_call_function(WASMExecEnv *exec_env,
WASMFunctionInstance *function,
unsigned argc, uint32 argv[])
{
WASMModuleInstance *module_inst = (WASMModuleInstance*)exec_env->module_inst;
/* set thread handle and stack boundary */
wasm_exec_env_set_thread_info(exec_env);
wasm_interp_call_wasm(module_inst, exec_env, function, argc, argv);
(void)clear_wasi_proc_exit_exception(module_inst);
return !wasm_get_exception(module_inst) ? true : false;
}void
wasm_exec_env_set_thread_info(WASMExecEnv *exec_env)
{
exec_env->handle = os_self_thread();
exec_env->native_stack_boundary = os_thread_get_stack_boundary()
+ RESERVED_BYTES_TO_NATIVE_STACK_BOUNDARY;
}The function os_thread_get_stack_boundary is empty for SGX platform!
wasm_interp_call_wasm\
- What's frame in the interpreter?
- Check the number of arguments coordinates with the function signature
- Check native stack boundary
- Allocate new frame and output pointer
- Copy args and update environment
- Execute the imported native function or WASM bytecode
- Get the result and return (to argv)
- Free frame
void
wasm_interp_call_wasm(WASMModuleInstance *module_inst,
WASMExecEnv *exec_env,
WASMFunctionInstance *function,
uint32 argc, uint32 argv[])
{
WASMRuntimeFrame *prev_frame = wasm_exec_env_get_cur_frame(exec_env);
WASMInterpFrame *frame, *outs_area;
/* Allocate sufficient cells for all kinds of return values. */
unsigned all_cell_num = function->ret_cell_num > 2 ?
function->ret_cell_num : 2, i;
/* This frame won't be used by JITed code, so only allocate interp
frame here. */
unsigned frame_size = wasm_interp_interp_frame_size(all_cell_num);
if (argc != function->param_cell_num) {
char buf[128];
snprintf(buf, sizeof(buf),
"invalid argument count %d, expected %d",
argc, function->param_cell_num);
wasm_set_exception(module_inst, buf);
return;
}
if ((uint8*)&prev_frame < exec_env->native_stack_boundary) {
wasm_set_exception((WASMModuleInstance*)exec_env->module_inst,
"native stack overflow");
return;
}
if (!(frame = ALLOC_FRAME(exec_env, frame_size, (WASMInterpFrame*)prev_frame)))
return;
outs_area = wasm_exec_env_wasm_stack_top(exec_env);
frame->function = NULL;
frame->ip = NULL;
/* There is no local variable. */
frame->sp = frame->lp + 0;
if (argc > 0)
word_copy(outs_area->lp, argv, argc);
wasm_exec_env_set_cur_frame(exec_env, frame);
if (function->is_import_func) {
#if WASM_ENABLE_MULTI_MODULE != 0
if (function->import_module_inst) {
wasm_interp_call_func_import(module_inst, exec_env,
function, frame);
}
else
#endif
{
/* it is a native function */
wasm_interp_call_func_native(module_inst, exec_env,
function, frame);
}
}
else {
wasm_interp_call_func_bytecode(module_inst, exec_env, function, frame);
}
/* Output the return value to the caller */
if (!wasm_get_exception(module_inst)) {
for (i = 0; i < function->ret_cell_num; i++) {
argv[i] = *(frame->sp + i - function->ret_cell_num);
}
}
else {
#if WASM_ENABLE_DUMP_CALL_STACK != 0
wasm_interp_dump_call_stack(exec_env);
#endif
LOG_DEBUG("meet an exception %s", wasm_get_exception(module_inst));
}
wasm_exec_env_set_cur_frame(exec_env, prev_frame);
FREE_FRAME(exec_env, frame);
}wasm_interp_call_func_bytecode
This is the core function to interpret the WASM bytecode.
static void
wasm_interp_call_func_bytecode(WASMModuleInstance *module,
WASMExecEnv *exec_env,
WASMFunctionInstance *cur_func,
WASMInterpFrame *prev_frame)
{
WASMMemoryInstance *memory = module->default_memory;
uint32 num_bytes_per_page = memory ? memory->num_bytes_per_page : 0;
uint8 *global_data = module->global_data;
uint32 linear_mem_size = memory ? num_bytes_per_page * memory->cur_page_count : 0;
WASMType **wasm_types = module->module->types;
WASMGlobalInstance *globals = module->globals, *global;
uint8 opcode_IMPDEP = WASM_OP_IMPDEP;
WASMInterpFrame *frame = NULL;
/* Points to this special opcode so as to jump to the call_method_from_entry. */
register uint8 *frame_ip = &opcode_IMPDEP; /* cache of frame->ip */
register uint32 *frame_lp = NULL; /* cache of frame->lp */
register uint32 *frame_sp = NULL; /* cache of frame->sp */
WASMBranchBlock *frame_csp = NULL;
BlockAddr *cache_items;
uint8 *frame_ip_end = frame_ip + 1;
uint8 opcode;
uint32 i, depth, cond, count, fidx, tidx, lidx, frame_size = 0;
uint64 all_cell_num = 0;
int32 val;
uint8 *else_addr, *end_addr, *maddr = NULL;
uint32 local_idx, local_offset, global_idx;
uint8 local_type, *global_addr;
uint32 cache_index, type_index, cell_num;
uint8 value_type;
#if WASM_ENABLE_LABELS_AS_VALUES != 0
#define HANDLE_OPCODE(op) &&HANDLE_##op
DEFINE_GOTO_TABLE (const void *, handle_table);
#undef HANDLE_OPCODE
#endif
#if WASM_ENABLE_LABELS_AS_VALUES == 0
while (frame_ip < frame_ip_end) {
opcode = *frame_ip++;
switch (opcode) {
#else
FETCH_OPCODE_AND_DISPATCH ();
#endif
/* control instructions */
HANDLE_OP (WASM_OP_UNREACHABLE):
wasm_set_exception(module, "unreachable");
goto got_exception;
HANDLE_OP (WASM_OP_NOP):
HANDLE_OP_END ();
HANDLE_OP (EXT_OP_BLOCK):
read_leb_uint32(frame_ip, frame_ip_end, type_index);
cell_num = wasm_types[type_index]->ret_cell_num;
goto handle_op_block;
HANDLE_OP (WASM_OP_BLOCK):
value_type = *frame_ip++;
cell_num = wasm_value_type_cell_num(value_type);
handle_op_block:
cache_index = ((uintptr_t)frame_ip) & (uintptr_t)(BLOCK_ADDR_CACHE_SIZE - 1);
cache_items = exec_env->block_addr_cache[cache_index];
if (cache_items[0].start_addr == frame_ip) {
end_addr = cache_items[0].end_addr;
}
else if (cache_items[1].start_addr == frame_ip) {
end_addr = cache_items[1].end_addr;
}
else {
end_addr = NULL;
}
PUSH_CSP(LABEL_TYPE_BLOCK, cell_num, end_addr);
HANDLE_OP_END ();
HANDLE_OP (EXT_OP_LOOP):
read_leb_uint32(frame_ip, frame_ip_end, type_index);
cell_num = wasm_types[type_index]->param_cell_num;
goto handle_op_loop;
HANDLE_OP (WASM_OP_LOOP):
value_type = *frame_ip++;
cell_num = wasm_value_type_cell_num(value_type);
handle_op_loop:
PUSH_CSP(LABEL_TYPE_LOOP, cell_num, frame_ip);
HANDLE_OP_END ();
HANDLE_OP (EXT_OP_IF):
read_leb_uint32(frame_ip, frame_ip_end, type_index);
cell_num = wasm_types[type_index]->ret_cell_num;
goto handle_op_if;
HANDLE_OP (WASM_OP_IF):
value_type = *frame_ip++;
cell_num = wasm_value_type_cell_num(value_type);
handle_op_if:
cache_index = ((uintptr_t)frame_ip) & (uintptr_t)(BLOCK_ADDR_CACHE_SIZE - 1);
cache_items = exec_env->block_addr_cache[cache_index];
if (cache_items[0].start_addr == frame_ip) {
else_addr = cache_items[0].else_addr;
end_addr = cache_items[0].end_addr;
}
else if (cache_items[1].start_addr == frame_ip) {
else_addr = cache_items[1].else_addr;
end_addr = cache_items[1].end_addr;
}
else if (!wasm_loader_find_block_addr((BlockAddr*)exec_env->block_addr_cache,
frame_ip, (uint8*)-1,
LABEL_TYPE_IF,
&else_addr, &end_addr)) {
wasm_set_exception(module, "find block address failed");
goto got_exception;
}
cond = (uint32)POP_I32();
if (cond) { /* if branch is met */
PUSH_CSP(LABEL_TYPE_IF, cell_num, end_addr);
}
else { /* if branch is not met */
/* if there is no else branch, go to the end addr */
if (else_addr == NULL) {
frame_ip = end_addr + 1;
}
/* if there is an else branch, go to the else addr */
else {
PUSH_CSP(LABEL_TYPE_IF, cell_num, end_addr);
frame_ip = else_addr + 1;
}
}
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_ELSE):
/* comes from the if branch in WASM_OP_IF */
frame_ip = (frame_csp - 1)->target_addr;
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_END):
if (frame_csp > frame->csp_bottom + 1) {
POP_CSP();
}
else { /* end of function, treat as WASM_OP_RETURN */
frame_sp -= cur_func->ret_cell_num;
for (i = 0; i < cur_func->ret_cell_num; i++) {
*prev_frame->sp++ = frame_sp[i];
}
goto return_func;
}
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_BR):
#if WASM_ENABLE_THREAD_MGR != 0
CHECK_SUSPEND_FLAGS();
#endif
read_leb_uint32(frame_ip, frame_ip_end, depth);
label_pop_csp_n:
POP_CSP_N(depth);
if (!frame_ip) { /* must be label pushed by WASM_OP_BLOCK */
if (!wasm_loader_find_block_addr((BlockAddr*)exec_env->block_addr_cache,
(frame_csp - 1)->begin_addr, (uint8*)-1,
LABEL_TYPE_BLOCK,
&else_addr, &end_addr)) {
wasm_set_exception(module, "find block address failed");
goto got_exception;
}
frame_ip = end_addr;
}
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_BR_IF):
#if WASM_ENABLE_THREAD_MGR != 0
CHECK_SUSPEND_FLAGS();
#endif
read_leb_uint32(frame_ip, frame_ip_end, depth);
cond = (uint32)POP_I32();
if (cond)
goto label_pop_csp_n;
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_BR_TABLE):
#if WASM_ENABLE_THREAD_MGR != 0
CHECK_SUSPEND_FLAGS();
#endif
read_leb_uint32(frame_ip, frame_ip_end, count);
lidx = POP_I32();
if (lidx > count)
lidx = count;
for (i = 0; i < lidx; i++)
skip_leb(frame_ip);
read_leb_uint32(frame_ip, frame_ip_end, depth);
goto label_pop_csp_n;
HANDLE_OP (WASM_OP_RETURN):
frame_sp -= cur_func->ret_cell_num;
for (i = 0; i < cur_func->ret_cell_num; i++) {
*prev_frame->sp++ = frame_sp[i];
}
goto return_func;
HANDLE_OP (WASM_OP_CALL):
#if WASM_ENABLE_THREAD_MGR != 0
CHECK_SUSPEND_FLAGS();
#endif
read_leb_uint32(frame_ip, frame_ip_end, fidx);
#if WASM_ENABLE_MULTI_MODULE != 0
if (fidx >= module->function_count) {
wasm_set_exception(module, "unknown function");
goto got_exception;
}
#endif
cur_func = module->functions + fidx;
goto call_func_from_interp;
#if WASM_ENABLE_TAIL_CALL != 0
HANDLE_OP (WASM_OP_RETURN_CALL):
#if WASM_ENABLE_THREAD_MGR != 0
CHECK_SUSPEND_FLAGS();
#endif
read_leb_uint32(frame_ip, frame_ip_end, fidx);
#if WASM_ENABLE_MULTI_MODULE != 0
if (fidx >= module->function_count) {
wasm_set_exception(module, "unknown function");
goto got_exception;
}
#endif
cur_func = module->functions + fidx;
goto call_func_from_return_call;
#endif /* WASM_ENABLE_TAIL_CALL */
HANDLE_OP (WASM_OP_CALL_INDIRECT):
#if WASM_ENABLE_TAIL_CALL != 0
HANDLE_OP (WASM_OP_RETURN_CALL_INDIRECT):
#endif
{
WASMType *cur_type, *cur_func_type;
WASMTableInstance *tbl_inst;
uint32 tbl_idx;
#if WASM_ENABLE_TAIL_CALL != 0
opcode = *(frame_ip - 1);
#endif
#if WASM_ENABLE_THREAD_MGR != 0
CHECK_SUSPEND_FLAGS();
#endif
/**
* type check. compiler will make sure all like
* (call_indirect (type $x) (i32.const 1))
* the function type has to be defined in the module also
* no matter it is used or not
*/
read_leb_uint32(frame_ip, frame_ip_end, tidx);
bh_assert(tidx < module->module->type_count);
cur_type = wasm_types[tidx];
read_leb_uint32(frame_ip, frame_ip_end, tbl_idx);
bh_assert(tbl_idx < module->table_count);
tbl_inst = wasm_get_table_inst(module, tbl_idx);
val = POP_I32();
if (val < 0 || val >= (int32)tbl_inst->cur_size) {
wasm_set_exception(module, "undefined element");
goto got_exception;
}
fidx = ((uint32*)tbl_inst->base_addr)[val];
if (fidx == (uint32)-1) {
wasm_set_exception(module, "uninitialized element");
goto got_exception;
}
/*
* we might be using a table injected by host or
* another module. In that case, we don't validate
* the elem value while loading
*/
if (fidx >= module->function_count) {
wasm_set_exception(module, "unknown function");
goto got_exception;
}
/* always call module own functions */
cur_func = module->functions + fidx;
if (cur_func->is_import_func)
cur_func_type = cur_func->u.func_import->func_type;
else
cur_func_type = cur_func->u.func->func_type;
if (!wasm_type_equal(cur_type, cur_func_type)) {
wasm_set_exception(module, "indirect call type mismatch");
goto got_exception;
}
#if WASM_ENABLE_TAIL_CALL != 0
if (opcode == WASM_OP_RETURN_CALL_INDIRECT)
goto call_func_from_return_call;
#endif
goto call_func_from_interp;
}
/* parametric instructions */
HANDLE_OP (WASM_OP_DROP):
{
frame_sp--;
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_DROP_64):
{
frame_sp -= 2;
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_SELECT):
{
cond = (uint32)POP_I32();
frame_sp--;
if (!cond)
*(frame_sp - 1) = *frame_sp;
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_SELECT_64):
{
cond = (uint32)POP_I32();
frame_sp -= 2;
if (!cond) {
*(frame_sp - 2) = *frame_sp;
*(frame_sp - 1) = *(frame_sp + 1);
}
HANDLE_OP_END ();
}
#if WASM_ENABLE_REF_TYPES != 0
HANDLE_OP (WASM_OP_SELECT_T):
{
uint32 vec_len;
uint8 type;
read_leb_uint32(frame_ip, frame_ip_end, vec_len);
type = *frame_ip++;
cond = (uint32)POP_I32();
if (type == VALUE_TYPE_I64 || type == VALUE_TYPE_F64) {
frame_sp -= 2;
if (!cond) {
*(frame_sp - 2) = *frame_sp;
*(frame_sp - 1) = *(frame_sp + 1);
}
}
else {
frame_sp--;
if (!cond)
*(frame_sp - 1) = *frame_sp;
}
(void)vec_len;
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_TABLE_GET):
{
uint32 tbl_idx, elem_idx;
WASMTableInstance *tbl_inst;
read_leb_uint32(frame_ip, frame_ip_end, tbl_idx);
bh_assert(tbl_idx < module->table_count);
tbl_inst = wasm_get_table_inst(module, tbl_idx);
elem_idx = POP_I32();
if (elem_idx >= tbl_inst->cur_size) {
wasm_set_exception(module, "out of bounds table access");
goto got_exception;
}
PUSH_I32(((uint32 *)tbl_inst->base_addr)[elem_idx]);
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_TABLE_SET):
{
uint32 tbl_idx, elem_idx, val;
WASMTableInstance *tbl_inst;
read_leb_uint32(frame_ip, frame_ip_end, tbl_idx);
bh_assert(tbl_idx < module->table_count);
tbl_inst = wasm_get_table_inst(module, tbl_idx);
val = POP_I32();
elem_idx = POP_I32();
if (elem_idx >= tbl_inst->cur_size) {
wasm_set_exception(module, "out of bounds table access");
goto got_exception;
}
((uint32 *)(tbl_inst->base_addr))[elem_idx] = val;
HANDLE_OP_END();
}
HANDLE_OP (WASM_OP_REF_NULL):
{
uint32 ref_type;
read_leb_uint32(frame_ip, frame_ip_end, ref_type);
PUSH_I32(NULL_REF);
(void)ref_type;
HANDLE_OP_END();
}
HANDLE_OP (WASM_OP_REF_IS_NULL):
{
uint32 val;
val = POP_I32();
PUSH_I32(val == NULL_REF ? 1 : 0);
HANDLE_OP_END();
}
HANDLE_OP (WASM_OP_REF_FUNC):
{
uint32 func_idx;
read_leb_uint32(frame_ip, frame_ip_end, func_idx);
PUSH_I32(func_idx);
HANDLE_OP_END();
}
#endif /* WASM_ENABLE_REF_TYPES */
/* variable instructions */
HANDLE_OP (WASM_OP_GET_LOCAL):
{
GET_LOCAL_INDEX_TYPE_AND_OFFSET();
switch (local_type) {
case VALUE_TYPE_I32:
case VALUE_TYPE_F32:
#if WASM_ENABLE_REF_TYPES != 0
case VALUE_TYPE_FUNCREF:
case VALUE_TYPE_EXTERNREF:
#endif
PUSH_I32(*(int32*)(frame_lp + local_offset));
break;
case VALUE_TYPE_I64:
case VALUE_TYPE_F64:
PUSH_I64(GET_I64_FROM_ADDR(frame_lp + local_offset));
break;
default:
wasm_set_exception(module, "invalid local type");
goto got_exception;
}
HANDLE_OP_END ();
}
HANDLE_OP (EXT_OP_GET_LOCAL_FAST):
{
local_offset = *frame_ip++;
if (local_offset & 0x80)
PUSH_I64(GET_I64_FROM_ADDR(frame_lp + (local_offset & 0x7F)));
else
PUSH_I32(*(int32*)(frame_lp + local_offset));
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_SET_LOCAL):
{
GET_LOCAL_INDEX_TYPE_AND_OFFSET();
switch (local_type) {
case VALUE_TYPE_I32:
case VALUE_TYPE_F32:
#if WASM_ENABLE_REF_TYPES != 0
case VALUE_TYPE_FUNCREF:
case VALUE_TYPE_EXTERNREF:
#endif
*(int32*)(frame_lp + local_offset) = POP_I32();
break;
case VALUE_TYPE_I64:
case VALUE_TYPE_F64:
PUT_I64_TO_ADDR((uint32*)(frame_lp + local_offset), POP_I64());
break;
default:
wasm_set_exception(module, "invalid local type");
goto got_exception;
}
HANDLE_OP_END ();
}
HANDLE_OP (EXT_OP_SET_LOCAL_FAST):
{
local_offset = *frame_ip++;
if (local_offset & 0x80)
PUT_I64_TO_ADDR((uint32*)(frame_lp + (local_offset & 0x7F)), POP_I64());
else
*(int32*)(frame_lp + local_offset) = POP_I32();
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_TEE_LOCAL):
{
GET_LOCAL_INDEX_TYPE_AND_OFFSET();
switch (local_type) {
case VALUE_TYPE_I32:
case VALUE_TYPE_F32:
#if WASM_ENABLE_REF_TYPES != 0
case VALUE_TYPE_FUNCREF:
case VALUE_TYPE_EXTERNREF:
#endif
*(int32*)(frame_lp + local_offset) = *(int32*)(frame_sp - 1);
break;
case VALUE_TYPE_I64:
case VALUE_TYPE_F64:
PUT_I64_TO_ADDR((uint32*)(frame_lp + local_offset),
GET_I64_FROM_ADDR(frame_sp - 2));
break;
default:
wasm_set_exception(module, "invalid local type");
goto got_exception;
}
HANDLE_OP_END ();
}
HANDLE_OP (EXT_OP_TEE_LOCAL_FAST):
{
local_offset = *frame_ip++;
if (local_offset & 0x80)
PUT_I64_TO_ADDR((uint32*)(frame_lp + (local_offset & 0x7F)),
GET_I64_FROM_ADDR(frame_sp - 2));
else
*(int32*)(frame_lp + local_offset) = *(int32*)(frame_sp - 1);
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_GET_GLOBAL):
{
read_leb_uint32(frame_ip, frame_ip_end, global_idx);
bh_assert(global_idx < module->global_count);
global = globals + global_idx;
#if WASM_ENABLE_MULTI_MODULE == 0
global_addr = global_data + global->data_offset;
#else
global_addr = global->import_global_inst
? global->import_module_inst->global_data
+ global->import_global_inst->data_offset
: global_data + global->data_offset;
#endif
PUSH_I32(*(uint32*)global_addr);
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_GET_GLOBAL_64):
{
read_leb_uint32(frame_ip, frame_ip_end, global_idx);
bh_assert(global_idx < module->global_count);
global = globals + global_idx;
#if WASM_ENABLE_MULTI_MODULE == 0
global_addr = global_data + global->data_offset;
#else
global_addr = global->import_global_inst
? global->import_module_inst->global_data
+ global->import_global_inst->data_offset
: global_data + global->data_offset;
#endif
PUSH_I64(GET_I64_FROM_ADDR((uint32*)global_addr));
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_SET_GLOBAL):
{
read_leb_uint32(frame_ip, frame_ip_end, global_idx);
bh_assert(global_idx < module->global_count);
global = globals + global_idx;
#if WASM_ENABLE_MULTI_MODULE == 0
global_addr = global_data + global->data_offset;
#else
global_addr = global->import_global_inst
? global->import_module_inst->global_data
+ global->import_global_inst->data_offset
: global_data + global->data_offset;
#endif
*(int32*)global_addr = POP_I32();
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_SET_GLOBAL_AUX_STACK):
{
uint32 aux_stack_top;
read_leb_uint32(frame_ip, frame_ip_end, global_idx);
bh_assert(global_idx < module->global_count);
global = globals + global_idx;
#if WASM_ENABLE_MULTI_MODULE == 0
global_addr = global_data + global->data_offset;
#else
global_addr = global->import_global_inst
? global->import_module_inst->global_data
+ global->import_global_inst->data_offset
: global_data + global->data_offset;
#endif
aux_stack_top = *(uint32*)(frame_sp - 1);
if (aux_stack_top <= exec_env->aux_stack_boundary.boundary) {
wasm_set_exception(module, "wasm auxiliary stack overflow");
goto got_exception;
}
if (aux_stack_top > exec_env->aux_stack_bottom.bottom) {
wasm_set_exception(module, "wasm auxiliary stack underflow");
goto got_exception;
}
*(int32*)global_addr = aux_stack_top;
frame_sp--;
#if WASM_ENABLE_MEMORY_PROFILING != 0
if (module->module->aux_stack_top_global_index != (uint32)-1) {
uint32 aux_stack_used =
module->module->aux_stack_bottom - *(uint32*)global_addr;
if (aux_stack_used > module->max_aux_stack_used)
module->max_aux_stack_used = aux_stack_used;
}
#endif
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_SET_GLOBAL_64):
{
read_leb_uint32(frame_ip, frame_ip_end, global_idx);
bh_assert(global_idx < module->global_count);
global = globals + global_idx;
#if WASM_ENABLE_MULTI_MODULE == 0
global_addr = global_data + global->data_offset;
#else
global_addr = global->import_global_inst
? global->import_module_inst->global_data
+ global->import_global_inst->data_offset
: global_data + global->data_offset;
#endif
PUT_I64_TO_ADDR((uint32*)global_addr, POP_I64());
HANDLE_OP_END ();
}
/* memory load instructions */
HANDLE_OP (WASM_OP_I32_LOAD):
HANDLE_OP (WASM_OP_F32_LOAD):
{
uint32 offset, flags, addr;
read_leb_uint32(frame_ip, frame_ip_end, flags);
read_leb_uint32(frame_ip, frame_ip_end, offset);
addr = POP_I32();
CHECK_MEMORY_OVERFLOW(4);
PUSH_I32(LOAD_I32(maddr));
(void)flags;
HANDLE_OP_END();
}
HANDLE_OP (WASM_OP_I64_LOAD):
HANDLE_OP (WASM_OP_F64_LOAD):
{
uint32 offset, flags, addr;
read_leb_uint32(frame_ip, frame_ip_end, flags);
read_leb_uint32(frame_ip, frame_ip_end, offset);
addr = POP_I32();
CHECK_MEMORY_OVERFLOW(8);
PUSH_I64(LOAD_I64(maddr));
(void)flags;
HANDLE_OP_END();
}
HANDLE_OP (WASM_OP_I32_LOAD8_S):
{
uint32 offset, flags, addr;
read_leb_uint32(frame_ip, frame_ip_end, flags);
read_leb_uint32(frame_ip, frame_ip_end, offset);
addr = POP_I32();
CHECK_MEMORY_OVERFLOW(1);
PUSH_I32(sign_ext_8_32(*(int8*)maddr));
(void)flags;
HANDLE_OP_END();
}
HANDLE_OP (WASM_OP_I32_LOAD8_U):
{
uint32 offset, flags, addr;
read_leb_uint32(frame_ip, frame_ip_end, flags);
read_leb_uint32(frame_ip, frame_ip_end, offset);
addr = POP_I32();
CHECK_MEMORY_OVERFLOW(1);
PUSH_I32((uint32)(*(uint8*)maddr));
(void)flags;
HANDLE_OP_END();
}
HANDLE_OP (WASM_OP_I32_LOAD16_S):
{
uint32 offset, flags, addr;
read_leb_uint32(frame_ip, frame_ip_end, flags);
read_leb_uint32(frame_ip, frame_ip_end, offset);
addr = POP_I32();
CHECK_MEMORY_OVERFLOW(2);
PUSH_I32(sign_ext_16_32(LOAD_I16(maddr)));
(void)flags;
HANDLE_OP_END();
}
HANDLE_OP (WASM_OP_I32_LOAD16_U):
{
uint32 offset, flags, addr;
read_leb_uint32(frame_ip, frame_ip_end, flags);
read_leb_uint32(frame_ip, frame_ip_end, offset);
addr = POP_I32();
CHECK_MEMORY_OVERFLOW(2);
PUSH_I32((uint32)(LOAD_U16(maddr)));
(void)flags;
HANDLE_OP_END();
}
HANDLE_OP (WASM_OP_I64_LOAD8_S):
{
uint32 offset, flags, addr;
read_leb_uint32(frame_ip, frame_ip_end, flags);
read_leb_uint32(frame_ip, frame_ip_end, offset);
addr = POP_I32();
CHECK_MEMORY_OVERFLOW(1);
PUSH_I64(sign_ext_8_64(*(int8*)maddr));
(void)flags;
HANDLE_OP_END();
}
HANDLE_OP (WASM_OP_I64_LOAD8_U):
{
uint32 offset, flags, addr;
read_leb_uint32(frame_ip, frame_ip_end, flags);
read_leb_uint32(frame_ip, frame_ip_end, offset);
addr = POP_I32();
CHECK_MEMORY_OVERFLOW(1);
PUSH_I64((uint64)(*(uint8*)maddr));
(void)flags;
HANDLE_OP_END();
}
HANDLE_OP (WASM_OP_I64_LOAD16_S):
{
uint32 offset, flags, addr;
read_leb_uint32(frame_ip, frame_ip_end, flags);
read_leb_uint32(frame_ip, frame_ip_end, offset);
addr = POP_I32();
CHECK_MEMORY_OVERFLOW(2);
PUSH_I64(sign_ext_16_64(LOAD_I16(maddr)));
(void)flags;
HANDLE_OP_END();
}
HANDLE_OP (WASM_OP_I64_LOAD16_U):
{
uint32 offset, flags, addr;
read_leb_uint32(frame_ip, frame_ip_end, flags);
read_leb_uint32(frame_ip, frame_ip_end, offset);
addr = POP_I32();
CHECK_MEMORY_OVERFLOW(2);
PUSH_I64((uint64)(LOAD_U16(maddr)));
(void)flags;
HANDLE_OP_END();
}
HANDLE_OP (WASM_OP_I64_LOAD32_S):
{
uint32 offset, flags, addr;
opcode = *(frame_ip - 1);
read_leb_uint32(frame_ip, frame_ip_end, flags);
read_leb_uint32(frame_ip, frame_ip_end, offset);
addr = POP_I32();
CHECK_MEMORY_OVERFLOW(4);
PUSH_I64(sign_ext_32_64(LOAD_I32(maddr)));
(void)flags;
HANDLE_OP_END();
}
HANDLE_OP (WASM_OP_I64_LOAD32_U):
{
uint32 offset, flags, addr;
read_leb_uint32(frame_ip, frame_ip_end, flags);
read_leb_uint32(frame_ip, frame_ip_end, offset);
addr = POP_I32();
CHECK_MEMORY_OVERFLOW(4);
PUSH_I64((uint64)(LOAD_U32(maddr)));
(void)flags;
HANDLE_OP_END();
}
/* memory store instructions */
HANDLE_OP (WASM_OP_I32_STORE):
HANDLE_OP (WASM_OP_F32_STORE):
{
uint32 offset, flags, addr;
read_leb_uint32(frame_ip, frame_ip_end, flags);
read_leb_uint32(frame_ip, frame_ip_end, offset);
frame_sp--;
addr = POP_I32();
CHECK_MEMORY_OVERFLOW(4);
STORE_U32(maddr, frame_sp[1]);
(void)flags;
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_I64_STORE):
HANDLE_OP (WASM_OP_F64_STORE):
{
uint32 offset, flags, addr;
read_leb_uint32(frame_ip, frame_ip_end, flags);
read_leb_uint32(frame_ip, frame_ip_end, offset);
frame_sp -= 2;
addr = POP_I32();
CHECK_MEMORY_OVERFLOW(8);
STORE_U32(maddr, frame_sp[1]);
STORE_U32(maddr + 4, frame_sp[2]);
(void)flags;
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_I32_STORE8):
HANDLE_OP (WASM_OP_I32_STORE16):
{
uint32 offset, flags, addr;
uint32 sval;
opcode = *(frame_ip - 1);
read_leb_uint32(frame_ip, frame_ip_end, flags);
read_leb_uint32(frame_ip, frame_ip_end, offset);
sval = (uint32)POP_I32();
addr = POP_I32();
if (opcode == WASM_OP_I32_STORE8) {
CHECK_MEMORY_OVERFLOW(1);
*(uint8*)maddr = (uint8)sval;
}
else {
CHECK_MEMORY_OVERFLOW(2);
STORE_U16(maddr, (uint16)sval);
}
(void)flags;
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_I64_STORE8):
HANDLE_OP (WASM_OP_I64_STORE16):
HANDLE_OP (WASM_OP_I64_STORE32):
{
uint32 offset, flags, addr;
uint64 sval;
opcode = *(frame_ip - 1);
read_leb_uint32(frame_ip, frame_ip_end, flags);
read_leb_uint32(frame_ip, frame_ip_end, offset);
sval = (uint64)POP_I64();
addr = POP_I32();
if (opcode == WASM_OP_I64_STORE8) {
CHECK_MEMORY_OVERFLOW(1);
*(uint8*)maddr = (uint8)sval;
}
else if(opcode == WASM_OP_I64_STORE16) {
CHECK_MEMORY_OVERFLOW(2);
STORE_U16(maddr, (uint16)sval);
}
else {
CHECK_MEMORY_OVERFLOW(4);
STORE_U32(maddr, (uint32)sval);
}
(void)flags;
HANDLE_OP_END ();
}
/* memory size and memory grow instructions */
HANDLE_OP (WASM_OP_MEMORY_SIZE):
{
uint32 reserved;
read_leb_uint32(frame_ip, frame_ip_end, reserved);
PUSH_I32(memory->cur_page_count);
(void)reserved;
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_MEMORY_GROW):
{
uint32 reserved, delta, prev_page_count = memory->cur_page_count;
read_leb_uint32(frame_ip, frame_ip_end, reserved);
delta = (uint32)POP_I32();
if (!wasm_enlarge_memory(module, delta)) {
/* failed to memory.grow, return -1 */
PUSH_I32(-1);
}
else {
/* success, return previous page count */
PUSH_I32(prev_page_count);
/* update memory instance ptr and memory size */
memory = module->default_memory;
linear_mem_size = num_bytes_per_page * memory->cur_page_count;
}
(void)reserved;
HANDLE_OP_END ();
}
/* constant instructions */
HANDLE_OP (WASM_OP_I32_CONST):
DEF_OP_I_CONST(int32, I32);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I64_CONST):
DEF_OP_I_CONST(int64, I64);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F32_CONST):
{
uint8 *p_float = (uint8*)frame_sp++;
for (i = 0; i < sizeof(float32); i++)
*p_float++ = *frame_ip++;
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_F64_CONST):
{
uint8 *p_float = (uint8*)frame_sp++;
frame_sp++;
for (i = 0; i < sizeof(float64); i++)
*p_float++ = *frame_ip++;
HANDLE_OP_END ();
}
/* comparison instructions of i32 */
HANDLE_OP (WASM_OP_I32_EQZ):
DEF_OP_EQZ(I32);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I32_EQ):
DEF_OP_CMP(uint32, I32, ==);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I32_NE):
DEF_OP_CMP(uint32, I32, !=);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I32_LT_S):
DEF_OP_CMP(int32, I32, <);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I32_LT_U):
DEF_OP_CMP(uint32, I32, <);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I32_GT_S):
DEF_OP_CMP(int32, I32, >);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I32_GT_U):
DEF_OP_CMP(uint32, I32, >);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I32_LE_S):
DEF_OP_CMP(int32, I32, <=);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I32_LE_U):
DEF_OP_CMP(uint32, I32, <=);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I32_GE_S):
DEF_OP_CMP(int32, I32, >=);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I32_GE_U):
DEF_OP_CMP(uint32, I32, >=);
HANDLE_OP_END ();
/* comparison instructions of i64 */
HANDLE_OP (WASM_OP_I64_EQZ):
DEF_OP_EQZ(I64);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I64_EQ):
DEF_OP_CMP(uint64, I64, ==);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I64_NE):
DEF_OP_CMP(uint64, I64, !=);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I64_LT_S):
DEF_OP_CMP(int64, I64, <);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I64_LT_U):
DEF_OP_CMP(uint64, I64, <);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I64_GT_S):
DEF_OP_CMP(int64, I64, >);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I64_GT_U):
DEF_OP_CMP(uint64, I64, >);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I64_LE_S):
DEF_OP_CMP(int64, I64, <=);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I64_LE_U):
DEF_OP_CMP(uint64, I64, <=);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I64_GE_S):
DEF_OP_CMP(int64, I64, >=);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I64_GE_U):
DEF_OP_CMP(uint64, I64, >=);
HANDLE_OP_END ();
/* comparison instructions of f32 */
HANDLE_OP (WASM_OP_F32_EQ):
DEF_OP_CMP(float32, F32, ==);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F32_NE):
DEF_OP_CMP(float32, F32, !=);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F32_LT):
DEF_OP_CMP(float32, F32, <);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F32_GT):
DEF_OP_CMP(float32, F32, >);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F32_LE):
DEF_OP_CMP(float32, F32, <=);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F32_GE):
DEF_OP_CMP(float32, F32, >=);
HANDLE_OP_END ();
/* comparison instructions of f64 */
HANDLE_OP (WASM_OP_F64_EQ):
DEF_OP_CMP(float64, F64, ==);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F64_NE):
DEF_OP_CMP(float64, F64, !=);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F64_LT):
DEF_OP_CMP(float64, F64, <);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F64_GT):
DEF_OP_CMP(float64, F64, >);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F64_LE):
DEF_OP_CMP(float64, F64, <=);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F64_GE):
DEF_OP_CMP(float64, F64, >=);
HANDLE_OP_END ();
/* numberic instructions of i32 */
HANDLE_OP (WASM_OP_I32_CLZ):
DEF_OP_BIT_COUNT(uint32, I32, clz32);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I32_CTZ):
DEF_OP_BIT_COUNT(uint32, I32, ctz32);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I32_POPCNT):
DEF_OP_BIT_COUNT(uint32, I32, popcount32);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I32_ADD):
DEF_OP_NUMERIC(uint32, uint32, I32, +);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I32_SUB):
DEF_OP_NUMERIC(uint32, uint32, I32, -);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I32_MUL):
DEF_OP_NUMERIC(uint32, uint32, I32, *);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I32_DIV_S):
{
int32 a, b;
b = POP_I32();
a = POP_I32();
if (a == (int32)0x80000000 && b == -1) {
wasm_set_exception(module, "integer overflow");
goto got_exception;
}
if (b == 0) {
wasm_set_exception(module, "integer divide by zero");
goto got_exception;
}
PUSH_I32(a / b);
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_I32_DIV_U):
{
uint32 a, b;
b = (uint32)POP_I32();
a = (uint32)POP_I32();
if (b == 0) {
wasm_set_exception(module, "integer divide by zero");
goto got_exception;
}
PUSH_I32(a / b);
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_I32_REM_S):
{
int32 a, b;
b = POP_I32();
a = POP_I32();
if (a == (int32)0x80000000 && b == -1) {
PUSH_I32(0);
HANDLE_OP_END ();
}
if (b == 0) {
wasm_set_exception(module, "integer divide by zero");
goto got_exception;
}
PUSH_I32(a % b);
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_I32_REM_U):
{
uint32 a, b;
b = (uint32)POP_I32();
a = (uint32)POP_I32();
if (b == 0) {
wasm_set_exception(module, "integer divide by zero");
goto got_exception;
}
PUSH_I32(a % b);
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_I32_AND):
DEF_OP_NUMERIC(uint32, uint32, I32, &);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I32_OR):
DEF_OP_NUMERIC(uint32, uint32, I32, |);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I32_XOR):
DEF_OP_NUMERIC(uint32, uint32, I32, ^);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I32_SHL):
{
#if defined(BUILD_TARGET_X86_64) || defined(BUILD_TARGET_X86_32)
DEF_OP_NUMERIC(uint32, uint32, I32, <<);
#else
DEF_OP_NUMERIC2(uint32, uint32, I32, <<);
#endif
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_I32_SHR_S):
{
#if defined(BUILD_TARGET_X86_64) || defined(BUILD_TARGET_X86_32)
DEF_OP_NUMERIC(int32, uint32, I32, >>);
#else
DEF_OP_NUMERIC2(int32, uint32, I32, >>);
#endif
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_I32_SHR_U):
{
#if defined(BUILD_TARGET_X86_64) || defined(BUILD_TARGET_X86_32)
DEF_OP_NUMERIC(uint32, uint32, I32, >>);
#else
DEF_OP_NUMERIC2(uint32, uint32, I32, >>);
#endif
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_I32_ROTL):
{
uint32 a, b;
b = (uint32)POP_I32();
a = (uint32)POP_I32();
PUSH_I32(rotl32(a, b));
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_I32_ROTR):
{
uint32 a, b;
b = (uint32)POP_I32();
a = (uint32)POP_I32();
PUSH_I32(rotr32(a, b));
HANDLE_OP_END ();
}
/* numberic instructions of i64 */
HANDLE_OP (WASM_OP_I64_CLZ):
DEF_OP_BIT_COUNT(uint64, I64, clz64);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I64_CTZ):
DEF_OP_BIT_COUNT(uint64, I64, ctz64);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I64_POPCNT):
DEF_OP_BIT_COUNT(uint64, I64, popcount64);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I64_ADD):
DEF_OP_NUMERIC_64(uint64, uint64, I64, +);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I64_SUB):
DEF_OP_NUMERIC_64(uint64, uint64, I64, -);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I64_MUL):
DEF_OP_NUMERIC_64(uint64, uint64, I64, *);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I64_DIV_S):
{
int64 a, b;
b = POP_I64();
a = POP_I64();
if (a == (int64)0x8000000000000000LL && b == -1) {
wasm_set_exception(module, "integer overflow");
goto got_exception;
}
if (b == 0) {
wasm_set_exception(module, "integer divide by zero");
goto got_exception;
}
PUSH_I64(a / b);
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_I64_DIV_U):
{
uint64 a, b;
b = (uint64)POP_I64();
a = (uint64)POP_I64();
if (b == 0) {
wasm_set_exception(module, "integer divide by zero");
goto got_exception;
}
PUSH_I64(a / b);
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_I64_REM_S):
{
int64 a, b;
b = POP_I64();
a = POP_I64();
if (a == (int64)0x8000000000000000LL && b == -1) {
PUSH_I64(0);
HANDLE_OP_END ();
}
if (b == 0) {
wasm_set_exception(module, "integer divide by zero");
goto got_exception;
}
PUSH_I64(a % b);
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_I64_REM_U):
{
uint64 a, b;
b = (uint64)POP_I64();
a = (uint64)POP_I64();
if (b == 0) {
wasm_set_exception(module, "integer divide by zero");
goto got_exception;
}
PUSH_I64(a % b);
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_I64_AND):
DEF_OP_NUMERIC_64(uint64, uint64, I64, &);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I64_OR):
DEF_OP_NUMERIC_64(uint64, uint64, I64, |);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I64_XOR):
DEF_OP_NUMERIC_64(uint64, uint64, I64, ^);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I64_SHL):
{
#if defined(BUILD_TARGET_X86_64) || defined(BUILD_TARGET_X86_32)
DEF_OP_NUMERIC_64(uint64, uint64, I64, <<);
#else
DEF_OP_NUMERIC2_64(uint64, uint64, I64, <<);
#endif
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_I64_SHR_S):
{
#if defined(BUILD_TARGET_X86_64) || defined(BUILD_TARGET_X86_32)
DEF_OP_NUMERIC_64(int64, uint64, I64, >>);
#else
DEF_OP_NUMERIC2_64(int64, uint64, I64, >>);
#endif
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_I64_SHR_U):
{
#if defined(BUILD_TARGET_X86_64) || defined(BUILD_TARGET_X86_32)
DEF_OP_NUMERIC_64(uint64, uint64, I64, >>);
#else
DEF_OP_NUMERIC2_64(uint64, uint64, I64, >>);
#endif
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_I64_ROTL):
{
uint64 a, b;
b = (uint64)POP_I64();
a = (uint64)POP_I64();
PUSH_I64(rotl64(a, b));
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_I64_ROTR):
{
uint64 a, b;
b = (uint64)POP_I64();
a = (uint64)POP_I64();
PUSH_I64(rotr64(a, b));
HANDLE_OP_END ();
}
/* numberic instructions of f32 */
HANDLE_OP (WASM_OP_F32_ABS):
DEF_OP_MATH(float32, F32, fabs);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F32_NEG):
{
int32 i32 = (int32)frame_sp[-1];
int32 sign_bit = i32 & (1 << 31);
if (sign_bit)
frame_sp[-1] = i32 & ~(1 << 31);
else
frame_sp[-1] = (uint32)(i32 | (1 << 31));
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_F32_CEIL):
DEF_OP_MATH(float32, F32, ceil);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F32_FLOOR):
DEF_OP_MATH(float32, F32, floor);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F32_TRUNC):
DEF_OP_MATH(float32, F32, trunc);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F32_NEAREST):
DEF_OP_MATH(float32, F32, rint);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F32_SQRT):
DEF_OP_MATH(float32, F32, sqrt);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F32_ADD):
DEF_OP_NUMERIC(float32, float32, F32, +);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F32_SUB):
DEF_OP_NUMERIC(float32, float32, F32, -);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F32_MUL):
DEF_OP_NUMERIC(float32, float32, F32, *);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F32_DIV):
DEF_OP_NUMERIC(float32, float32, F32, /);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F32_MIN):
{
float32 a, b;
b = POP_F32();
a = POP_F32();
if (isnan(a))
PUSH_F32(a);
else if (isnan(b))
PUSH_F32(b);
else
PUSH_F32(wa_fmin(a, b));
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_F32_MAX):
{
float32 a, b;
b = POP_F32();
a = POP_F32();
if (isnan(a))
PUSH_F32(a);
else if (isnan(b))
PUSH_F32(b);
else
PUSH_F32(wa_fmax(a, b));
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_F32_COPYSIGN):
{
float32 a, b;
b = POP_F32();
a = POP_F32();
PUSH_F32(signbit(b) ? -fabs(a) : fabs(a));
HANDLE_OP_END ();
}
/* numberic instructions of f64 */
HANDLE_OP (WASM_OP_F64_ABS):
DEF_OP_MATH(float64, F64, fabs);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F64_NEG):
{
int64 i64 = GET_I64_FROM_ADDR(frame_sp - 2);
int64 sign_bit = i64 & (((int64)1) << 63);
if (sign_bit)
PUT_I64_TO_ADDR(frame_sp - 2, ((uint64)i64 & ~(((uint64)1) << 63)));
else
PUT_I64_TO_ADDR(frame_sp - 2, ((uint64)i64 | (((uint64)1) << 63)));
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_F64_CEIL):
DEF_OP_MATH(float64, F64, ceil);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F64_FLOOR):
DEF_OP_MATH(float64, F64, floor);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F64_TRUNC):
DEF_OP_MATH(float64, F64, trunc);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F64_NEAREST):
DEF_OP_MATH(float64, F64, rint);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F64_SQRT):
DEF_OP_MATH(float64, F64, sqrt);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F64_ADD):
DEF_OP_NUMERIC_64(float64, float64, F64, +);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F64_SUB):
DEF_OP_NUMERIC_64(float64, float64, F64, -);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F64_MUL):
DEF_OP_NUMERIC_64(float64, float64, F64, *);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F64_DIV):
DEF_OP_NUMERIC_64(float64, float64, F64, /);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F64_MIN):
{
float64 a, b;
b = POP_F64();
a = POP_F64();
if (isnan(a))
PUSH_F64(a);
else if (isnan(b))
PUSH_F64(b);
else
PUSH_F64(wa_fmin(a, b));
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_F64_MAX):
{
float64 a, b;
b = POP_F64();
a = POP_F64();
if (isnan(a))
PUSH_F64(a);
else if (isnan(b))
PUSH_F64(b);
else
PUSH_F64(wa_fmax(a, b));
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_F64_COPYSIGN):
{
float64 a, b;
b = POP_F64();
a = POP_F64();
PUSH_F64(signbit(b) ? -fabs(a) : fabs(a));
HANDLE_OP_END ();
}
/* conversions of i32 */
HANDLE_OP (WASM_OP_I32_WRAP_I64):
{
int32 value = (int32)(POP_I64() & 0xFFFFFFFFLL);
PUSH_I32(value);
HANDLE_OP_END ();
}
HANDLE_OP (WASM_OP_I32_TRUNC_S_F32):
/* We don't use INT32_MIN/INT32_MAX/UINT32_MIN/UINT32_MAX,
since float/double values of ieee754 cannot precisely represent
all int32/uint32/int64/uint64 values, e.g.:
UINT32_MAX is 4294967295, but (float32)4294967295 is 4294967296.0f,
but not 4294967295.0f. */
DEF_OP_TRUNC_F32(-2147483904.0f, 2147483648.0f, true, true);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I32_TRUNC_U_F32):
DEF_OP_TRUNC_F32(-1.0f, 4294967296.0f, true, false);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I32_TRUNC_S_F64):
DEF_OP_TRUNC_F64(-2147483649.0, 2147483648.0, true, true);
/* frame_sp can't be moved in trunc function, we need to manually adjust
it if src and dst op's cell num is different */
frame_sp--;
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I32_TRUNC_U_F64):
DEF_OP_TRUNC_F64(-1.0, 4294967296.0, true, false);
frame_sp--;
HANDLE_OP_END ();
/* conversions of i64 */
HANDLE_OP (WASM_OP_I64_EXTEND_S_I32):
DEF_OP_CONVERT(int64, I64, int32, I32);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I64_EXTEND_U_I32):
DEF_OP_CONVERT(int64, I64, uint32, I32);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I64_TRUNC_S_F32):
DEF_OP_TRUNC_F32(-9223373136366403584.0f, 9223372036854775808.0f,
false, true);
frame_sp++;
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I64_TRUNC_U_F32):
DEF_OP_TRUNC_F32(-1.0f, 18446744073709551616.0f,
false, false);
frame_sp++;
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I64_TRUNC_S_F64):
DEF_OP_TRUNC_F64(-9223372036854777856.0, 9223372036854775808.0,
false, true);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I64_TRUNC_U_F64):
DEF_OP_TRUNC_F64(-1.0, 18446744073709551616.0,
false, false);
HANDLE_OP_END ();
/* conversions of f32 */
HANDLE_OP (WASM_OP_F32_CONVERT_S_I32):
DEF_OP_CONVERT(float32, F32, int32, I32);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F32_CONVERT_U_I32):
DEF_OP_CONVERT(float32, F32, uint32, I32);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F32_CONVERT_S_I64):
DEF_OP_CONVERT(float32, F32, int64, I64);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F32_CONVERT_U_I64):
DEF_OP_CONVERT(float32, F32, uint64, I64);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F32_DEMOTE_F64):
DEF_OP_CONVERT(float32, F32, float64, F64);
HANDLE_OP_END ();
/* conversions of f64 */
HANDLE_OP (WASM_OP_F64_CONVERT_S_I32):
DEF_OP_CONVERT(float64, F64, int32, I32);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F64_CONVERT_U_I32):
DEF_OP_CONVERT(float64, F64, uint32, I32);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F64_CONVERT_S_I64):
DEF_OP_CONVERT(float64, F64, int64, I64);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F64_CONVERT_U_I64):
DEF_OP_CONVERT(float64, F64, uint64, I64);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_F64_PROMOTE_F32):
DEF_OP_CONVERT(float64, F64, float32, F32);
HANDLE_OP_END ();
/* reinterpretations */
HANDLE_OP (WASM_OP_I32_REINTERPRET_F32):
HANDLE_OP (WASM_OP_I64_REINTERPRET_F64):
HANDLE_OP (WASM_OP_F32_REINTERPRET_I32):
HANDLE_OP (WASM_OP_F64_REINTERPRET_I64):
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I32_EXTEND8_S):
DEF_OP_CONVERT(int32, I32, int8, I32);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I32_EXTEND16_S):
DEF_OP_CONVERT(int32, I32, int16, I32);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I64_EXTEND8_S):
DEF_OP_CONVERT(int64, I64, int8, I64);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I64_EXTEND16_S):
DEF_OP_CONVERT(int64, I64, int16, I64);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_I64_EXTEND32_S):
DEF_OP_CONVERT(int64, I64, int32, I64);
HANDLE_OP_END ();
HANDLE_OP (WASM_OP_MISC_PREFIX):
{
uint32 opcode1;
read_leb_uint32(frame_ip, frame_ip_end, opcode1);
opcode = (uint8)opcode1;
switch (opcode) {
case WASM_OP_I32_TRUNC_SAT_S_F32:
DEF_OP_TRUNC_SAT_F32(-2147483904.0f, 2147483648.0f,
true, true);
break;
case WASM_OP_I32_TRUNC_SAT_U_F32:
DEF_OP_TRUNC_SAT_F32(-1.0f, 4294967296.0f,
true, false);
break;
case WASM_OP_I32_TRUNC_SAT_S_F64:
DEF_OP_TRUNC_SAT_F64(-2147483649.0, 2147483648.0,
true, true);
frame_sp--;
break;
case WASM_OP_I32_TRUNC_SAT_U_F64:
DEF_OP_TRUNC_SAT_F64(-1.0, 4294967296.0,
true, false);
frame_sp--;
break;
case WASM_OP_I64_TRUNC_SAT_S_F32:
DEF_OP_TRUNC_SAT_F32(-9223373136366403584.0f, 9223372036854775808.0f,
false, true);
frame_sp++;
break;
case WASM_OP_I64_TRUNC_SAT_U_F32:
DEF_OP_TRUNC_SAT_F32(-1.0f, 18446744073709551616.0f,
false, false);
frame_sp++;
break;
case WASM_OP_I64_TRUNC_SAT_S_F64:
DEF_OP_TRUNC_SAT_F64(-9223372036854777856.0, 9223372036854775808.0,
false, true);
break;
case WASM_OP_I64_TRUNC_SAT_U_F64:
DEF_OP_TRUNC_SAT_F64(-1.0f, 18446744073709551616.0,
false, false);
break;
#if WASM_ENABLE_BULK_MEMORY != 0
case WASM_OP_MEMORY_INIT:
{
uint32 addr, segment;
uint64 bytes, offset, seg_len;
uint8* data;
read_leb_uint32(frame_ip, frame_ip_end, segment);
/* skip memory index */
frame_ip++;
bytes = (uint64)(uint32)POP_I32();
offset = (uint64)(uint32)POP_I32();
addr = (uint32)POP_I32();
CHECK_BULK_MEMORY_OVERFLOW(addr, bytes, maddr);
seg_len = (uint64)module->module->data_segments[segment]->data_length;
data = module->module->data_segments[segment]->data;
if (offset + bytes > seg_len)
goto out_of_bounds;
bh_memcpy_s(maddr, linear_mem_size - addr,
data + offset, bytes);
break;
}
case WASM_OP_DATA_DROP:
{
uint32 segment;
read_leb_uint32(frame_ip, frame_ip_end, segment);
module->module->data_segments[segment]->data_length = 0;
break;
}
case WASM_OP_MEMORY_COPY:
{
uint32 dst, src, len;
uint8 *mdst, *msrc;
frame_ip += 2;
len = POP_I32();
src = POP_I32();
dst = POP_I32();
CHECK_BULK_MEMORY_OVERFLOW(src, len, msrc);
CHECK_BULK_MEMORY_OVERFLOW(dst, len, mdst);
/* allowing the destination and source to overlap */
bh_memmove_s(mdst, linear_mem_size - dst,
msrc, len);
break;
}
case WASM_OP_MEMORY_FILL:
{
uint32 dst, len;
uint8 val, *mdst;
frame_ip++;
len = POP_I32();
val = POP_I32();
dst = POP_I32();
CHECK_BULK_MEMORY_OVERFLOW(dst, len, mdst);
memset(mdst, val, len);
break;
}
#endif /* WASM_ENABLE_BULK_MEMORY */
#if WASM_ENABLE_REF_TYPES != 0
case WASM_OP_TABLE_INIT:
{
uint32 tbl_idx, elem_idx;
uint64 n, s, d;
WASMTableInstance *tbl_inst;
read_leb_uint32(frame_ip, frame_ip_end, elem_idx);
bh_assert(elem_idx < module->module->table_seg_count);
read_leb_uint32(frame_ip, frame_ip_end, tbl_idx);
bh_assert(tbl_idx < module->module->table_count);
tbl_inst = wasm_get_table_inst(module, tbl_idx);
n = (uint32)POP_I32();
s = (uint32)POP_I32();
d = (uint32)POP_I32();
/* TODO: what if the element is not passive? */
if (!n) {
break;
}
if (n + s > module->module->table_segments[elem_idx].function_count
|| d + n > tbl_inst->cur_size) {
wasm_set_exception(module, "out of bounds table access");
goto got_exception;
}
if (module->module->table_segments[elem_idx].is_dropped) {
wasm_set_exception(module, "out of bounds table access");
goto got_exception;
}
if (!wasm_elem_is_passive(
module->module->table_segments[elem_idx].mode)) {
wasm_set_exception(module, "out of bounds table access");
goto got_exception;
}
bh_memcpy_s(
(uint8 *)(tbl_inst)
+ offsetof(WASMTableInstance, base_addr) + d * sizeof(uint32),
(tbl_inst->cur_size - d) * sizeof(uint32),
module->module->table_segments[elem_idx].func_indexes + s,
n * sizeof(uint32));
break;
}
case WASM_OP_ELEM_DROP:
{
uint32 elem_idx;
read_leb_uint32(frame_ip, frame_ip_end, elem_idx);
bh_assert(elem_idx < module->module->table_seg_count);
module->module->table_segments[elem_idx].is_dropped = true;
break;
}
case WASM_OP_TABLE_COPY:
{
uint32 src_tbl_idx, dst_tbl_idx;
uint64 n, s, d;
WASMTableInstance *src_tbl_inst, *dst_tbl_inst;
read_leb_uint32(frame_ip, frame_ip_end, dst_tbl_idx);
bh_assert(dst_tbl_idx < module->table_count);
dst_tbl_inst = wasm_get_table_inst(module, dst_tbl_idx);
read_leb_uint32(frame_ip, frame_ip_end, src_tbl_idx);
bh_assert(src_tbl_idx < module->table_count);
src_tbl_inst = wasm_get_table_inst(module, src_tbl_idx);
n = (uint32)POP_I32();
s = (uint32)POP_I32();
d = (uint32)POP_I32();
if (s + n > dst_tbl_inst->cur_size
|| d + n > src_tbl_inst->cur_size) {
wasm_set_exception(module, "out of bounds table access");
goto got_exception;
}
/* if s >= d, copy from front to back */
/* if s < d, copy from back to front */
/* merge all together */
bh_memcpy_s(
(uint8 *)(dst_tbl_inst) + offsetof(WASMTableInstance, base_addr)
+ d * sizeof(uint32),
(dst_tbl_inst->cur_size - d) * sizeof(uint32),
(uint8 *)(src_tbl_inst) + offsetof(WASMTableInstance, base_addr)
+ s * sizeof(uint32),
n * sizeof(uint32));
break;
}
case WASM_OP_TABLE_GROW:
{
uint32 tbl_idx, n, init_val, orig_tbl_sz;
WASMTableInstance *tbl_inst;
read_leb_uint32(frame_ip, frame_ip_end, tbl_idx);
bh_assert(tbl_idx < module->table_count);
tbl_inst = wasm_get_table_inst(module, tbl_idx);
orig_tbl_sz = tbl_inst->cur_size;
n = POP_I32();
init_val = POP_I32();
if (!wasm_enlarge_table(module, tbl_idx, n, init_val)) {
PUSH_I32(-1);
}
else {
PUSH_I32(orig_tbl_sz);
}
break;
}
case WASM_OP_TABLE_SIZE:
{
uint32 tbl_idx;
WASMTableInstance *tbl_inst;
read_leb_uint32(frame_ip, frame_ip_end, tbl_idx);
bh_assert(tbl_idx < module->table_count);
tbl_inst = wasm_get_table_inst(module, tbl_idx);
PUSH_I32(tbl_inst->cur_size);
break;
}
case WASM_OP_TABLE_FILL:
{
uint32 tbl_idx, n, val, i;
WASMTableInstance *tbl_inst;
read_leb_uint32(frame_ip, frame_ip_end, tbl_idx);
bh_assert(tbl_idx < module->table_count);
tbl_inst = wasm_get_table_inst(module, tbl_idx);
n = POP_I32();
val = POP_I32();
i = POP_I32();
/* TODO: what if the element is not passive? */
/* TODO: what if the element is dropped? */
if (i + n > tbl_inst->cur_size) {
/* TODO: verify warning content */
wasm_set_exception(module, "out of bounds table access");
goto got_exception;
}
for (; n != 0; i++, n--) {
((uint32 *)(tbl_inst->base_addr))[i] = val;
}
break;
}
#endif /* WASM_ENABLE_REF_TYPES */
default:
wasm_set_exception(module, "unsupported opcode");
goto got_exception;
}
HANDLE_OP_END ();
}
#if WASM_ENABLE_SHARED_MEMORY != 0
HANDLE_OP (WASM_OP_ATOMIC_PREFIX):
{
uint32 offset, align, addr;
opcode = *frame_ip++;
read_leb_uint32(frame_ip, frame_ip_end, align);
read_leb_uint32(frame_ip, frame_ip_end, offset);
switch (opcode) {
case WASM_OP_ATOMIC_NOTIFY:
{
uint32 count, ret;
count = POP_I32();
addr = POP_I32();
CHECK_BULK_MEMORY_OVERFLOW(addr + offset, 4, maddr);
CHECK_ATOMIC_MEMORY_ACCESS();
ret = wasm_runtime_atomic_notify((WASMModuleInstanceCommon*)module,
maddr, count);
bh_assert((int32)ret >= 0);
PUSH_I32(ret);
break;
}
case WASM_OP_ATOMIC_WAIT32:
{
uint64 timeout;
uint32 expect, addr, ret;
timeout = POP_I64();
expect = POP_I32();
addr = POP_I32();
CHECK_BULK_MEMORY_OVERFLOW(addr + offset, 4, maddr);
CHECK_ATOMIC_MEMORY_ACCESS();
ret = wasm_runtime_atomic_wait((WASMModuleInstanceCommon*)module, maddr,
(uint64)expect, timeout, false);
if (ret == (uint32)-1)
goto got_exception;
PUSH_I32(ret);
break;
}
case WASM_OP_ATOMIC_WAIT64:
{
uint64 timeout, expect;
uint32 ret;
timeout = POP_I64();
expect = POP_I64();
addr = POP_I32();
CHECK_BULK_MEMORY_OVERFLOW(addr + offset, 8, maddr);
CHECK_ATOMIC_MEMORY_ACCESS();
ret = wasm_runtime_atomic_wait((WASMModuleInstanceCommon*)module,
maddr, expect, timeout, true);
if (ret == (uint32)-1)
goto got_exception;
PUSH_I32(ret);
break;
}
case WASM_OP_ATOMIC_I32_LOAD:
case WASM_OP_ATOMIC_I32_LOAD8_U:
case WASM_OP_ATOMIC_I32_LOAD16_U:
{
uint32 readv;
addr = POP_I32();
if (opcode == WASM_OP_ATOMIC_I32_LOAD8_U) {
CHECK_BULK_MEMORY_OVERFLOW(addr + offset, 1, maddr);
CHECK_ATOMIC_MEMORY_ACCESS();
os_mutex_lock(&memory->mem_lock);
readv = (uint32)(*(uint8*)maddr);
os_mutex_unlock(&memory->mem_lock);
}
else if (opcode == WASM_OP_ATOMIC_I32_LOAD16_U) {
CHECK_BULK_MEMORY_OVERFLOW(addr + offset, 2, maddr);
CHECK_ATOMIC_MEMORY_ACCESS();
os_mutex_lock(&memory->mem_lock);
readv = (uint32)LOAD_U16(maddr);
os_mutex_unlock(&memory->mem_lock);
}
else {
CHECK_BULK_MEMORY_OVERFLOW(addr + offset, 4, maddr);
CHECK_ATOMIC_MEMORY_ACCESS();
os_mutex_lock(&memory->mem_lock);
readv = LOAD_I32(maddr);
os_mutex_unlock(&memory->mem_lock);
}
PUSH_I32(readv);
break;
}
case WASM_OP_ATOMIC_I64_LOAD:
case WASM_OP_ATOMIC_I64_LOAD8_U:
case WASM_OP_ATOMIC_I64_LOAD16_U:
case WASM_OP_ATOMIC_I64_LOAD32_U:
{
uint64 readv;
addr = POP_I32();
if (opcode == WASM_OP_ATOMIC_I64_LOAD8_U) {
CHECK_BULK_MEMORY_OVERFLOW(addr + offset, 1, maddr);
CHECK_ATOMIC_MEMORY_ACCESS();
os_mutex_lock(&memory->mem_lock);
readv = (uint64)(*(uint8*)maddr);
os_mutex_unlock(&memory->mem_lock);
}
else if (opcode == WASM_OP_ATOMIC_I64_LOAD16_U) {
CHECK_BULK_MEMORY_OVERFLOW(addr + offset, 2, maddr);
CHECK_ATOMIC_MEMORY_ACCESS();
os_mutex_lock(&memory->mem_lock);
readv = (uint64)LOAD_U16(maddr);
os_mutex_unlock(&memory->mem_lock);
}
else if (opcode == WASM_OP_ATOMIC_I64_LOAD32_U) {
CHECK_BULK_MEMORY_OVERFLOW(addr + offset, 4, maddr);
CHECK_ATOMIC_MEMORY_ACCESS();
os_mutex_lock(&memory->mem_lock);
readv = (uint64)LOAD_U32(maddr);
os_mutex_unlock(&memory->mem_lock);
}
else {
CHECK_BULK_MEMORY_OVERFLOW(addr + offset, 8, maddr);
CHECK_ATOMIC_MEMORY_ACCESS();
os_mutex_lock(&memory->mem_lock);
readv = LOAD_I64(maddr);
os_mutex_unlock(&memory->mem_lock);
}
PUSH_I64(readv);
break;
}
case WASM_OP_ATOMIC_I32_STORE:
case WASM_OP_ATOMIC_I32_STORE8:
case WASM_OP_ATOMIC_I32_STORE16:
{
uint32 sval;
sval = (uint32)POP_I32();
addr = POP_I32();
if (opcode == WASM_OP_ATOMIC_I32_STORE8) {
CHECK_BULK_MEMORY_OVERFLOW(addr + offset, 1, maddr);
CHECK_ATOMIC_MEMORY_ACCESS();
os_mutex_lock(&memory->mem_lock);
*(uint8*)maddr = (uint8)sval;
os_mutex_unlock(&memory->mem_lock);
}
else if (opcode == WASM_OP_ATOMIC_I32_STORE16) {
CHECK_BULK_MEMORY_OVERFLOW(addr + offset, 2, maddr);
CHECK_ATOMIC_MEMORY_ACCESS();
os_mutex_lock(&memory->mem_lock);
STORE_U16(maddr, (uint16)sval);
os_mutex_unlock(&memory->mem_lock);
}
else {
CHECK_BULK_MEMORY_OVERFLOW(addr + offset, 4, maddr);
CHECK_ATOMIC_MEMORY_ACCESS();
os_mutex_lock(&memory->mem_lock);
STORE_U32(maddr, frame_sp[1]);
os_mutex_unlock(&memory->mem_lock);
}
break;
}
case WASM_OP_ATOMIC_I64_STORE:
case WASM_OP_ATOMIC_I64_STORE8:
case WASM_OP_ATOMIC_I64_STORE16:
case WASM_OP_ATOMIC_I64_STORE32:
{
uint64 sval;
sval = (uint64)POP_I64();
addr = POP_I32();
if (opcode == WASM_OP_ATOMIC_I64_STORE8) {
CHECK_BULK_MEMORY_OVERFLOW(addr + offset, 1, maddr);
CHECK_ATOMIC_MEMORY_ACCESS();
os_mutex_lock(&memory->mem_lock);
*(uint8*)maddr = (uint8)sval;
os_mutex_unlock(&memory->mem_lock);
}
else if(opcode == WASM_OP_ATOMIC_I64_STORE16) {
CHECK_BULK_MEMORY_OVERFLOW(addr + offset, 2, maddr);
CHECK_ATOMIC_MEMORY_ACCESS();
os_mutex_lock(&memory->mem_lock);
STORE_U16(maddr, (uint16)sval);
os_mutex_unlock(&memory->mem_lock);
}
else if (opcode == WASM_OP_ATOMIC_I64_STORE32) {
CHECK_BULK_MEMORY_OVERFLOW(addr + offset, 4, maddr);
CHECK_ATOMIC_MEMORY_ACCESS();
os_mutex_lock(&memory->mem_lock);
STORE_U32(maddr, (uint32)sval);
os_mutex_unlock(&memory->mem_lock);
}
else {
CHECK_BULK_MEMORY_OVERFLOW(addr + offset, 8, maddr);
CHECK_ATOMIC_MEMORY_ACCESS();
os_mutex_lock(&memory->mem_lock);
STORE_U32(maddr, frame_sp[1]);
STORE_U32(maddr + 4, frame_sp[2]);
os_mutex_unlock(&memory->mem_lock);
}
break;
}
case WASM_OP_ATOMIC_RMW_I32_CMPXCHG:
case WASM_OP_ATOMIC_RMW_I32_CMPXCHG8_U:
case WASM_OP_ATOMIC_RMW_I32_CMPXCHG16_U:
{
uint32 readv, sval, expect;
sval = POP_I32();
expect = POP_I32();
addr = POP_I32();
if (opcode == WASM_OP_ATOMIC_RMW_I32_CMPXCHG8_U) {
CHECK_BULK_MEMORY_OVERFLOW(addr + offset, 1, maddr);
CHECK_ATOMIC_MEMORY_ACCESS();
os_mutex_lock(&memory->mem_lock);
readv = (uint32)(*(uint8*)maddr);
if (readv == expect)
*(uint8*)maddr = (uint8)(sval);
os_mutex_unlock(&memory->mem_lock);
}
else if (opcode == WASM_OP_ATOMIC_RMW_I32_CMPXCHG16_U) {
CHECK_BULK_MEMORY_OVERFLOW(addr + offset, 2, maddr);
CHECK_ATOMIC_MEMORY_ACCESS();
os_mutex_lock(&memory->mem_lock);
readv = (uint32)LOAD_U16(maddr);
if (readv == expect)
STORE_U16(maddr, (uint16)(sval));
os_mutex_unlock(&memory->mem_lock);
}
else {
CHECK_BULK_MEMORY_OVERFLOW(addr + offset, 4, maddr);
CHECK_ATOMIC_MEMORY_ACCESS();
os_mutex_lock(&memory->mem_lock);
readv = LOAD_I32(maddr);
if (readv == expect)
STORE_U32(maddr, sval);
os_mutex_unlock(&memory->mem_lock);
}
PUSH_I32(readv);
break;
}
case WASM_OP_ATOMIC_RMW_I64_CMPXCHG:
case WASM_OP_ATOMIC_RMW_I64_CMPXCHG8_U:
case WASM_OP_ATOMIC_RMW_I64_CMPXCHG16_U:
case WASM_OP_ATOMIC_RMW_I64_CMPXCHG32_U:
{
uint64 readv, sval, expect;
sval = (uint64)POP_I64();
expect = (uint64)POP_I64();
addr = POP_I32();
if (opcode == WASM_OP_ATOMIC_RMW_I64_CMPXCHG8_U) {
CHECK_BULK_MEMORY_OVERFLOW(addr + offset, 1, maddr);
CHECK_ATOMIC_MEMORY_ACCESS();
os_mutex_lock(&memory->mem_lock);
readv = (uint64)(*(uint8*)maddr);
if (readv == expect)
*(uint8*)maddr = (uint8)(sval);
os_mutex_unlock(&memory->mem_lock);
}
else if (opcode == WASM_OP_ATOMIC_RMW_I64_CMPXCHG16_U) {
CHECK_BULK_MEMORY_OVERFLOW(addr + offset, 2, maddr);
CHECK_ATOMIC_MEMORY_ACCESS();
os_mutex_lock(&memory->mem_lock);
readv = (uint64)LOAD_U16(maddr);
if (readv == expect)
STORE_U16(maddr, (uint16)(sval));
os_mutex_unlock(&memory->mem_lock);
}
else if (opcode == WASM_OP_ATOMIC_RMW_I64_CMPXCHG32_U) {
CHECK_BULK_MEMORY_OVERFLOW(addr + offset, 4, maddr);
CHECK_ATOMIC_MEMORY_ACCESS();
os_mutex_lock(&memory->mem_lock);
readv = (uint64)LOAD_U32(maddr);
if (readv == expect)
STORE_U32(maddr, (uint32)(sval));
os_mutex_unlock(&memory->mem_lock);
}
else {
CHECK_BULK_MEMORY_OVERFLOW(addr + offset, 8, maddr);
CHECK_ATOMIC_MEMORY_ACCESS();
os_mutex_lock(&memory->mem_lock);
readv = (uint64)LOAD_I64(maddr);
if (readv == expect) {
STORE_I64(maddr, sval);
}
os_mutex_unlock(&memory->mem_lock);
}
PUSH_I64(readv);
break;
}
DEF_ATOMIC_RMW_OPCODE(ADD, +);
DEF_ATOMIC_RMW_OPCODE(SUB, -);
DEF_ATOMIC_RMW_OPCODE(AND, &);
DEF_ATOMIC_RMW_OPCODE(OR, |);
DEF_ATOMIC_RMW_OPCODE(XOR, ^);
/* xchg, ignore the read value, and store the given value:
readv * 0 + sval */
DEF_ATOMIC_RMW_OPCODE(XCHG, *0 +);
}
HANDLE_OP_END ();
}
#endif
HANDLE_OP (WASM_OP_IMPDEP):
frame = prev_frame;
frame_ip = frame->ip;
frame_sp = frame->sp;
frame_csp = frame->csp;
goto call_func_from_entry;
#if WASM_ENABLE_LABELS_AS_VALUES == 0
default:
wasm_set_exception(module, "unsupported opcode");
goto got_exception;
}
#endif
#if WASM_ENABLE_LABELS_AS_VALUES != 0
HANDLE_OP (WASM_OP_UNUSED_0x06):
HANDLE_OP (WASM_OP_UNUSED_0x07):
HANDLE_OP (WASM_OP_UNUSED_0x08):
HANDLE_OP (WASM_OP_UNUSED_0x09):
HANDLE_OP (WASM_OP_UNUSED_0x0a):
#if WASM_ENABLE_TAIL_CALL == 0
HANDLE_OP (WASM_OP_RETURN_CALL):
HANDLE_OP (WASM_OP_RETURN_CALL_INDIRECT):
#endif
#if WASM_ENABLE_SHARED_MEMORY == 0
HANDLE_OP (WASM_OP_ATOMIC_PREFIX):
#endif
#if WASM_ENABLE_REF_TYPES == 0
HANDLE_OP (WASM_OP_SELECT_T):
HANDLE_OP (WASM_OP_TABLE_GET):
HANDLE_OP (WASM_OP_TABLE_SET):
HANDLE_OP (WASM_OP_REF_NULL):
HANDLE_OP (WASM_OP_REF_IS_NULL):
HANDLE_OP (WASM_OP_REF_FUNC):
#endif
HANDLE_OP (WASM_OP_UNUSED_0x14):
HANDLE_OP (WASM_OP_UNUSED_0x15):
HANDLE_OP (WASM_OP_UNUSED_0x16):
HANDLE_OP (WASM_OP_UNUSED_0x17):
HANDLE_OP (WASM_OP_UNUSED_0x18):
HANDLE_OP (WASM_OP_UNUSED_0x19):
HANDLE_OP (WASM_OP_UNUSED_0x27):
/* Used by fast interpreter */
HANDLE_OP (EXT_OP_SET_LOCAL_FAST_I64):
HANDLE_OP (EXT_OP_TEE_LOCAL_FAST_I64):
HANDLE_OP (EXT_OP_COPY_STACK_TOP):
HANDLE_OP (EXT_OP_COPY_STACK_TOP_I64):
HANDLE_OP (EXT_OP_COPY_STACK_VALUES):
{
wasm_set_exception(module, "unsupported opcode");
goto got_exception;
}
#endif
#if WASM_ENABLE_LABELS_AS_VALUES == 0
continue;
#else
FETCH_OPCODE_AND_DISPATCH ();
#endif
#if WASM_ENABLE_TAIL_CALL != 0
call_func_from_return_call:
POP(cur_func->param_cell_num);
word_copy(frame->lp, frame_sp, cur_func->param_cell_num);
FREE_FRAME(exec_env, frame);
wasm_exec_env_set_cur_frame(exec_env,
(WASMRuntimeFrame *)prev_frame);
goto call_func_from_entry;
#endif
call_func_from_interp:
/* Only do the copy when it's called from interpreter. */
{
WASMInterpFrame *outs_area = wasm_exec_env_wasm_stack_top(exec_env);
POP(cur_func->param_cell_num);
SYNC_ALL_TO_FRAME();
word_copy(outs_area->lp, frame_sp, cur_func->param_cell_num);
prev_frame = frame;
}
call_func_from_entry:
{
if (cur_func->is_import_func) {
#if WASM_ENABLE_MULTI_MODULE != 0
if (cur_func->import_func_inst) {
wasm_interp_call_func_import(module, exec_env, cur_func,
prev_frame);
}
else
#endif
{
wasm_interp_call_func_native(module, exec_env, cur_func,
prev_frame);
}
prev_frame = frame->prev_frame;
cur_func = frame->function;
UPDATE_ALL_FROM_FRAME();
/* update memory instance ptr and memory size */
memory = module->default_memory;
if (memory)
linear_mem_size = num_bytes_per_page * memory->cur_page_count;
if (wasm_get_exception(module))
goto got_exception;
}
else {
WASMFunction *cur_wasm_func = cur_func->u.func;
WASMType *func_type;
func_type = cur_wasm_func->func_type;
all_cell_num = (uint64)cur_func->param_cell_num
+ (uint64)cur_func->local_cell_num
+ (uint64)cur_wasm_func->max_stack_cell_num
+ ((uint64)cur_wasm_func->max_block_num) * sizeof(WASMBranchBlock) / 4;
if (all_cell_num >= UINT32_MAX) {
wasm_set_exception(module, "wasm operand stack overflow");
goto got_exception;
}
frame_size = wasm_interp_interp_frame_size((uint32)all_cell_num);
if (!(frame = ALLOC_FRAME(exec_env, frame_size, prev_frame))) {
frame = prev_frame;
goto got_exception;
}
/* Initialize the interpreter context. */
frame->function = cur_func;
frame_ip = wasm_get_func_code(cur_func);
frame_ip_end = wasm_get_func_code_end(cur_func);
frame_lp = frame->lp;
frame_sp = frame->sp_bottom = frame_lp + cur_func->param_cell_num
+ cur_func->local_cell_num;
frame->sp_boundary = frame->sp_bottom + cur_wasm_func->max_stack_cell_num;
frame_csp = frame->csp_bottom = (WASMBranchBlock*)frame->sp_boundary;
frame->csp_boundary = frame->csp_bottom + cur_wasm_func->max_block_num;
/* Initialize the local varialbes */
memset(frame_lp + cur_func->param_cell_num, 0,
(uint32)(cur_func->local_cell_num * 4));
/* Push function block as first block */
cell_num = func_type->ret_cell_num;
PUSH_CSP(LABEL_TYPE_FUNCTION, cell_num, frame_ip_end - 1);
wasm_exec_env_set_cur_frame(exec_env, (WASMRuntimeFrame*)frame);
}
HANDLE_OP_END ();
}
return_func:
{
FREE_FRAME(exec_env, frame);
wasm_exec_env_set_cur_frame(exec_env, (WASMRuntimeFrame*)prev_frame);
if (!prev_frame->ip)
/* Called from native. */
return;
RECOVER_CONTEXT(prev_frame);
HANDLE_OP_END ();
}
#if WASM_ENABLE_SHARED_MEMORY != 0
unaligned_atomic:
wasm_set_exception(module, "unaligned atomic");
goto got_exception;
#endif
out_of_bounds:
wasm_set_exception(module, "out of bounds memory access");
got_exception:
return;
#if WASM_ENABLE_LABELS_AS_VALUES == 0
}
#else
FETCH_OPCODE_AND_DISPATCH ();
#endif
}The instantiation can be divided to two types: Interpreter and AOT. They are instantiated by different functions:
WASMModuleInstanceCommon *
wasm_runtime_instantiate_internal(WASMModuleCommon *module, bool is_sub_inst,
uint32 stack_size, uint32 heap_size,
char *error_buf, uint32 error_buf_size)
{
#if WASM_ENABLE_INTERP != 0
if (module->module_type == Wasm_Module_Bytecode)
return (WASMModuleInstanceCommon*)
wasm_instantiate((WASMModule*)module, is_sub_inst,
stack_size, heap_size,
error_buf, error_buf_size);
#endif
#if WASM_ENABLE_AOT != 0
if (module->module_type == Wasm_Module_AoT)
return (WASMModuleInstanceCommon*)
aot_instantiate((AOTModule*)module, is_sub_inst,
stack_size, heap_size,
error_buf, error_buf_size);
#endif
set_error_buf(error_buf, error_buf_size,
"Instantiate module failed, invalid module type");
return NULL;
}wasm_instantiate
The instantiation includes a lot of memory checks. E.g. the segments is in the loader and there offset/offset+length are within the region (not exceeds its predetermined sizes)
- Instantiate the globals
- Instantiate memory/table/function count (import + module)
- Instantiate memory/table/function
- Initialize the global data
- Check if the functions/globals are linked correctly
check_linked_symbol - Initialize the memory data with data segment section
- Initialize the table data with table segment section, may also lookup globles to find related type info
- Initialize the thread related data: stack size, MM fnctions, WASI, etc.
WASMModuleInstance*
wasm_instantiate(WASMModule *module, bool is_sub_inst,
uint32 stack_size, uint32 heap_size,
char *error_buf, uint32 error_buf_size)
{
WASMModuleInstance *module_inst;
WASMGlobalInstance *globals = NULL, *global;
uint32 global_count, global_data_size = 0, i;
uint32 base_offset, length;
uint8 *global_data, *global_data_end;
#if WASM_ENABLE_MULTI_MODULE != 0
bool ret = false;
#endif
if (!module)
return NULL;
/* Check heap size */
heap_size = align_uint(heap_size, 8);
if (heap_size > APP_HEAP_SIZE_MAX)
heap_size = APP_HEAP_SIZE_MAX;
/* Allocate the memory */
if (!(module_inst = runtime_malloc(sizeof(WASMModuleInstance),
error_buf, error_buf_size))) {
return NULL;
}
module_inst->module = module;
#if WASM_ENABLE_MULTI_MODULE != 0
module_inst->sub_module_inst_list =
&module_inst->sub_module_inst_list_head;
ret = sub_module_instantiate(module, module_inst, stack_size, heap_size,
error_buf, error_buf_size);
if (!ret) {
LOG_DEBUG("build a sub module list failed");
goto fail;
}
#endif
/* Instantiate global firstly to get the mutable data size */
global_count = module->import_global_count + module->global_count;
if (global_count
&& !(globals = globals_instantiate(module, module_inst,
&global_data_size,
error_buf, error_buf_size))) {
goto fail;
}
module_inst->global_count = global_count;
module_inst->globals = globals;
module_inst->memory_count =
module->import_memory_count + module->memory_count;
module_inst->table_count =
module->import_table_count + module->table_count;
module_inst->function_count =
module->import_function_count + module->function_count;
/* export */
module_inst->export_func_count = get_export_count(module, EXPORT_KIND_FUNC);
#if WASM_ENABLE_MULTI_MODULE != 0
module_inst->export_tab_count = get_export_count(module, EXPORT_KIND_TABLE);
module_inst->export_mem_count = get_export_count(module, EXPORT_KIND_MEMORY);
module_inst->export_glob_count = get_export_count(module, EXPORT_KIND_GLOBAL);
#endif
if (global_count > 0) {
if (!(module_inst->global_data = runtime_malloc
(global_data_size, error_buf, error_buf_size))) {
goto fail;
}
}
/* Instantiate memories/tables/functions */
if ((module_inst->memory_count > 0
&& !(module_inst->memories =
memories_instantiate(module,
module_inst,
heap_size, error_buf, error_buf_size)))
|| (module_inst->table_count > 0
&& !(module_inst->tables =
tables_instantiate(module,
module_inst,
error_buf, error_buf_size)))
|| (module_inst->function_count > 0
&& !(module_inst->functions =
functions_instantiate(module,
module_inst,
error_buf, error_buf_size)))
|| (module_inst->export_func_count > 0
&& !(module_inst->export_functions = export_functions_instantiate(
module, module_inst, module_inst->export_func_count,
error_buf, error_buf_size)))
#if WASM_ENABLE_MULTI_MODULE != 0
|| (module_inst->export_glob_count > 0
&& !(module_inst->export_globals = export_globals_instantiate(
module, module_inst, module_inst->export_glob_count,
error_buf, error_buf_size)))
#endif
) {
goto fail;
}
if (global_count > 0) {
/* Initialize the global data */
global_data = module_inst->global_data;
global_data_end = global_data + global_data_size;
global = globals;
for (i = 0; i < global_count; i++, global++) {
switch (global->type) {
case VALUE_TYPE_I32:
case VALUE_TYPE_F32:
#if WASM_ENABLE_REF_TYPES != 0
case VALUE_TYPE_FUNCREF:
case VALUE_TYPE_EXTERNREF:
#endif
*(int32*)global_data = global->initial_value.i32;
global_data += sizeof(int32);
break;
case VALUE_TYPE_I64:
case VALUE_TYPE_F64:
bh_memcpy_s(global_data, (uint32)(global_data_end - global_data),
&global->initial_value.i64, sizeof(int64));
global_data += sizeof(int64);
break;
default:
bh_assert(0);
}
}
bh_assert(global_data == global_data_end);
}
if (!check_linked_symbol(module_inst, error_buf, error_buf_size)) {
goto fail;
}
/* Initialize the memory data with data segment section */
module_inst->default_memory =
module_inst->memory_count ? module_inst->memories[0] : NULL;
for (i = 0; i < module->data_seg_count; i++) {
WASMMemoryInstance *memory = NULL;
uint8 *memory_data = NULL;
uint32 memory_size = 0;
WASMDataSeg *data_seg = module->data_segments[i];
#if WASM_ENABLE_BULK_MEMORY != 0
if (data_seg->is_passive)
continue;
#endif
/* has check it in loader */
memory = module_inst->memories[data_seg->memory_index];
bh_assert(memory);
memory_data = memory->memory_data;
memory_size = memory->num_bytes_per_page * memory->cur_page_count;
bh_assert(memory_data || memory_size == 0);
bh_assert(data_seg->base_offset.init_expr_type
== INIT_EXPR_TYPE_I32_CONST
|| data_seg->base_offset.init_expr_type
== INIT_EXPR_TYPE_GET_GLOBAL);
if (data_seg->base_offset.init_expr_type
== INIT_EXPR_TYPE_GET_GLOBAL) {
if (!check_global_init_expr(module,
data_seg->base_offset.u.global_index,
error_buf, error_buf_size)) {
goto fail;
}
if (!globals
|| globals[data_seg->base_offset.u.global_index].type
!= VALUE_TYPE_I32) {
set_error_buf(error_buf, error_buf_size,
"data segment does not fit");
goto fail;
}
data_seg->base_offset.u.i32 =
globals[data_seg->base_offset.u.global_index]
.initial_value.i32;
}
/* check offset */
base_offset = (uint32)data_seg->base_offset.u.i32;
if (base_offset > memory_size) {
LOG_DEBUG("base_offset(%d) > memory_size(%d)", base_offset,
memory_size);
#if WASM_ENABLE_REF_TYPES != 0
set_error_buf(error_buf, error_buf_size,
"out of bounds memory access");
#else
set_error_buf(error_buf, error_buf_size,
"data segment does not fit");
#endif
goto fail;
}
/* check offset + length(could be zero) */
length = data_seg->data_length;
if (base_offset + length > memory_size) {
LOG_DEBUG("base_offset(%d) + length(%d) > memory_size(%d)",
base_offset, length, memory_size);
#if WASM_ENABLE_REF_TYPES != 0
set_error_buf(error_buf, error_buf_size,
"out of bounds memory access");
#else
set_error_buf(error_buf, error_buf_size,
"data segment does not fit");
#endif
goto fail;
}
if (memory_data) {
bh_memcpy_s(memory_data + base_offset, memory_size - base_offset,
data_seg->data, length);
}
}
/* Initialize the table data with table segment section */
module_inst->default_table =
module_inst->table_count ? module_inst->tables[0] : NULL;
/* in case there is no table */
for (i = 0; module_inst->table_count > 0 && i < module->table_seg_count;
i++) {
WASMTableSeg *table_seg = module->table_segments + i;
/* has check it in loader */
WASMTableInstance *table = module_inst->tables[table_seg->table_index];
bh_assert(table);
#if WASM_ENABLE_REF_TYPES != 0
if (table->elem_type != VALUE_TYPE_FUNCREF
&& table->elem_type != VALUE_TYPE_EXTERNREF) {
set_error_buf(error_buf, error_buf_size,
"elements segment does not fit");
goto fail;
}
#endif
uint32 *table_data = (uint32 *)table->base_addr;
#if WASM_ENABLE_MULTI_MODULE != 0
table_data = table->table_inst_linked
? (uint32 *)table->table_inst_linked->base_addr
: table_data;
#endif
bh_assert(table_data);
#if WASM_ENABLE_REF_TYPES != 0
if (!wasm_elem_is_active(table_seg->mode))
continue;
#endif
/* init vec(funcidx) or vec(expr) */
bh_assert(
table_seg->base_offset.init_expr_type == INIT_EXPR_TYPE_I32_CONST
|| table_seg->base_offset.init_expr_type == INIT_EXPR_TYPE_GET_GLOBAL
#if WASM_ENABLE_REF_TYPES != 0
|| table_seg->base_offset.init_expr_type == INIT_EXPR_TYPE_FUNCREF_CONST
|| table_seg->base_offset.init_expr_type == INIT_EXPR_TYPE_REFNULL_CONST
#endif
);
if (table_seg->base_offset.init_expr_type
== INIT_EXPR_TYPE_GET_GLOBAL) {
if (!check_global_init_expr(module,
table_seg->base_offset.u.global_index,
error_buf, error_buf_size)) {
goto fail;
}
if (!globals
|| globals[table_seg->base_offset.u.global_index].type
!= VALUE_TYPE_I32) {
set_error_buf(error_buf, error_buf_size,
"elements segment does not fit");
goto fail;
}
table_seg->base_offset.u.i32 =
globals[table_seg->base_offset.u.global_index].initial_value.i32;
}
/* check offset since length might negative */
if ((uint32)table_seg->base_offset.u.i32 > table->cur_size) {
LOG_DEBUG("base_offset(%d) > table->cur_size(%d)",
table_seg->base_offset.u.i32, table->cur_size);
#if WASM_ENABLE_REF_TYPES != 0
set_error_buf(error_buf, error_buf_size,
"out of bounds table access");
#else
set_error_buf(error_buf, error_buf_size,
"elements segment does not fit");
#endif
goto fail;
}
/* check offset + length(could be zero) */
length = table_seg->function_count;
if ((uint32)table_seg->base_offset.u.i32 + length > table->cur_size) {
LOG_DEBUG("base_offset(%d) + length(%d)> table->cur_size(%d)",
table_seg->base_offset.u.i32, length, table->cur_size);
#if WASM_ENABLE_REF_TYPES != 0
set_error_buf(error_buf, error_buf_size,
"out of bounds table access");
#else
set_error_buf(error_buf, error_buf_size,
"elements segment does not fit");
#endif
goto fail;
}
/**
* Check function index in the current module inst for now.
* will check the linked table inst owner in future.
* so loader check is enough
*/
bh_memcpy_s(
table_data + table_seg->base_offset.u.i32,
(uint32)((table->cur_size - (uint32)table_seg->base_offset.u.i32)
* sizeof(uint32)),
table_seg->func_indexes, (uint32)(length * sizeof(uint32)));
}
/* module instance type */
module_inst->module_type = Wasm_Module_Bytecode;
/* Initialize the thread related data */
if (stack_size == 0)
stack_size = DEFAULT_WASM_STACK_SIZE;
#if WASM_ENABLE_SPEC_TEST != 0
if (stack_size < 48 *1024)
stack_size = 48 * 1024;
#endif
module_inst->default_wasm_stack_size = stack_size;
if (module->malloc_function != (uint32)-1) {
module_inst->malloc_function =
&module_inst->functions[module->malloc_function];
}
if (module->free_function != (uint32)-1) {
module_inst->free_function =
&module_inst->functions[module->free_function];
}
if (module->retain_function != (uint32)-1) {
module_inst->retain_function =
&module_inst->functions[module->retain_function];
}
#if WASM_ENABLE_LIBC_WASI != 0
/* The sub-instance will get the wasi_ctx from main-instance */
if (!is_sub_inst) {
if (!wasm_runtime_init_wasi((WASMModuleInstanceCommon*)module_inst,
module->wasi_args.dir_list,
module->wasi_args.dir_count,
module->wasi_args.map_dir_list,
module->wasi_args.map_dir_count,
module->wasi_args.env,
module->wasi_args.env_count,
module->wasi_args.argv,
module->wasi_args.argc,
error_buf, error_buf_size)) {
goto fail;
}
}
#endif
if (module->start_function != (uint32)-1) {
/* TODO: fix start function can be import function issue */
if (module->start_function >= module->import_function_count)
module_inst->start_function =
&module_inst->functions[module->start_function];
}
/* Execute __post_instantiate function */
if (!execute_post_inst_function(module_inst)
|| !execute_start_function(module_inst)) {
set_error_buf(error_buf, error_buf_size,
module_inst->cur_exception);
goto fail;
}
#if WASM_ENABLE_BULK_MEMORY != 0
#if WASM_ENABLE_LIBC_WASI != 0
if (!module->is_wasi_module) {
#endif
/* Only execute the memory init function for main instance because
the data segments will be dropped once initialized.
*/
if (!is_sub_inst) {
if (!execute_memory_init_function(module_inst)) {
set_error_buf(error_buf, error_buf_size,
module_inst->cur_exception);
goto fail;
}
}
#if WASM_ENABLE_LIBC_WASI != 0
}
#endif
#endif
#if WASM_ENABLE_MEMORY_TRACING != 0
wasm_runtime_dump_module_inst_mem_consumption
((WASMModuleInstanceCommon *)module_inst);
#endif
(void)global_data_end;
return module_inst;
fail:
wasm_deinstantiate(module_inst, false);
return NULL;
}Instantiate the globals
struct WASMGlobalInstance {
/* value type, VALUE_TYPE_I32/I64/F32/F64 */
uint8 type;
/* mutable or constant */
bool is_mutable;
/* data offset to base_addr of WASMMemoryInstance */
uint32 data_offset;
/* initial value */
WASMValue initial_value;
#if WASM_ENABLE_MULTI_MODULE != 0
/* just for import, keep the reference here */
WASMModuleInstance *import_module_inst;
WASMGlobalInstance *import_global_inst;
#endif
};Here the imported globals and the globals form the global section will be instantiated differently.
static WASMGlobalInstance *
globals_instantiate(const WASMModule *module,
WASMModuleInstance *module_inst,
uint32 *p_global_data_size, char *error_buf,
uint32 error_buf_size)
{
WASMImport *import;
uint32 global_data_offset = 0;
uint32 i, global_count =
module->import_global_count + module->global_count;
uint64 total_size = sizeof(WASMGlobalInstance) * (uint64)global_count;
WASMGlobalInstance *globals, *global;
if (!(globals = runtime_malloc(total_size,
error_buf, error_buf_size))) {
return NULL;
}
/* instantiate globals from import section */
global = globals;
import = module->import_globals;
for (i = 0; i < module->import_global_count; i++, import++) {
WASMGlobalImport *global_import = &import->u.global;
global->type = global_import->type;
global->is_mutable = global_import->is_mutable;
#if WASM_ENABLE_MULTI_MODULE != 0
if (global_import->import_module) {
if (!(global->import_module_inst = get_sub_module_inst(
module_inst, global_import->import_module))) {
set_error_buf(error_buf, error_buf_size, "unknown global");
return NULL;
}
if (!(global->import_global_inst = wasm_lookup_global(
global->import_module_inst, global_import->field_name))) {
set_error_buf(error_buf, error_buf_size, "unknown global");
return NULL;
}
/* The linked global instance has been initialized, we
just need to copy the value. */
bh_memcpy_s(&(global->initial_value), sizeof(WASMValue),
&(global_import->import_global_linked->init_expr),
sizeof(WASMValue));
}
else
#endif
{
/* native globals share their initial_values in one module */
bh_memcpy_s(&(global->initial_value), sizeof(WASMValue),
&(global_import->global_data_linked),
sizeof(WASMValue));
}
global->data_offset = global_data_offset;
global_data_offset += wasm_value_type_size(global->type);
global++;
}
/* instantiate globals from global section */
for (i = 0; i < module->global_count; i++) {
InitializerExpression *init_expr = &(module->globals[i].init_expr);
global->type = module->globals[i].type;
global->is_mutable = module->globals[i].is_mutable;
global->data_offset = global_data_offset;
global_data_offset += wasm_value_type_size(global->type);
if (init_expr->init_expr_type == INIT_EXPR_TYPE_GET_GLOBAL) {
if (!check_global_init_expr(module, init_expr->u.global_index,
error_buf, error_buf_size)) {
return NULL;
}
bh_memcpy_s(
&(global->initial_value), sizeof(WASMValue),
&(globals[init_expr->u.global_index].initial_value),
sizeof(globals[init_expr->u.global_index].initial_value));
}
#if WASM_ENABLE_REF_TYPES != 0
else if (init_expr->init_expr_type == INIT_EXPR_TYPE_REFNULL_CONST) {
global->initial_value.u32 = (uint32)NULL_REF;
}
#endif
else {
bh_memcpy_s(&(global->initial_value), sizeof(WASMValue),
&(init_expr->u), sizeof(init_expr->u));
}
global++;
}
bh_assert((uint32)(global - globals) == global_count);
*p_global_data_size = global_data_offset;
(void)module_inst;
return globals;
}Memroy
Memory instance struct
What's the memory layout? What's the different between memory and heap?
struct WASMMemoryInstance {
/* Module type */
uint32 module_type;
/* Shared memory flag */
bool is_shared;
/* Number bytes per page */
uint32 num_bytes_per_page;
/* Current page count */
uint32 cur_page_count;
/* Maximum page count */
uint32 max_page_count;
/* Heap data base address */
uint8 *heap_data;
/* Heap data end address */
uint8 *heap_data_end;
/* The heap created */
void *heap_handle;
#if WASM_ENABLE_MULTI_MODULE != 0
/* to indicate which module instance create it */
WASMModuleInstance *owner;
#endif
#if WASM_ENABLE_SHARED_MEMORY != 0
/* mutex lock for the memory, used in atomic operation */
korp_mutex mem_lock;
#endif
/* Memory data end address */
uint8 *memory_data_end;
/* Memory data begin address, the layout is: memory data + heap data
Note: when memory is re-allocated, the heap data and memory data
must be copied to new memory also. */
uint8 *memory_data;
};aot_instantiate
Seems like it's much simpler than the previous instantiation function.
AOTModuleInstance*
aot_instantiate(AOTModule *module, bool is_sub_inst,
uint32 stack_size, uint32 heap_size,
char *error_buf, uint32 error_buf_size)
{
AOTModuleInstance *module_inst;
const uint32 module_inst_struct_size =
offsetof(AOTModuleInstance, global_table_data.bytes);
const uint64 module_inst_mem_inst_size =
(uint64)module->memory_count * sizeof(AOTMemoryInstance);
uint64 total_size, table_size = 0;
uint8 *p;
uint32 i;
/* Check heap size */
heap_size = align_uint(heap_size, 8);
if (heap_size > APP_HEAP_SIZE_MAX)
heap_size = APP_HEAP_SIZE_MAX;
total_size = (uint64)module_inst_struct_size + module_inst_mem_inst_size
+ module->global_data_size;
/*
* calculate size of table data
*/
for (i = 0; i != module->import_table_count; ++i) {
table_size += offsetof(AOTTableInstance, data);
table_size +=
(uint64)sizeof(uint32)
* (uint64)aot_get_imp_tbl_data_slots(module->import_tables + i);
}
for (i = 0; i != module->table_count; ++i) {
table_size += offsetof(AOTTableInstance, data);
table_size += (uint64)sizeof(uint32)
* (uint64)aot_get_tbl_data_slots(module->tables + i);
}
total_size += table_size;
/* Allocate module instance, global data, table data and heap data */
if (!(module_inst = runtime_malloc(total_size,
error_buf, error_buf_size))) {
return NULL;
}
module_inst->module_type = Wasm_Module_AoT;
module_inst->aot_module.ptr = module;
/* Initialize global info */
p = (uint8*)module_inst + module_inst_struct_size +
module_inst_mem_inst_size;
module_inst->global_data.ptr = p;
module_inst->global_data_size = module->global_data_size;
if (!global_instantiate(module_inst, module, error_buf, error_buf_size))
goto fail;
/* Initialize table info */
p += module->global_data_size;
module_inst->tables.ptr = p;
module_inst->table_count =
module->table_count + module->import_table_count;
/* Set all elements to -1 to mark them as uninitialized elements */
memset(module_inst->tables.ptr, 0xff, (uint32)table_size);
if (!table_instantiate(module_inst, module, error_buf, error_buf_size))
goto fail;
/* Initialize memory space */
if (!memories_instantiate(module_inst, module, heap_size,
error_buf, error_buf_size))
goto fail;
/* Initialize function pointers */
if (!init_func_ptrs(module_inst, module, error_buf, error_buf_size))
goto fail;
/* Initialize function type indexes */
if (!init_func_type_indexes(module_inst, module, error_buf, error_buf_size))
goto fail;
if (!create_exports(module_inst, module, error_buf, error_buf_size))
goto fail;
#if WASM_ENABLE_LIBC_WASI != 0
if (!is_sub_inst) {
if (!wasm_runtime_init_wasi((WASMModuleInstanceCommon*)module_inst,
module->wasi_args.dir_list,
module->wasi_args.dir_count,
module->wasi_args.map_dir_list,
module->wasi_args.map_dir_count,
module->wasi_args.env,
module->wasi_args.env_count,
module->wasi_args.argv,
module->wasi_args.argc,
error_buf, error_buf_size))
goto fail;
}
#endif
/* Initialize the thread related data */
if (stack_size == 0)
stack_size = DEFAULT_WASM_STACK_SIZE;
#if WASM_ENABLE_SPEC_TEST != 0
if (stack_size < 48 *1024)
stack_size = 48 * 1024;
#endif
module_inst->default_wasm_stack_size = stack_size;
#if WASM_ENABLE_PERF_PROFILING != 0
total_size = (uint64)sizeof(AOTFuncPerfProfInfo) *
(module->import_func_count + module->func_count);
if (!(module_inst->func_perf_profilings.ptr =
runtime_malloc(total_size, error_buf, error_buf_size))) {
goto fail;
}
#endif
/* Execute __post_instantiate function and start function*/
if (!execute_post_inst_function(module_inst)
|| !execute_start_function(module_inst)) {
set_error_buf(error_buf, error_buf_size,
module_inst->cur_exception);
goto fail;
}
#if WASM_ENABLE_BULK_MEMORY != 0
#if WASM_ENABLE_LIBC_WASI != 0
if (!module->is_wasi_module) {
#endif
/* Only execute the memory init function for main instance because
the data segments will be dropped once initialized.
*/
if (!is_sub_inst) {
if (!execute_memory_init_function(module_inst)) {
set_error_buf(error_buf, error_buf_size,
module_inst->cur_exception);
goto fail;
}
}
#if WASM_ENABLE_LIBC_WASI != 0
}
#endif
#endif
#if WASM_ENABLE_MEMORY_TRACING != 0
wasm_runtime_dump_module_inst_mem_consumption
((WASMModuleInstanceCommon *)module_inst);
#endif
return module_inst;
fail:
aot_deinstantiate(module_inst, is_sub_inst);
return NULL;
}The module loader in the enclave
- Allocate memory for
EnclaveModulestruct and WASM file - Copy memory(WASM file buffer) from application part
static void
handle_cmd_load_module(uint64 *args, uint32 argc)
{
uint64 *args_org = args;
char *wasm_file = *(char **)args++;
uint32 wasm_file_size = *(uint32 *)args++;
char *error_buf = *(char **)args++;
uint32 error_buf_size = *(uint32 *)args++;
uint64 total_size = sizeof(EnclaveModule) + (uint64)wasm_file_size;
EnclaveModule *enclave_module;
bh_assert(argc == 4);
if (total_size >= UINT32_MAX
|| !(enclave_module = (EnclaveModule *)
wasm_runtime_malloc((uint32)total_size))) {
set_error_buf(error_buf, error_buf_size,
"WASM module load failed: "
"allocate memory failed.");
*(void **)args_org = NULL;
return;
}
memset(enclave_module, 0, (uint32)total_size);
enclave_module->wasm_file = (uint8 *)enclave_module
+ sizeof(EnclaveModule);
bh_memcpy_s(enclave_module->wasm_file, wasm_file_size,
wasm_file, wasm_file_size);
if (!(enclave_module->module =
wasm_runtime_load(enclave_module->wasm_file, wasm_file_size,
error_buf, error_buf_size))) {
wasm_runtime_free(enclave_module);
*(void **)args_org = NULL;
return;
}
*(EnclaveModule **)args_org = enclave_module;
LOG_VERBOSE("Load module success.\n");
}And it is indirectly invoked by load_module in the application part.
static void *
load_module(uint8_t *wasm_file_buf, uint32_t wasm_file_size,
char *error_buf, uint32_t error_buf_size)
{
uint64_t ecall_args[4];
ecall_args[0] = (uint64_t)(uintptr_t)wasm_file_buf;
ecall_args[1] = wasm_file_size;
ecall_args[2] = (uint64_t)(uintptr_t)error_buf;
ecall_args[3] = error_buf_size;
if (SGX_SUCCESS != ecall_handle_command(g_eid, CMD_LOAD_MODULE,
(uint8_t *)ecall_args,
sizeof(uint64_t) * 4)) {
printf("Call ecall_handle_command() failed.\n");
return NULL;
}
return (void *)(uintptr_t)ecall_args[0];
}Will call wasm_runtime_load to load a module from buffer.
wasm_runtime_load
- Check if the loaded module is bytecode
- Load the module (depending on
AOT&&JITorINTERP)
WASMModuleCommon *
wasm_runtime_load(const uint8 *buf, uint32 size,
char *error_buf, uint32 error_buf_size)
{
WASMModuleCommon *module_common = NULL;
if (get_package_type(buf, size) == Wasm_Module_Bytecode) {
#if WASM_ENABLE_AOT != 0 && WASM_ENABLE_JIT != 0
AOTModule *aot_module;
WASMModule *module = wasm_load(buf, size, error_buf, error_buf_size);
if (!module)
return NULL;
if (!(aot_module = aot_convert_wasm_module(module,
error_buf, error_buf_size))) {
wasm_unload(module);
return NULL;
}
module_common = (WASMModuleCommon*)aot_module;
return register_module_with_null_name(module_common,
error_buf, error_buf_size);
#elif WASM_ENABLE_INTERP != 0
module_common = (WASMModuleCommon*)
wasm_load(buf, size, error_buf, error_buf_size);
return register_module_with_null_name(module_common,
error_buf, error_buf_size);
#endif
}
else if (get_package_type(buf, size) == Wasm_Module_AoT) {
#if WASM_ENABLE_AOT != 0
module_common = (WASMModuleCommon*)
aot_load_from_aot_file(buf, size, error_buf, error_buf_size);
return register_module_with_null_name(module_common,
error_buf, error_buf_size);
#endif
}
if (size < 4)
set_error_buf(error_buf, error_buf_size,
"WASM module load failed: unexpected end");
else
set_error_buf(error_buf, error_buf_size,
"WASM module load failed: magic header not detected");
return NULL;
}wasm_loader_load
WASMModule*
wasm_loader_load(const uint8 *buf, uint32 size, char *error_buf, uint32 error_buf_size)
{
WASMModule *module = create_module(error_buf, error_buf_size);
if (!module) {
return NULL;
}
if (!load(buf, size, module, error_buf, error_buf_size)) {
goto fail;
}
LOG_VERBOSE("Load module success.\n");
return module;
fail:
wasm_loader_unload(module);
return NULL;
}create_module
Merely create a module struct buffer and init it minimally.
static WASMModule*
create_module(char *error_buf, uint32 error_buf_size)
{
WASMModule *module = loader_malloc(sizeof(WASMModule),
error_buf, error_buf_size);
if (!module) {
return NULL;
}
module->module_type = Wasm_Module_Bytecode;
/* Set start_function to -1, means no start function */
module->start_function = (uint32)-1;
#if WASM_ENABLE_MULTI_MODULE != 0
module->import_module_list = &module->import_module_list_head;
#endif
return module;
}load
- checks buffer is not exhausted every time before consuming it
- Check the magic number
- Check the version info
- Create sections (read from WASM sections)
load_from_sectionsusing the collected section infodestroy_sections: free the section linked list
static bool
load(const uint8 *buf, uint32 size, WASMModule *module,
char *error_buf, uint32 error_buf_size)
{
const uint8 *buf_end = buf + size;
const uint8 *p = buf, *p_end = buf_end;
uint32 magic_number, version;
WASMSection *section_list = NULL;
CHECK_BUF1(p, p_end, sizeof(uint32));
magic_number = read_uint32(p);
if (!is_little_endian())
exchange32((uint8*)&magic_number);
if (magic_number != WASM_MAGIC_NUMBER) {
set_error_buf(error_buf, error_buf_size,
"magic header not detected");
return false;
}
CHECK_BUF1(p, p_end, sizeof(uint32));
version = read_uint32(p);
if (!is_little_endian())
exchange32((uint8*)&version);
if (version != WASM_CURRENT_VERSION) {
set_error_buf(error_buf, error_buf_size,
"unknown binary version");
return false;
}
if (!create_sections(buf, size, §ion_list, error_buf, error_buf_size)
|| !load_from_sections(module, section_list, error_buf, error_buf_size)) {
destroy_sections(section_list);
return false;
}
destroy_sections(section_list);
return true;
fail:
return false;
}create_sections
Inintialize sections: read the section type and length => linked list of WASMSection
/* WASM section */
typedef struct wasm_section_t {
struct wasm_section_t *next;
/* section type */
int section_type;
/* section body, not include type and size */
uint8_t *section_body;
/* section body size */
uint32_t section_body_size;
} wasm_section_t, aot_section_t, *wasm_section_list_t, *aot_section_list_t;static bool
create_sections(const uint8 *buf, uint32 size,
WASMSection **p_section_list,
char *error_buf, uint32 error_buf_size)
{
WASMSection *section_list_end = NULL, *section;
const uint8 *p = buf, *p_end = buf + size/*, *section_body*/;
uint8 section_type, section_index, last_section_index = (uint8)-1;
uint32 section_size;
bh_assert(!*p_section_list);
p += 8;
while (p < p_end) {
CHECK_BUF(p, p_end, 1);
section_type = read_uint8(p);
section_index = get_section_index(section_type);
if (section_index != (uint8)-1) {
if (section_type != SECTION_TYPE_USER) {
/* Custom sections may be inserted at any place,
while other sections must occur at most once
and in prescribed order. */
bh_assert(last_section_index == (uint8)-1
|| last_section_index < section_index);
last_section_index = section_index;
}
CHECK_BUF1(p, p_end, 1);
read_leb_uint32(p, p_end, section_size);
CHECK_BUF1(p, p_end, section_size);
if (!(section = loader_malloc(sizeof(WASMSection),
error_buf, error_buf_size))) {
return false;
}
section->section_type = section_type;
section->section_body = (uint8*)p;
section->section_body_size = section_size;
if (!*p_section_list)
*p_section_list = section_list_end = section;
else {
section_list_end->next = section;
section_list_end = section;
}
p += section_size;
}
else {
bh_assert(0);
}
}
(void)last_section_index;
return true;
}load_from_sections
- Find code and function sections if have
- Iterate each section and extract related information To explore the details
- Resolve auxiliary data/stack/heap info and reset memory info (check exported values from the module)
- Resolve malloc/free function exported by wasm module Support custom
malloc/free? What'sretainfunction? - Iterate through all functions and execute
wasm_loader_prepare_bytecodefor it W - Additional memory initializations if it cannot grow
SGX Environment App Code
Big Picture
- An ecall
ecall_handle_commandto serve incoming commands from the app part - Memory management?
runtime_malloc
void
ecall_handle_command(unsigned cmd,
unsigned char *cmd_buf,
unsigned cmd_buf_size)
{
uint64 *args = (uint64 *)cmd_buf;
uint32 argc = cmd_buf_size / sizeof(uint64);
switch (cmd) {
case CMD_INIT_RUNTIME:
handle_cmd_init_runtime(args, argc);
break;
case CMD_LOAD_MODULE:
handle_cmd_load_module(args, argc);
break;
case CMD_SET_WASI_ARGS:
handle_cmd_set_wasi_args(args, argc);
break;
case CMD_INSTANTIATE_MODULE:
handle_cmd_instantiate_module(args, argc);
break;
case CMD_LOOKUP_FUNCTION:
break;
case CMD_CREATE_EXEC_ENV:
break;
case CMD_CALL_WASM:
break;
case CMD_EXEC_APP_FUNC:
handle_cmd_exec_app_func(args, argc);
break;
case CMD_EXEC_APP_MAIN:
handle_cmd_exec_app_main(args, argc);
break;
case CMD_GET_EXCEPTION:
handle_cmd_get_exception(args, argc);
break;
case CMD_DEINSTANTIATE_MODULE:
handle_cmd_deinstantiate_module(args, argc);
break;
case CMD_UNLOAD_MODULE:
handle_cmd_unload_module(args, argc);
break;
case CMD_DESTROY_RUNTIME:
handle_cmd_destroy_runtime();
break;
case CMD_SET_LOG_LEVEL:
handle_cmd_set_log_level(args, argc);
break;
default:
LOG_ERROR("Unknown command %d\n", cmd);
break;
}
}Initialization Steps
enclave_init- Argument parsing
- WAMR `init_runtime` (in enclave)
- Set log level
- Read in WASM file to a buffer and load it as a module into the enclave
- Instantiate the module
- Execute the main function
- Do cleaning jobs:
wasm_runtime_deinstantiate,wasm_runtime_unloadandwasm_runtime_destroy
int
main(int argc, char *argv[])
{
char *wasm_file = NULL;
const char *func_name = NULL;
uint8_t *wasm_file_buf = NULL;
uint32_t wasm_file_size;
uint32_t stack_size = 16 * 1024, heap_size = 16 * 1024;
void *wasm_module = NULL;
void *wasm_module_inst = NULL;
char error_buf[128] = { 0 };
int log_verbose_level = 2;
bool is_repl_mode = false, alloc_with_pool = false;
const char *dir_list[8] = { NULL };
uint32_t dir_list_size = 0;
const char *env_list[8] = { NULL };
uint32_t env_list_size = 0;
uint32_t max_thread_num = 4;
if (enclave_init(&g_eid) < 0) {
std::cout << "Fail to initialize enclave." << std::endl;
return 1;
}
#if TEST_OCALL_API != 0
{
if (!init_runtime(alloc_with_pool, max_thread_num)) {
return -1;
}
ecall_iwasm_test(g_eid);
destroy_runtime();
return 0;
}
#endif
/* Process options. */
for (argc--, argv++; argc > 0 && argv[0][0] == '-'; argc--, argv++) {
if (!strcmp(argv[0], "-f") || !strcmp(argv[0], "--function")) {
argc--, argv++;
if (argc < 2) {
print_help();
return 0;
}
func_name = argv[0];
}
else if (!strncmp(argv[0], "-v=", 3)) {
log_verbose_level = atoi(argv[0] + 3);
if (log_verbose_level < 0 || log_verbose_level > 5)
return print_help();
}
else if (!strcmp(argv[0], "--repl")) {
is_repl_mode = true;
}
else if (!strncmp(argv[0], "--stack-size=", 13)) {
if (argv[0][13] == '\0')
return print_help();
stack_size = atoi(argv[0] + 13);
}
else if (!strncmp(argv[0], "--heap-size=", 12)) {
if (argv[0][12] == '\0')
return print_help();
heap_size = atoi(argv[0] + 12);
}
else if (!strncmp(argv[0], "--dir=", 6)) {
if (argv[0][6] == '\0')
return print_help();
if (dir_list_size >= sizeof(dir_list) / sizeof(char *)) {
printf("Only allow max dir number %d\n",
(int)(sizeof(dir_list) / sizeof(char *)));
return -1;
}
dir_list[dir_list_size++] = argv[0] + 6;
}
else if (!strncmp(argv[0], "--env=", 6)) {
char *tmp_env;
if (argv[0][6] == '\0')
return print_help();
if (env_list_size >= sizeof(env_list) / sizeof(char *)) {
printf("Only allow max env number %d\n",
(int)(sizeof(env_list) / sizeof(char *)));
return -1;
}
tmp_env = argv[0] + 6;
if (validate_env_str(tmp_env))
env_list[env_list_size++] = tmp_env;
else {
printf("Wasm parse env string failed: expect \"key=value\", "
"got \"%s\"\n",
tmp_env);
return print_help();
}
}
else if (!strncmp(argv[0], "--max-threads=", 14)) {
if (argv[0][14] == '\0')
return print_help();
max_thread_num = atoi(argv[0] + 14);
}
else
return print_help();
}
if (argc == 0)
return print_help();
wasm_file = argv[0];
/* Init runtime */
if (!init_runtime(alloc_with_pool, max_thread_num)) {
return -1;
}
/* Set log verbose level */
if (!set_log_verbose_level(log_verbose_level)) {
goto fail1;
}
/* Load WASM byte buffer from WASM bin file */
if (!(wasm_file_buf =
(uint8_t *)read_file_to_buffer(wasm_file, &wasm_file_size))) {
goto fail1;
}
/* Load module */
if (!(wasm_module = load_module(wasm_file_buf, wasm_file_size,
error_buf, sizeof(error_buf)))) {
printf("%s\n", error_buf);
goto fail2;
}
/* Set wasi arguments */
if (!set_wasi_args(wasm_module, dir_list, dir_list_size,
env_list, env_list_size, argv, argc)) {
printf("%s\n", "set wasi arguments failed.\n");
goto fail3;
}
/* Instantiate module */
if (!(wasm_module_inst = instantiate_module(wasm_module,
stack_size, heap_size,
error_buf,
sizeof(error_buf)))) {
printf("%s\n", error_buf);
goto fail3;
}
if (is_repl_mode)
app_instance_repl(wasm_module_inst, argc, argv);
else if (func_name)
app_instance_func(wasm_module_inst, func_name,
argc - 1, argv + 1);
else
app_instance_main(wasm_module_inst, argc, argv);
/* Deinstantiate module */
deinstantiate_module(wasm_module_inst);
fail3:
/* Unload module */
unload_module(wasm_module);
fail2:
/* Free the file buffer */
free(wasm_file_buf);
fail1:
/* Destroy runtime environment */
destroy_runtime();
return 0;
}Installation
git clone https://github.com/bytecodealliance/wasm-micro-runtime
# use a release version
git checkout WAMR-08-10-2021
# build the WAMR library
# source <SGX_SDK dir>/environment
cd product-mini/platforms/linux-sgx/
mkdir build
cd build
cmake ..
make
# build the executable wamr
cd ../enclave-sample
# please change `SGX_MODE` to `HW` and `SGX_DEBUG=1
make
# here an `iwasm` executable should be generated successfully
# WASI-SDK
cd <path-to-wasi>
wget https://github.com/WebAssembly/wasi-sdk/releases/download/wasi-sdk-12/wasi-sdk-12.0-linux.tar.gz
tar xvf wasi-sdk-12.0-linux.tar.gzToy Example
#include <stdio.h>
int main(int argc, char const *argv[])
{
printf("POC");
return 0;
}# Compile an example C source code
# remember to use the absolute path in `sysroot`!!!! (otherwise NFS problem may occur)
~/wasi-sdk-12.0/bin/clang-11 --sysroot=/<user-home>/wasi-sdk-12.0/share/wasi-sysroot main.c -o main
# Execute
# remember to enlarge heap/stack size and include necessary dirs if needed
./iwasm test/main
···Questions
Mesapy Executor
The executor is compiled into a library and will later be linked with ffi functions from other executor (mesapy).
How does T know where to link extern functions in Rust?
How is the linked mesapy library generated?
Check the makefile of mesapy
Notes
How to compile the WebAssembly
/opt/wasi-sdk/bin/clang -o simple_add.wasm simple_add.c -Wl,--export-all -Wl,--no-entry -nostdlib -Wl,--allow-undefined
The compiled wasm should not linked to stdlib currently, and adding --export-all can help it export functions. Otherwise the function would never be exported.
Modification on source code
Please refer the the Developer Guide and related documents.
WASM Executor
The symbols are a static array of NativeSymbol
typedef struct NativeSymbol {
const char *symbol;
void *func_ptr;
const char *signature;
/* attachment which can be retrieved in native API by
calling wasm_runtime_get_function_attachment(exec_env) */
void *attachment;
} NativeSymbol;wasm_native_init
bool
wasm_native_init()
{
NativeSymbol *native_symbols;
uint32 n_native_symbols;
#if WASM_ENABLE_LIBC_BUILTIN != 0
n_native_symbols = get_libc_builtin_export_apis(&native_symbols);
if (!wasm_native_register_natives("env",
native_symbols, n_native_symbols))
return false;
#endif /* WASM_ENABLE_LIBC_BUILTIN */
#if WASM_ENABLE_SPEC_TEST
n_native_symbols = get_spectest_export_apis(&native_symbols);
if (!wasm_native_register_natives("spectest",
native_symbols, n_native_symbols))
return false;
#endif /* WASM_ENABLE_SPEC_TEST */
#if WASM_ENABLE_LIBC_WASI != 0
n_native_symbols = get_libc_wasi_export_apis(&native_symbols);
if (!wasm_native_register_natives("wasi_unstable",
native_symbols, n_native_symbols))
return false;
if (!wasm_native_register_natives("wasi_snapshot_preview1",
native_symbols, n_native_symbols))
return false;
#endif
#if WASM_ENABLE_BASE_LIB != 0
n_native_symbols = get_base_lib_export_apis(&native_symbols);
if (n_native_symbols > 0
&& !wasm_native_register_natives("env",
native_symbols, n_native_symbols))
return false;
#endif
#if WASM_ENABLE_APP_FRAMEWORK != 0
n_native_symbols = get_ext_lib_export_apis(&native_symbols);
if (n_native_symbols > 0
&& !wasm_native_register_natives("env",
native_symbols, n_native_symbols))
return false;
#endif
#if WASM_ENABLE_LIB_PTHREAD != 0
if (!lib_pthread_init())
return false;
n_native_symbols = get_lib_pthread_export_apis(&native_symbols);
if (n_native_symbols > 0
&& !wasm_native_register_natives("env",
native_symbols, n_native_symbols))
return false;
#endif
#if WASM_ENABLE_LIBC_EMCC != 0
n_native_symbols = get_libc_emcc_export_apis(&native_symbols);
if (n_native_symbols > 0
&& !wasm_native_register_natives("env",
native_symbols, n_native_symbols))
return false;
#endif /* WASM_ENABLE_LIBC_EMCC */
return true;
}register_natives
Regestered functions are organized as a linked list, each module holds several functions imported from a specific library:
typedef struct NativeSymbolsNode {
struct NativeSymbolsNode *next;
const char *module_name;
NativeSymbol *native_symbols;
uint32 n_native_symbols;
bool call_conv_raw;
} NativeSymbolsNode, *NativeSymbolsList;static bool
register_natives(const char *module_name,
NativeSymbol *native_symbols,
uint32 n_native_symbols,
bool call_conv_raw)
{
NativeSymbolsNode *node;
#if ENABLE_SORT_DEBUG != 0
struct timeval start;
struct timeval end;
unsigned long timer;
#endif
if (!(node = wasm_runtime_malloc(sizeof(NativeSymbolsNode))))
return false;
#if WASM_ENABLE_MEMORY_TRACING != 0
os_printf("Register native, size: %u\n", sizeof(NativeSymbolsNode));
#endif
node->module_name = module_name;
node->native_symbols = native_symbols;
node->n_native_symbols = n_native_symbols;
node->call_conv_raw = call_conv_raw;
/* Add to list head */
node->next = g_native_symbols_list;
g_native_symbols_list = node;
#if ENABLE_SORT_DEBUG != 0
gettimeofday(&start, NULL);
#endif
#if ENABLE_QUICKSORT == 0
sort_symbol_ptr(native_symbols, n_native_symbols);
#else
quick_sort_symbols(native_symbols, 0, (int)(n_native_symbols - 1));
#endif
#if ENABLE_SORT_DEBUG != 0
gettimeofday(&end, NULL);
timer = 1000000 * (end.tv_sec - start.tv_sec)
+ (end.tv_usec - start.tv_usec);
LOG_ERROR("module_name: %s, nums: %d, sorted used: %ld us",
module_name, n_native_symbols, timer);
#endif
return true;
}Twine: An Embedded Trusted Runtime for WebAssembly
WebAssembly is an increasingly popular lightweight binary instruction format, which can be efficiently embedded and sandboxed. Languages like C, C++, Rust, Go, and many others can be compiled into WebAssembly. This paper describes Twine, a WebAssembly trusted runtime designed to execute unmodified, language-independent applications. We leverage Intel SGX to build the runtime environment without dealing with language-specific, complex APIs. While SGX hardware provides secure execution within the processor, Twine provides a secure, sandboxed software runtime nested within an SGX enclave, featuring a WebAssembly system interface (WASI) for compatibility with unmodified WebAssembly applications. We evaluate Twine with a large set of general-purpose benchmarks and real-world applications. In particular, we used Twine to implement a secure, trusted version of SQLite, a well-known full-fledged embeddable database. We believe that such a trusted database would be a reasonable component to build many larger application services. Our evaluation shows that SQLite can be fully executed inside an SGX enclave via WebAssembly and existing system interface, with similar average performance overheads. We estimate that the performance penalties measured are largely compensated by the additional security guarantees and its full compatibility with standard WebAssembly. An in-depth analysis of our results indicates that performance can be greatly improved by modifying some of the underlying libraries. We describe and implement one such modification in the paper, showing up to 4.1× speedup. Twine is open-source, available at GitHub along with instructions to reproduce our experiments.
- 1st General purpose WASM runtime in SGX enclave?
- Support SQLite
- Implemented PF
爲什麽他可以發頂會?
Resources
- Mozillla Document more about how to use (in web)
- WA Community more about language itself (specification)
- Online Compilier
- Micro Runtime
- Design Document
Using LLM (GPT3.5) to discover logic bugs in smart contracts
Questions
- How to reduce false positives? Vulnerability confirmation.
- Does
temperature = 0really increase reliability? To my understanding, it just makes the answer deterministic. They do “mimic-in-thebackground” prompting, is that a good method? Any evaluations? - How are the Filtering Types determined for different types of vulnerabilities?
Highlights
Importance of Logic Vulnerabilities
The third group of vulnerabilities requires highlevel semantical oracles for detection and is closely related to the business logic. Most of these vulnerabilities are not detectable by existing static analysis tools. This group comprises six main types of vulnerabilities: (S1) price manipulation, (S2) ID-related violations, (S3) erroneous state updates, (S4) atomicity violation, (S5) privilege escalation, and (S6) erroneous accounting.
Use of Cheaper GPT-3.5
Methodology

Challenges
- Big code base cannot be directly feed into GPT as a whole => narrow down the scope
Can we break down vulnerability types in a manner that allows GPT, as a generic and intelligent code understanding tool, to recognize them directly from code-level semantics?
- Unreliable answers (FP?) => confirm vulnerabilities
Some Gadgets
GPT's Disadvantages (may not be general to LLMs)
However, we found that GPT struggles to comprehend the concept of “before,”
Missing Context Can Cause FP
For these two types, the main reason for the false alarms is that these vulnerabilities require specific triggering conditions involving other related logic, which may not be contained within a single function and its callers or callees.
New Vulnerabilities
GPTScan successfully discovered 9 vulnerabilities from 3 different types, which did not appear in the audit reports of Code4rena
GPT4
We also conducted a preliminary test using GPT-4, but we did not observe a notable improvement, while the cost increased 20 times.
Prompts
Prompt for scenario and property matching
System: You are a smart contract auditor. You will be asked questions related to code properties. You can mimic answering them in the background five times and provide me with the most frequently appearing answer. Furthermore, please strictly adhere to the output format specified in the question; there is no need to explain your answer.
Scenario Matching
Given the following smart contract code, answer the questions below and organize the result in a json format like {"1": "Yes" or "No", "2": "Yes" or "No"}.
"1": [%SCENARIO_1%]?
"2": [%SCENARIO_2%]?
[%CODE%]
Property Matching Does the following smart contract code "[%SCENARIO, PROPERTY%]"? Answer only "Yes" or "No".
[%CODE%]
Prompt for finding related variables/statements.
In this function, which variable holds the value of total minted share or amount? Please answer in a section starts with "VariableA:". In this function, which variable or function holds the total supply/liquidity AND is used by the conditional branch to determine the supply/liquidity is 0? Please answer in a section starts with "VariableB:". In this function, which variable or function holds the value of the deposit/mint/add amount? Please answer in a section starts with "VariableC:". Please answer in the following json format: {"VariableA":{"Variable name":"Description"}, "VariableB":{"Variable name":"Description"}, "VariableC":{"Variable name":"Description"}}
[%CODE%]
Abstract
Why3 is the next generation of the Why software verification platform. Why3 clearly separates the purely logical specification part from generation of verification conditions for programs. This article focuses on the former part. Why3 comes with a new enhanced language of logical specification. It features a rich library of proof task transformations that can be chained to produce a suitable input for a large set of theorem provers, including SMT solvers, TPTP provers, as well as interactive proof assistants.
Methods
- Provide a logic system (with grammar)
- Can write theories (with grammar)
- Converter: to SMT formats
- Leverage other proof assistants (e.g., certificate in Coq)
Meta
Buy
Sleeves
Sleeve Size
- Card: 59 mm x 86 mm
- Inner: 60 mm x 87 mm
- Middle: 62 mm x 89mm
- Outer: 64.5 mm x 90 mm
Sellers
TCG box/cards/supplies
- Game Nerdz Official Products, CHEAPEST!, best for pre-order
- Over the Brick 和楼上一样没有税
- TCGPlayer 单收
- Shop4megastore
- Over the Brick
- Prodigy Games TCG 最好能配合一些优惠卷
- YETI Gaming
- TGG 争议不少
- Potomac Distribution 批發Sleeves的好去處
- Unplugged Games 不知道怎么样
Wholesales
- Muddleit 似乎很便宜,不过不好买
- http://www.wholesalegaming.biz/yugioh/ 还是不便宜啊
OCG box/supplies
Skill & Play
Blogs
- NTUCGM 臺大卡片游戲社團
- 小程序
Softwares
Abstract
WebAssembly (Wasm) is a platform-independent bytecode that offers both good performance and runtime isolation. To implement isolation, the compiler inserts safety checks when it compiles Wasm to native machine code. While this approach is cheap, it also requires trust in the compiler's correctness—trust that the compiler has inserted each necessary check, correctly formed, in each proper place. Unfortunately, subtle bugs in the Wasm compiler can break—and emph{have broken}—isolation guarantees. To address this problem, we propose verifying memory isolation of Wasm binaries post-compilation. We implement this approach in VeriWasm, a static offline verifier for native x86-64 binaries compiled from Wasm; we prove the verifier's soundness, and find that it can detect bugs with no false positives. Finally, we describe our deployment of VeriWasm at Fastly.